
主题
Pi-pods (@mariozechner/pi-pods) 源码详细解读
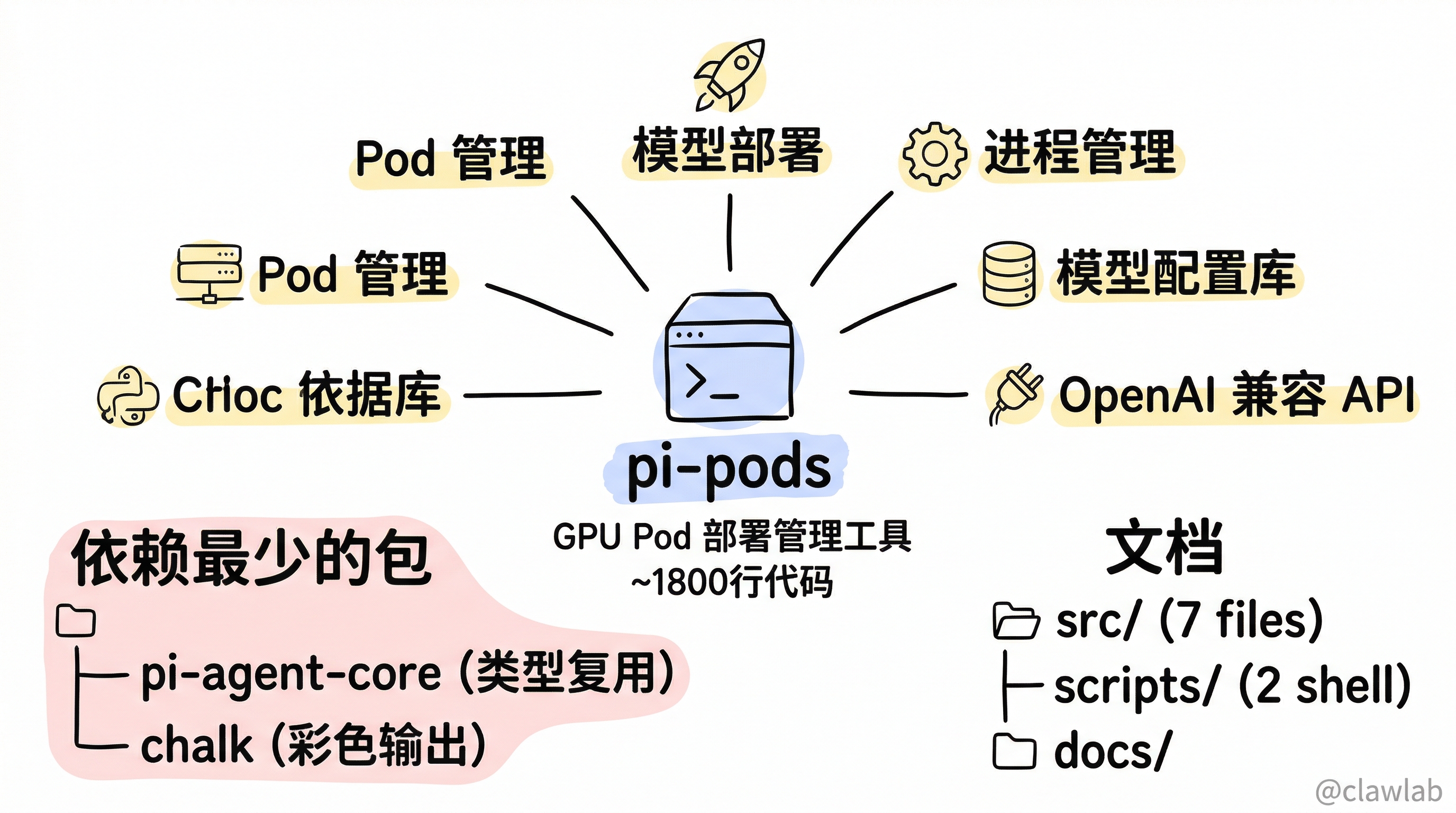
1. 包概述
@mariozechner/pi-pods 是 Pi Monorepo 中的 GPU Pod 部署管理工具,提供了一套 CLI 用于在远程 GPU 服务器上部署和管理 vLLM 模型服务。它将 GPU 服务器的复杂运维操作(环境搭建、模型下载、vLLM 启动、进程管理)封装为简洁的命令行接口。
1.1 核心职责
- Pod 管理:通过 SSH 连接远程 GPU 服务器,自动化环境搭建
- 模型部署:一键启动 vLLM 模型服务,自动选择 GPU、端口、配置参数
- 进程管理:启动/停止/监控远程 vLLM 进程
- 模型配置库:预置多个大模型的最优部署配置(GPU 数量、tensor parallelism、量化选项等)
- OpenAI 兼容 API:部署后提供标准 OpenAI API 端点
1.2 依赖关系
@mariozechner/pi-pods
├── @mariozechner/pi-agent-core (Agent 类型复用)
└── chalk (CLI 彩色输出)这是所有包中依赖最少的一个,几乎是独立工具。
1.3 文件结构
packages/pods/
├── src/
│ ├── cli.ts # CLI 入口和命令路由 (~360 行)
│ ├── index.ts # 公共导出(仅 types)
│ ├── config.ts # 配置管理 (~80 行)
│ ├── types.ts # 核心类型定义
│ ├── ssh.ts # SSH/SCP 通信层 (~151 行)
│ ├── model-configs.ts # 模型配置匹配逻辑 (~111 行)
│ ├── models.json # 预置模型配置数据库
│ └── commands/
│ ├── pods.ts # Pod 管理命令 (~205 行)
│ ├── models.ts # 模型管理命令 (~753 行)
│ └── prompt.ts # Agent 聊天命令 (~84 行)
├── scripts/
│ ├── pod_setup.sh # Pod 环境搭建脚本 (~200 行)
│ └── model_run.sh # 模型运行脚本 (~83 行)
├── docs/ # 模型研究文档
└── package.json总代码量约 1800 行(TypeScript + Shell),是所有包中最小的。
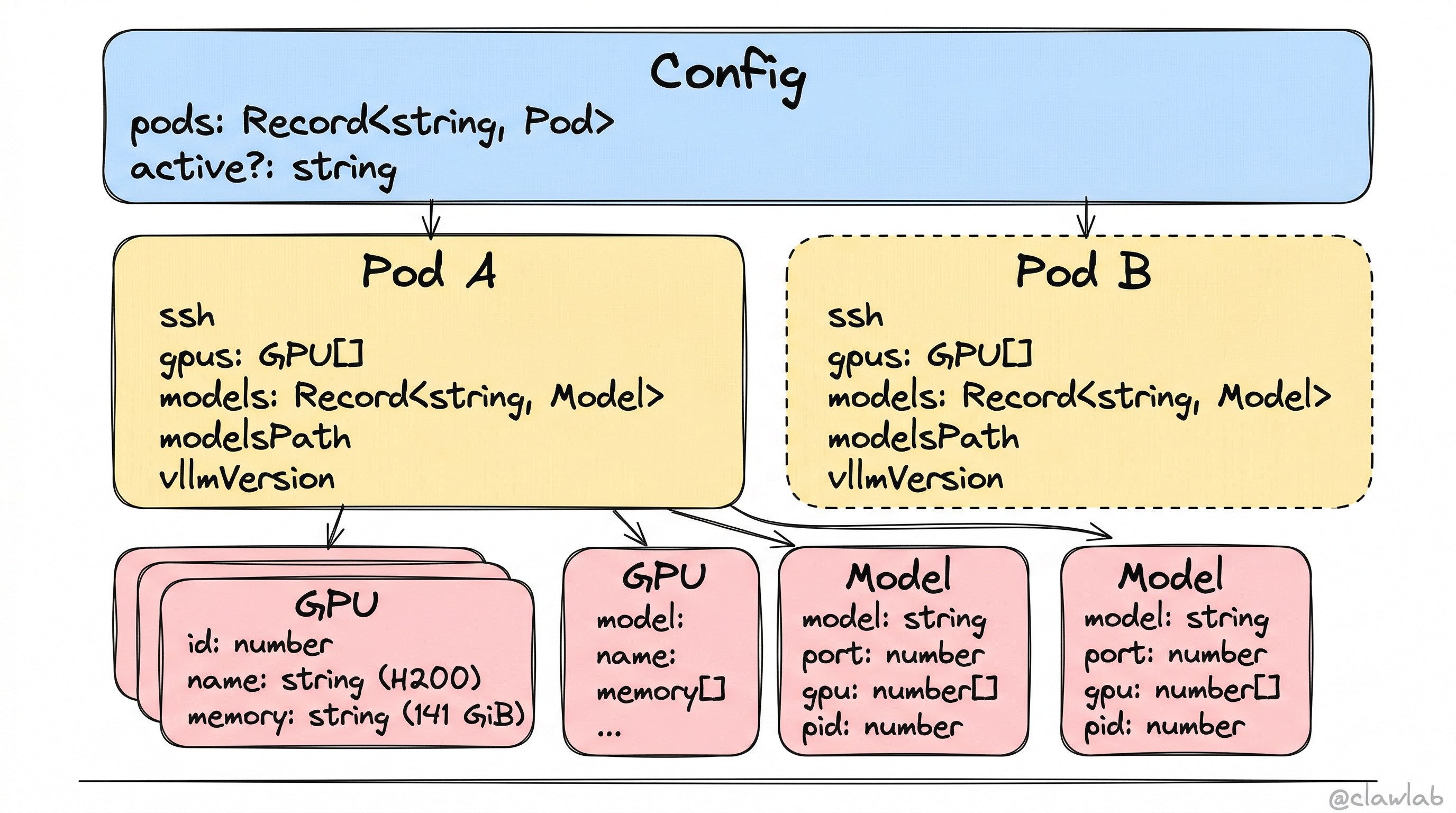
2. 核心类型(types.ts)
typescript
export interface GPU {
id: number; // GPU 索引(0, 1, 2...)
name: string; // 型号名称(如 "NVIDIA H200")
memory: string; // 显存大小(如 "141 GiB")
}
export interface Model {
model: string; // HuggingFace 模型 ID
port: number; // vLLM 服务端口
gpu: number[]; // 使用的 GPU ID 列表
pid: number; // 远程进程 PID
}
export interface Pod {
ssh: string; // SSH 连接命令(如 "ssh root@1.2.3.4")
gpus: GPU[]; // 检测到的 GPU 列表
models: Record<string, Model>; // 已部署模型(按名称索引)
modelsPath?: string; // 模型存储路径
vllmVersion?: "release" | "nightly" | "gpt-oss"; // vLLM 版本
}
export interface Config {
pods: Record<string, Pod>; // 所有 Pod(按名称索引)
active?: string; // 当前活跃 Pod 名称
}数据结构非常直观:Config 包含多个 Pod,每个 Pod 包含多个 GPU 和多个已部署的 Model。
3. 配置管理(config.ts)
3.1 存储位置
~/.pi/pods.json (默认)
$PI_CONFIG_DIR/pods.json (可通过环境变量覆盖)3.2 API
| 函数 | 说明 |
|---|---|
loadConfig() | 读取 pods.json,不存在则返回空配置 |
saveConfig(config) | 写入 pods.json(格式化 JSON) |
getActivePod() | 获取当前活跃 Pod |
addPod(name, pod) | 添加 Pod(如果没有活跃 Pod,自动设为活跃) |
removePod(name) | 移除 Pod(如果是活跃 Pod,清除活跃状态) |
setActivePod(name) | 切换活跃 Pod |
所有操作都是同步文件读写,简单直接。
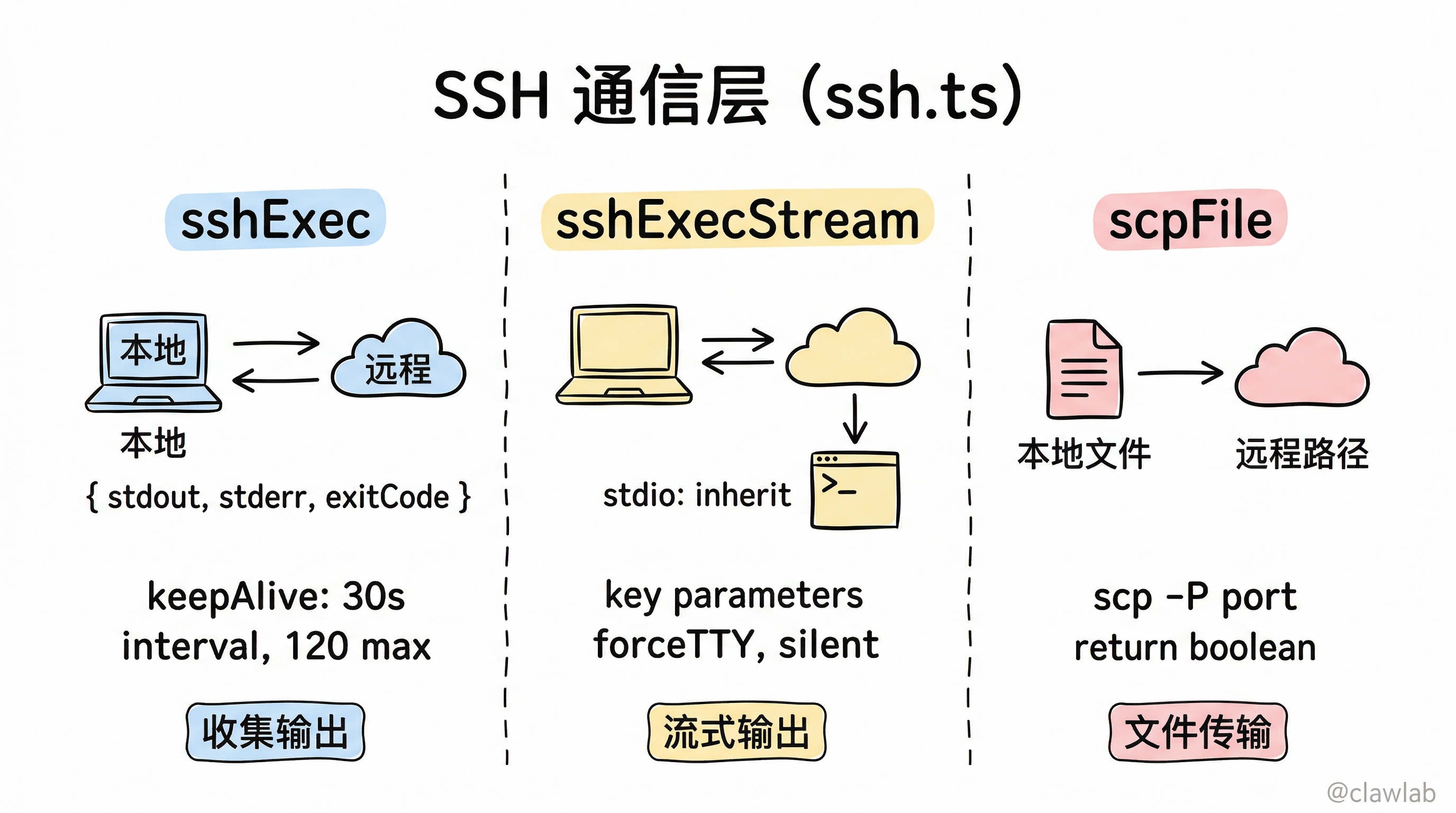
4. SSH 通信层(ssh.ts)
提供三个核心函数:
4.1 sshExec —— 命令执行(收集输出)
typescript
async sshExec(sshCmd, command, options?): Promise<SSHResult>- 解析 SSH 命令字符串(如
"ssh -p 22 root@1.2.3.4"→ssh+[-p, 22, root@1.2.3.4]) - 可选
keepAlive:添加ServerAliveInterval=30和ServerAliveCountMax=120(防止长命令断连,最多保活 60 分钟) - 收集 stdout/stderr 为字符串,返回
{ stdout, stderr, exitCode }
4.2 sshExecStream —— 命令执行(流式输出)
typescript
async sshExecStream(sshCmd, command, options?): Promise<number>stdio: "inherit"直接接管终端(实时显示远程输出)- 可选
forceTTY:添加-t参数(保留远程颜色输出) - 可选
silent:完全静默执行 - 返回退出码
4.3 scpFile —— 文件传输
typescript
async scpFile(sshCmd, localPath, remotePath): Promise<boolean>从 SSH 命令中提取 host 和 port,构建 scp -P port localPath host:remotePath 命令。
5. Pod 管理命令(commands/pods.ts)
5.1 pi pods setup —— 完整的 Pod 搭建流程
pi pods setup <name> "<ssh>" --mount "<mount>" [--vllm release|nightly|gpt-oss]
│
├── 1. 验证环境变量
│ ├── HF_TOKEN(HuggingFace 模型下载认证)
│ └── PI_API_KEY(vLLM API 认证密钥)
│
├── 2. 测试 SSH 连接
│ └── sshExec(sshCmd, "echo 'SSH OK'")
│
├── 3. 上传 setup 脚本
│ └── scpFile(sshCmd, pod_setup.sh, /tmp/pod_setup.sh)
│
├── 4. 执行远程搭建
│ └── sshExecStream(sshCmd, "bash /tmp/pod_setup.sh --models-path ... --hf-token ... --vllm ...")
│ 搭建内容:
│ ├── apt install 系统依赖
│ ├── 安装匹配版本的 CUDA Toolkit
│ ├── 创建 Python venv
│ ├── pip install vLLM(release / nightly / gpt-oss 三种版本)
│ ├── pip install hf-transfer(加速模型下载)
│ ├── 配置 HuggingFace Token
│ └── 执行挂载命令(如 NFS 网络存储)
│
├── 5. 检测 GPU
│ └── sshExec(sshCmd, "nvidia-smi --query-gpu=index,name,memory.total --format=csv,noheader")
│ 解析输出为 GPU[] 数组
│
└── 6. 保存配置
└── addPod(name, { ssh, gpus, models: {}, modelsPath, vllmVersion })5.2 pod_setup.sh —— 远程搭建脚本
Shell 脚本在远程 GPU 服务器上执行:
bash
# 核心步骤(简化)
apt install python3-pip python3-venv git build-essential cmake ...
# 安装匹配 CUDA 驱动的 Toolkit
nvidia-smi → 获取 CUDA 版本 → apt install cuda-toolkit-XX-X
# 创建 Python 虚拟环境
python3 -m venv /root/venv
# 安装 vLLM
pip install vllm>=0.10.0 # release
# 或 pip install vllm --pre # nightly
# 或 pip install vllm==0.10.1 + PyTorch nightly # gpt-oss
# 安装加速下载
pip install hf-transfer
# 配置 HuggingFace
huggingface-cli login --token $HF_TOKEN
# 挂载存储(可选)
eval "$MOUNT_COMMAND"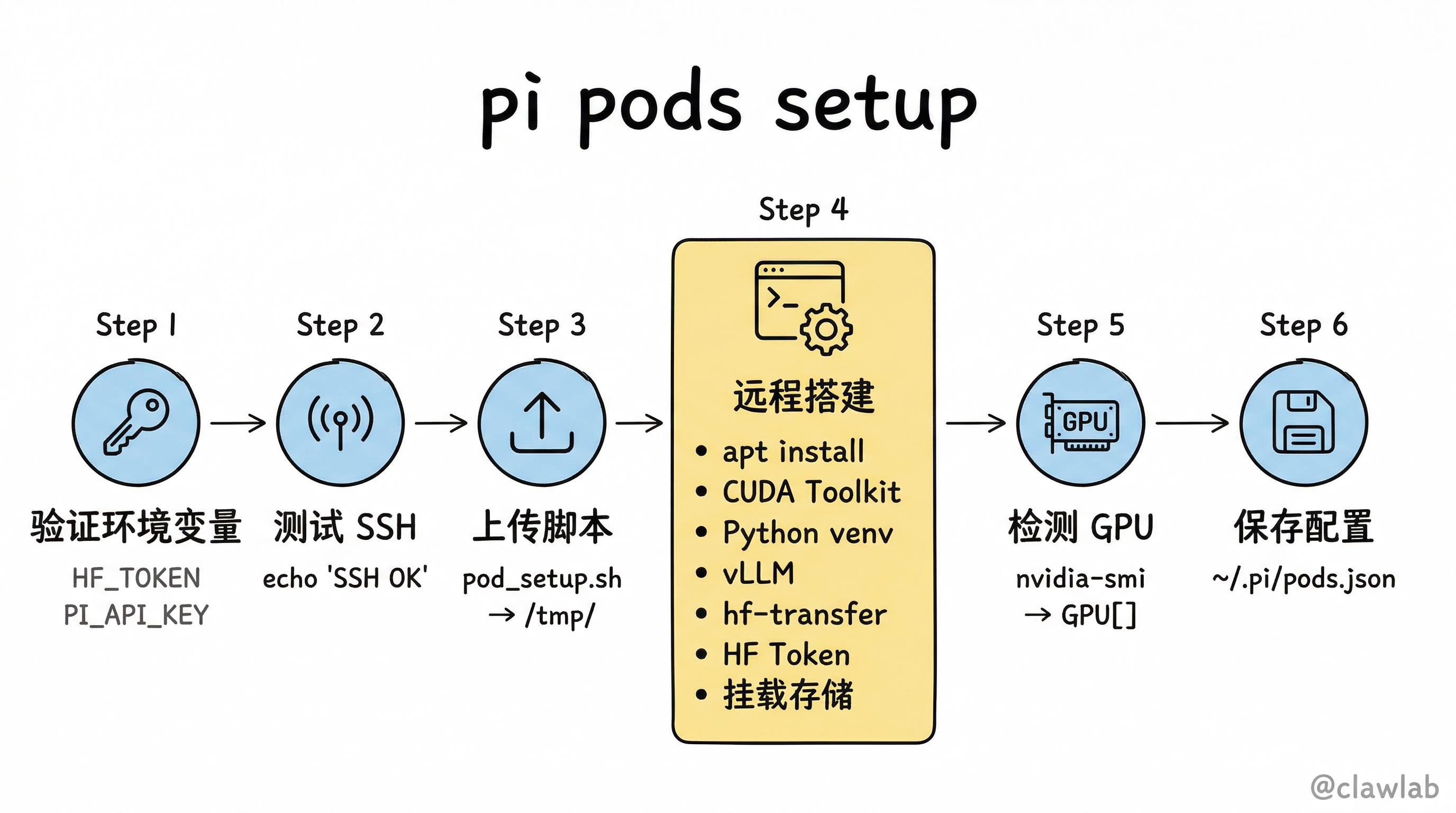
6. 模型管理命令(commands/models.ts)
6.1 pi start —— 模型部署核心流程
pi start <model> --name <name> [--memory 90%] [--context 32k] [--gpus 2]
│
├── 1. 获取目标 Pod(active 或 --pod 指定)
│
├── 2. 分配端口
│ └── getNextPort(pod) → 从 8001 开始,跳过已占用端口
│
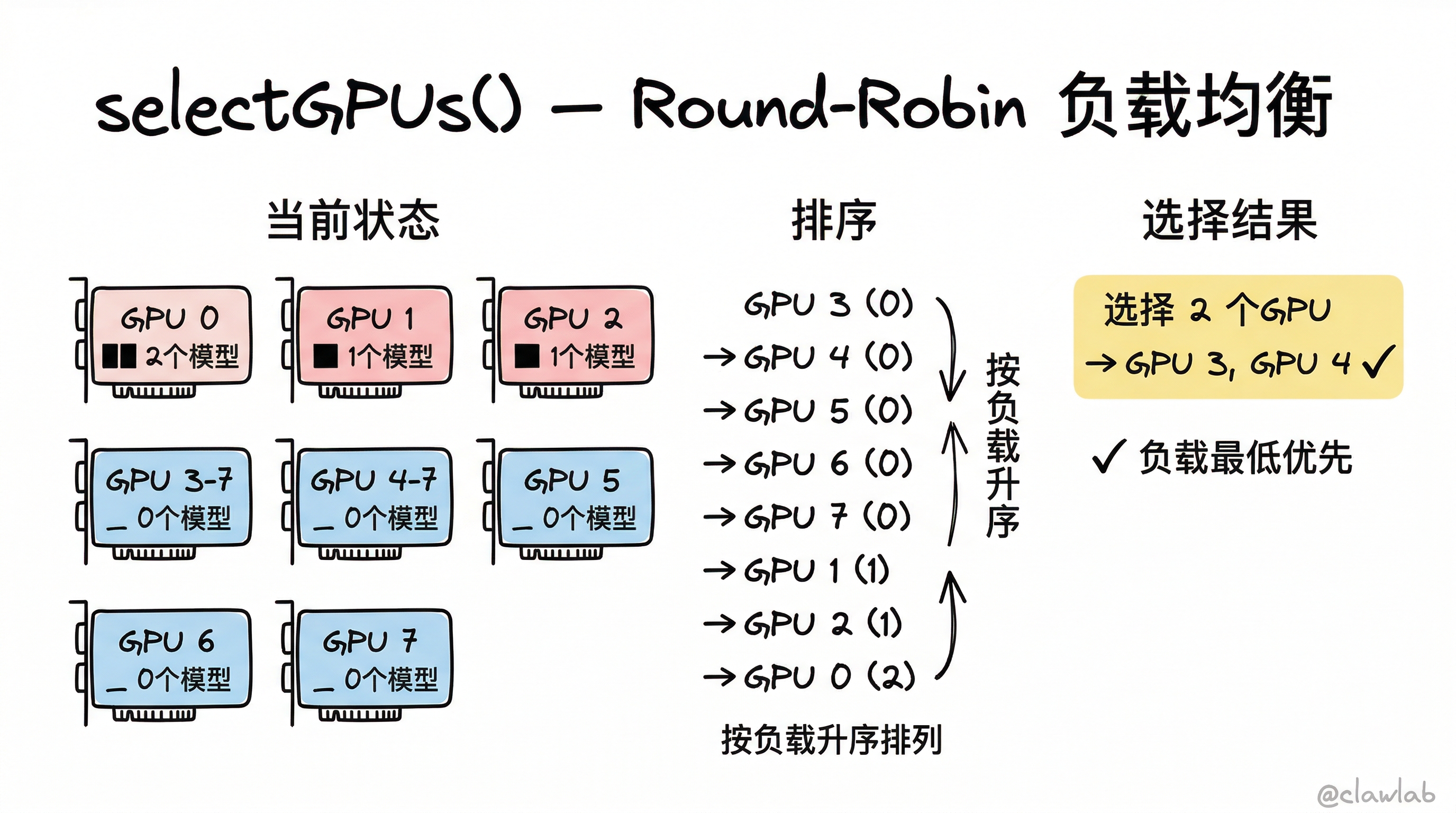
├── 3. 分配 GPU
│ └── selectGPUs(pod, count)
│ ├── 统计每个 GPU 的当前负载(已部署模型数)
│ ├── 按负载升序排列
│ └── 选择负载最低的 N 个 GPU
│
├── 4. 解析 vLLM 参数
│ ├── 已知模型 → getModelConfig(modelId, gpus, gpuCount) → 预置参数
│ │ ├── 匹配 GPU 数量
│ │ ├── 匹配 GPU 型号(H100/H200)
│ │ └── 返回 { args, env, notes }
│ ├── 未知模型 → 默认单 GPU
│ └── --memory / --context → 覆盖预置参数
│
├── 5. 准备运行脚本
│ ├── 读取 model_run.sh 模板
│ ├── 替换占位符({{MODEL_ID}}, {{NAME}}, {{PORT}}, {{VLLM_ARGS}})
│ └── 上传到远程 /tmp/model_run_<name>.sh
│
├── 6. 启动远程进程
│ ├── 设置环境变量(HF_TOKEN, PI_API_KEY, CUDA_VISIBLE_DEVICES 等)
│ ├── setsid 创建新会话(SSH 断开后进程存活)
│ ├── script 命令包装(保留颜色日志到 ~/.vllm_logs/<name>.log)
│ └── 返回 PID
│
├── 7. 实时监控启动日志
│ ├── tail -f ~/.vllm_logs/<name>.log → 流式输出
│ ├── 检测 "Application startup complete" → 成功
│ ├── 检测 "torch.OutOfMemoryError" → OOM 失败
│ ├── 检测 "Engine core initialization failed" → vLLM 失败
│ └── Ctrl+C → 停止监控(进程继续运行)
│
├── 8a. 成功 → 输出连接信息
│ ├── Base URL: http://host:port/v1
│ ├── Model: model-id
│ ├── Shell export 命令
│ └── curl / Python 使用示例
│
├── 8b. 失败 → 清理并报错
│ ├── 从配置中删除失败的模型
│ └── 根据失败原因给出建议
│
└── 9. 保存配置
└── config.pods[podName].models[name] = { model, port, gpu, pid }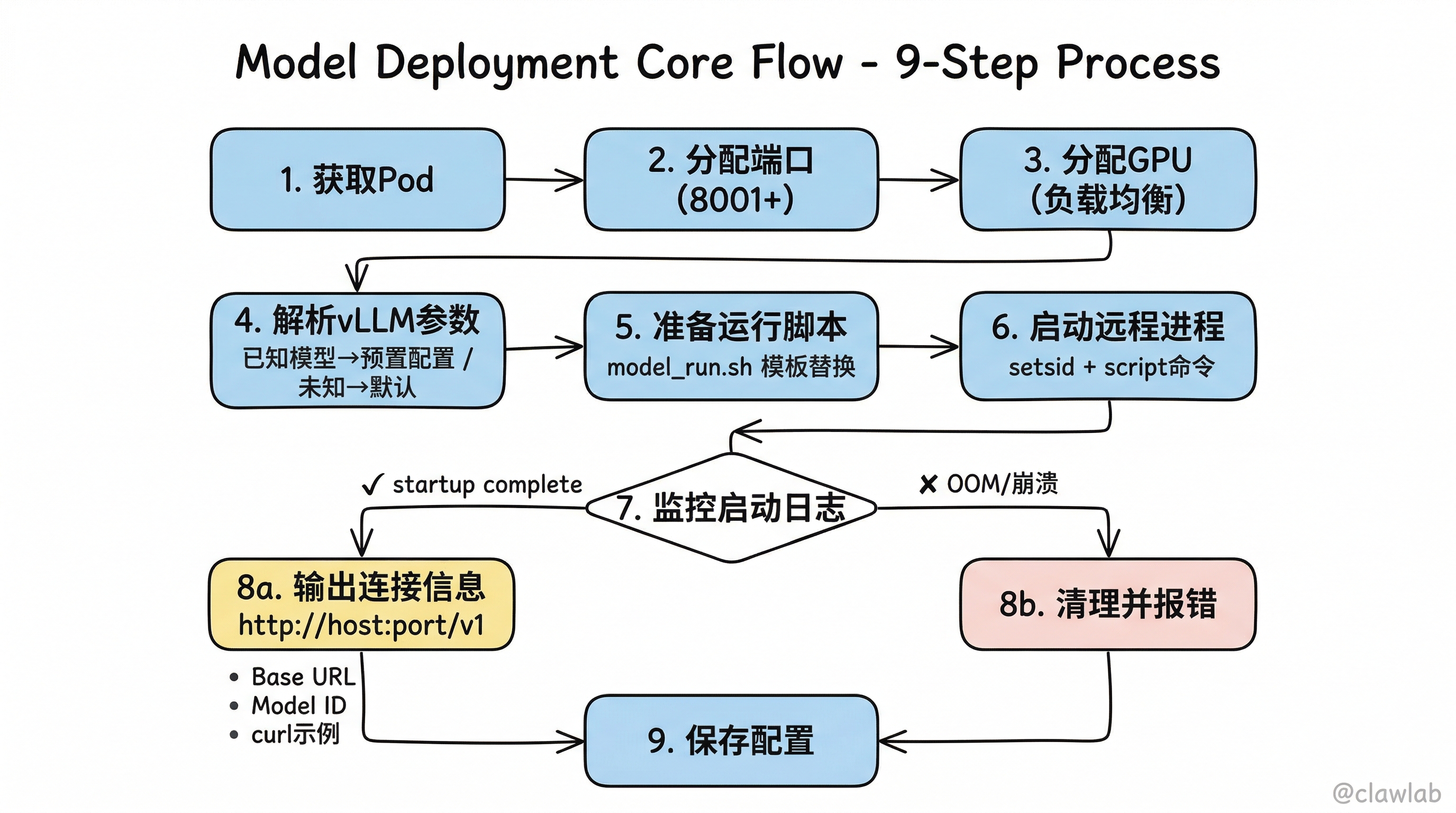
6.2 model_run.sh —— 模型运行脚本
bash
# 在远程 GPU 服务器上执行
source /root/venv/bin/activate
# 下载模型(使用 hf-transfer 加速,已缓存则跳过)
HF_HUB_ENABLE_HF_TRANSFER=1 hf download "$MODEL_ID"
# 启动 vLLM 服务
vllm serve "$MODEL_ID" --port $PORT --api-key "$PI_API_KEY" $VLLM_ARGS
# 信号处理:TERM/INT → 清理子进程
trap cleanup EXIT TERM INT6.3 GPU 分配策略:Round-Robin 负载均衡
typescript
const selectGPUs = (pod, count = 1): number[] => {
if (count === pod.gpus.length) return pod.gpus.map(g => g.id);
const gpuUsage = new Map<number, number>();
for (const gpu of pod.gpus) gpuUsage.set(gpu.id, 0);
for (const model of Object.values(pod.models)) {
for (const gpuId of model.gpu) {
gpuUsage.set(gpuId, (gpuUsage.get(gpuId) || 0) + 1);
}
}
return Array.from(gpuUsage.entries())
.sort((a, b) => a[1] - b[1]) // 负载最低优先
.map(e => e[0])
.slice(0, count);
};
6.4 pi stop —— 进程终止
typescript
export const stopModel = async (name, options) => {
const killCmd = `
pkill -TERM -P ${model.pid} 2>/dev/null || true
kill ${model.pid} 2>/dev/null || true
`;
await sshExec(pod.ssh, killCmd);
// 从配置中删除
};使用 pkill -P 杀死进程及其所有子进程,然后 kill 主进程。
6.5 pi list —— 状态检查
listModels()
├── 显示所有模型信息(名称、端口、GPU、PID、URL)
└── 远程验证进程状态
├── ps -p PID → 进程存在?
├── curl http://localhost:PORT/health → vLLM 健康?
└── tail 日志检查 → 是否崩溃?
→ 状态:running / starting / crashed / dead6.6 pi logs —— 日志流
typescript
const tailCmd = `tail -f ~/.vllm_logs/${name}.log`;
spawn(sshCommand, [...sshArgs, tailCmd], { stdio: "inherit" });通过 SSH tail -f 实时流式传输远程日志到本地终端。
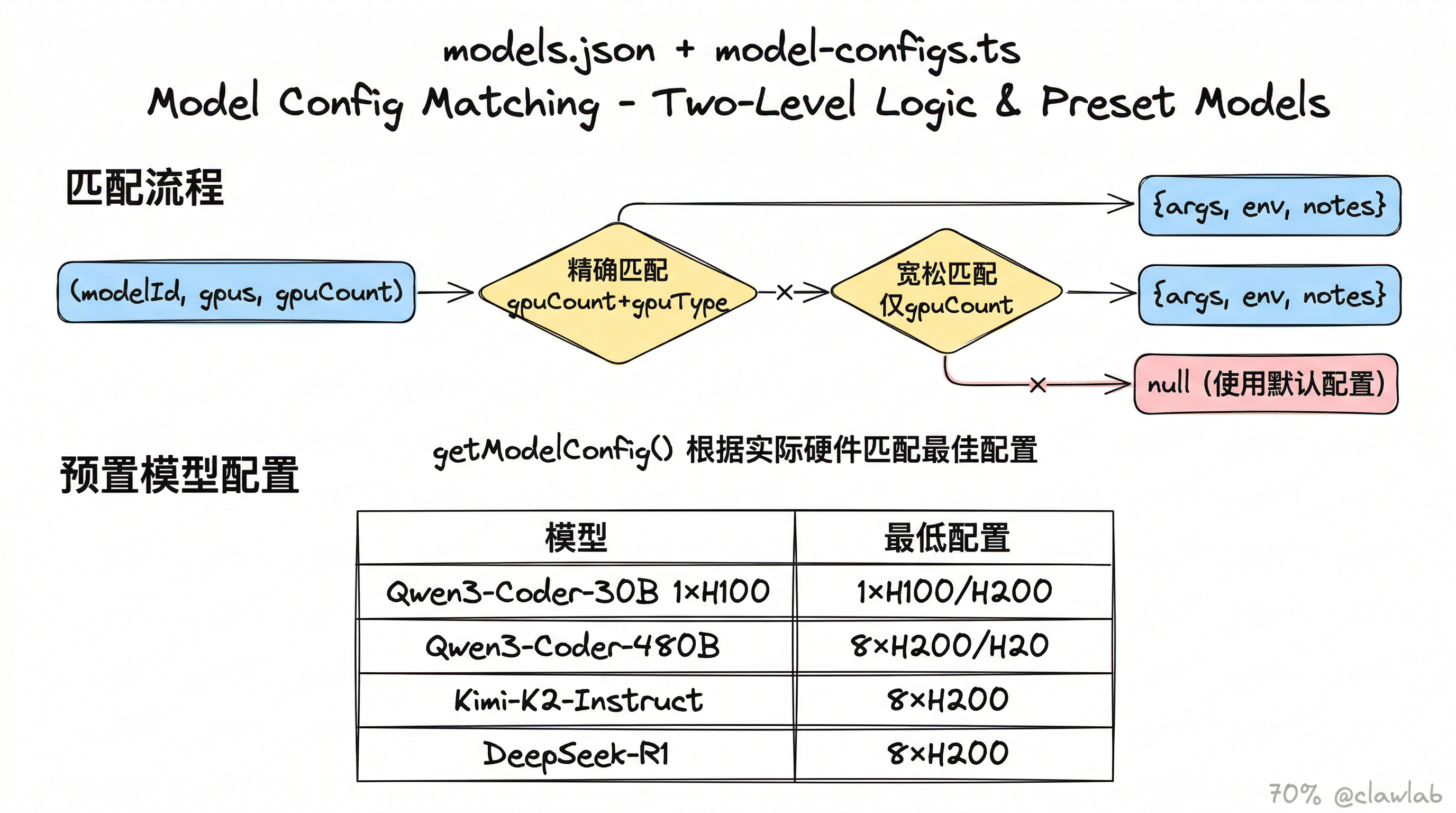
7. 模型配置库(model-configs.ts + models.json)
7.1 配置结构
json
{
"models": {
"Qwen/Qwen3-Coder-30B-A3B-Instruct": {
"name": "Qwen3-Coder-30B",
"configs": [
{
"gpuCount": 1,
"gpuTypes": ["H100", "H200"],
"args": ["--enable-auto-tool-choice", "--tool-call-parser", "qwen3_coder"]
},
{
"gpuCount": 2,
"gpuTypes": ["H100", "H200"],
"args": ["--tensor-parallel-size", "2", "--enable-auto-tool-choice", "--tool-call-parser", "qwen3_coder"]
}
]
}
}
}每个模型可以有多个配置(不同 GPU 数量/型号),getModelConfig() 根据实际硬件匹配最佳配置。
7.2 匹配逻辑
getModelConfig(modelId, gpus, requestedGpuCount)
├── 1. 精确匹配:gpuCount + gpuType 都匹配
├── 2. 宽松匹配:只匹配 gpuCount(忽略 gpuType)
└── 返回 { args, env, notes } 或 null7.3 预置模型
| 模型 | 最低配置 | 说明 |
|---|---|---|
| Qwen2.5-Coder-32B | 1x H100/H200 | Hermes tool parser |
| Qwen3-Coder-30B | 1x H100/H200 | ~60GB weight |
| Qwen3-Coder-30B-FP8 | 1x H100/H200 | 量化版 ~30GB,DEEP_GEMM 加速 |
| Qwen3-Coder-480B | 8x H200/H20 | 需要限制 context 长度 |
| Qwen3-Coder-480B-FP8 | 8x H200/H20 | data-parallel 模式 |
| GPT-OSS-20B | 1x H100/H200 | 需要特殊 vLLM gpt-oss 构建 |
| Kimi-K2-Instruct | 8x H200 | 1T MoE 模型 |
| DeepSeek-R1 | 8x H200 | 推理模型 |
8. Agent 聊天命令(commands/prompt.ts)
pi agent <name> ["<message>"...] [options]promptModel() 函数:
- 获取 Pod 和模型配置
- 提取远程 Host 和 Port
- 构建 system prompt(代码导航助手)
- 组装
--base-url、--model、--api-key、--api参数 - 调用 pi-coding-agent 的 CLI
当前状态:throw new Error("Not implemented") —— 该功能尚未完成实现。
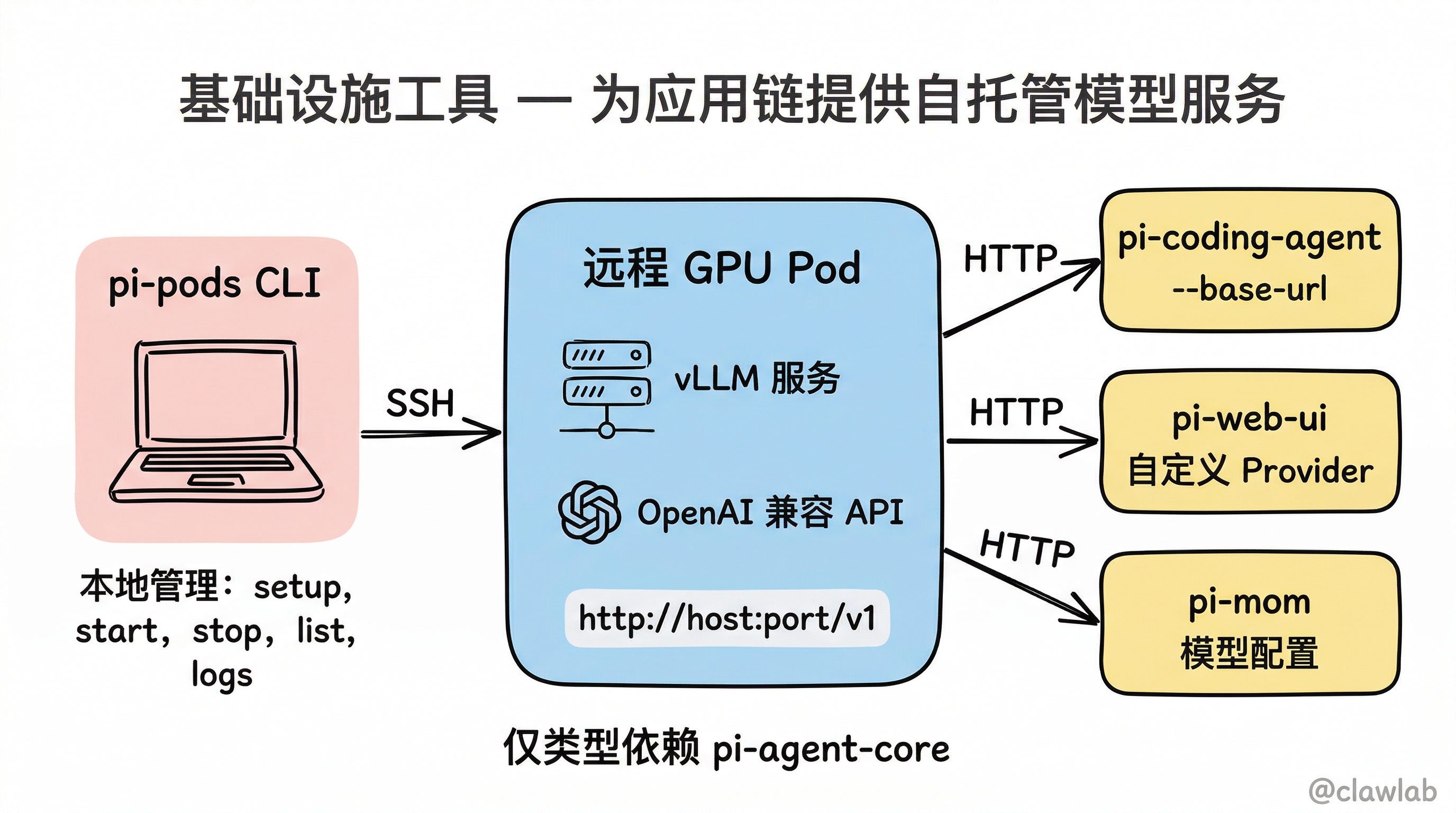
9. 与其他包的关系
@mariozechner/pi-agent-core (仅类型依赖)
│
▼
@mariozechner/pi-pods ← 本包
独立运行:
pi-pods CLI → SSH → 远程 GPU Pod
├── vLLM 服务
│ └── OpenAI 兼容 API (http://host:port/v1)
│
└── 被其他应用使用:
├── pi-coding-agent(--base-url 指向 Pod)
├── pi-web-ui(自定义 Provider)
└── pi-mom(模型配置)pi-pods 是一个基础设施工具,它不是 Pi AI 应用链的一部分,而是为应用链提供自托管模型服务。
10. 完整的部署流程示例
bash
# 1. 设置环境变量
export HF_TOKEN="hf_xxx"
export PI_API_KEY="my-secret-key"
# 2. 搭建 Pod
pi pods setup my-gpu "ssh root@1.2.3.4" --mount "mount -t nfs 10.0.0.1:/models /mnt/models"
# → 远程安装依赖、CUDA、vLLM、挂载存储
# → 检测 GPU(如 8x NVIDIA H200 141GiB)
# → 保存到 ~/.pi/pods.json
# 3. 部署模型
pi start Qwen/Qwen3-Coder-30B-A3B-Instruct --name qwen3
# → 自动匹配 1x H200 配置
# → 下载模型(HuggingFace → /mnt/models/)
# → 启动 vLLM 服务(port 8001, GPU 0)
# → 输出连接信息
# 4. 使用模型
curl http://1.2.3.4:8001/v1/chat/completions \
-H "Authorization: Bearer my-secret-key" \
-d '{"model":"Qwen/Qwen3-Coder-30B-A3B-Instruct","messages":[{"role":"user","content":"Hello!"}]}'
# 5. 部署更多模型
pi start Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 --name qwen3-fp8
# → 自动选择负载最低的 GPU(GPU 1)
# → port 8002
# 6. 管理
pi list # 列出所有模型 + 健康检查
pi logs qwen3 # 实时日志
pi stop qwen3 # 停止单个模型
pi stop # 停止所有模型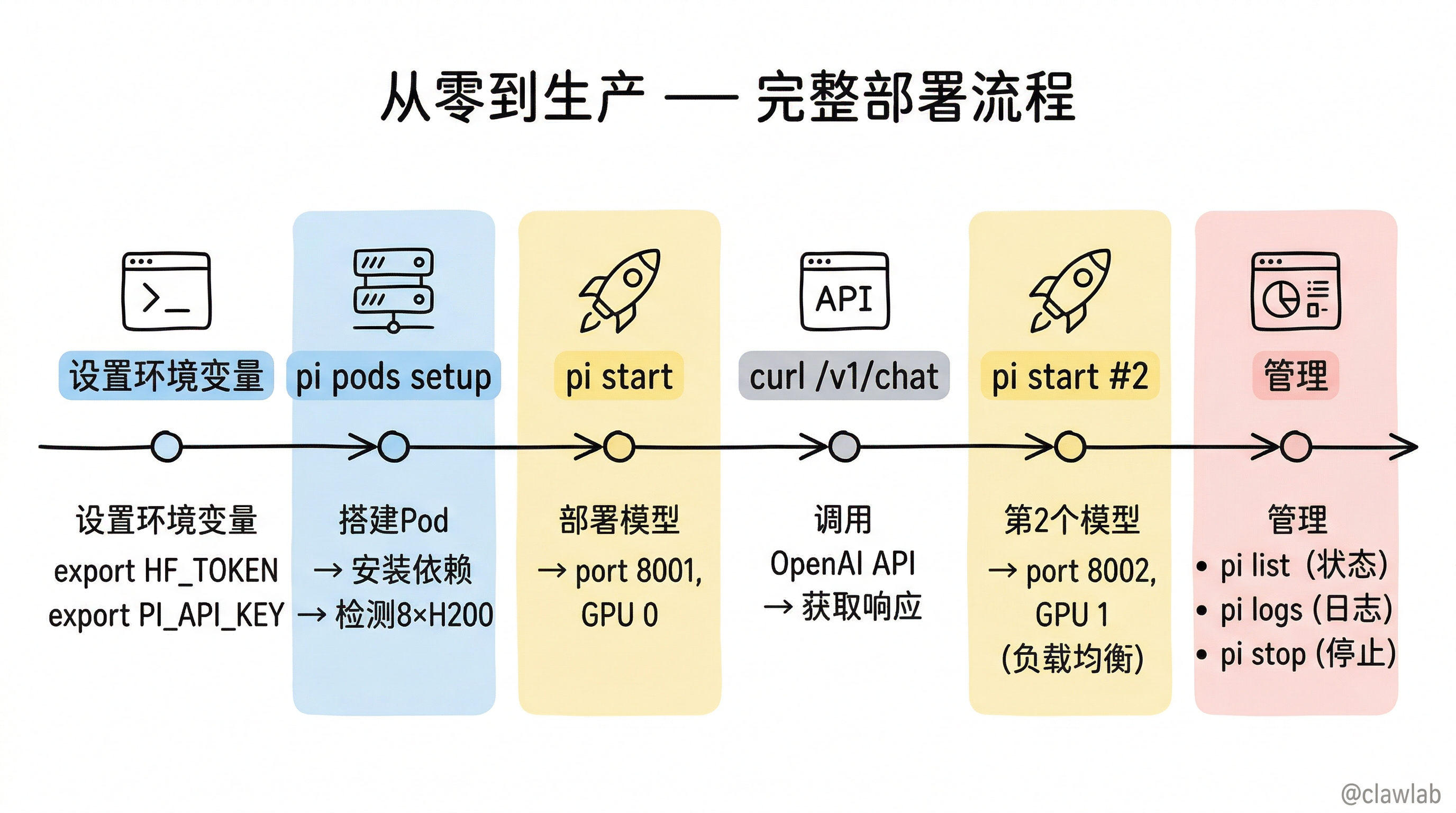
11. 源码阅读建议
推荐阅读顺序
- types.ts → 4 个核心类型(GPU, Model, Pod, Config),非常简单
- config.ts → 配置文件读写,理解数据持久化
- ssh.ts → SSH 通信抽象,理解远程执行机制
- cli.ts → 命令路由,理解 CLI 全貌
- commands/pods.ts 的
setupPod()→ Pod 搭建完整流程 - scripts/pod_setup.sh → 远程环境搭建的具体操作
- model-configs.ts → 模型配置匹配逻辑
- models.json → 预置模型参数参考
- commands/models.ts 的
startModel()→ 模型部署核心流程 - scripts/model_run.sh → 模型运行脚本
关键断点位置
| 文件 | 位置 | 说明 |
|---|---|---|
| cli.ts | switch (command) | 命令路由入口 |
| commands/pods.ts | setupPod() | Pod 搭建流程 |
| commands/models.ts | startModel() | 模型部署核心 |
| commands/models.ts | selectGPUs() | GPU 分配策略 |
| commands/models.ts | processOutput() | 启动日志监控 |
| commands/models.ts | listModels() 的 checkCmd | 远程健康检查 |
| model-configs.ts | getModelConfig() | 配置匹配 |
| ssh.ts | sshExec() | SSH 命令执行 |
核心设计思想总结
- SSH 为核心通信:所有远程操作通过 SSH 执行,无需远程代理进程
- Shell 脚本模板化:
model_run.sh使用占位符(),CLI 替换后上传执行 - setsid 进程分离:模型进程在 SSH 断开后继续运行
- Round-Robin GPU 分配:按负载自动选择最空闲的 GPU
- 配置驱动:
models.json预置最优参数,用户无需了解 vLLM 细节 - 状态持久化到本地:
~/.pi/pods.json记录所有 Pod 和模型状态 - OpenAI 兼容:部署后即可通过标准 OpenAI SDK 使用
- 失败检测:启动时实时监控日志,检测 OOM/崩溃并给出建议