
主题
04. 虚拟文件系统:代理的"数据仓库"
理解 DeepAgents 后端系统的设计理念
引言:为什么代理需要"文件系统"?
想象一个场景:你让 AI 代理帮你研究一个技术主题,它需要:
- 搜索并收集大量资料
- 整理和分析这些信息
- 撰写一份完整的报告
问题来了:LLM 的上下文窗口是有限的(比如 200K tokens)。如果搜索结果有 50 万字,怎么办?
传统方案的做法是:截断、丢弃、或者报错。
DeepAgents 的方案是:给代理一个"个人云盘"——虚拟文件系统。
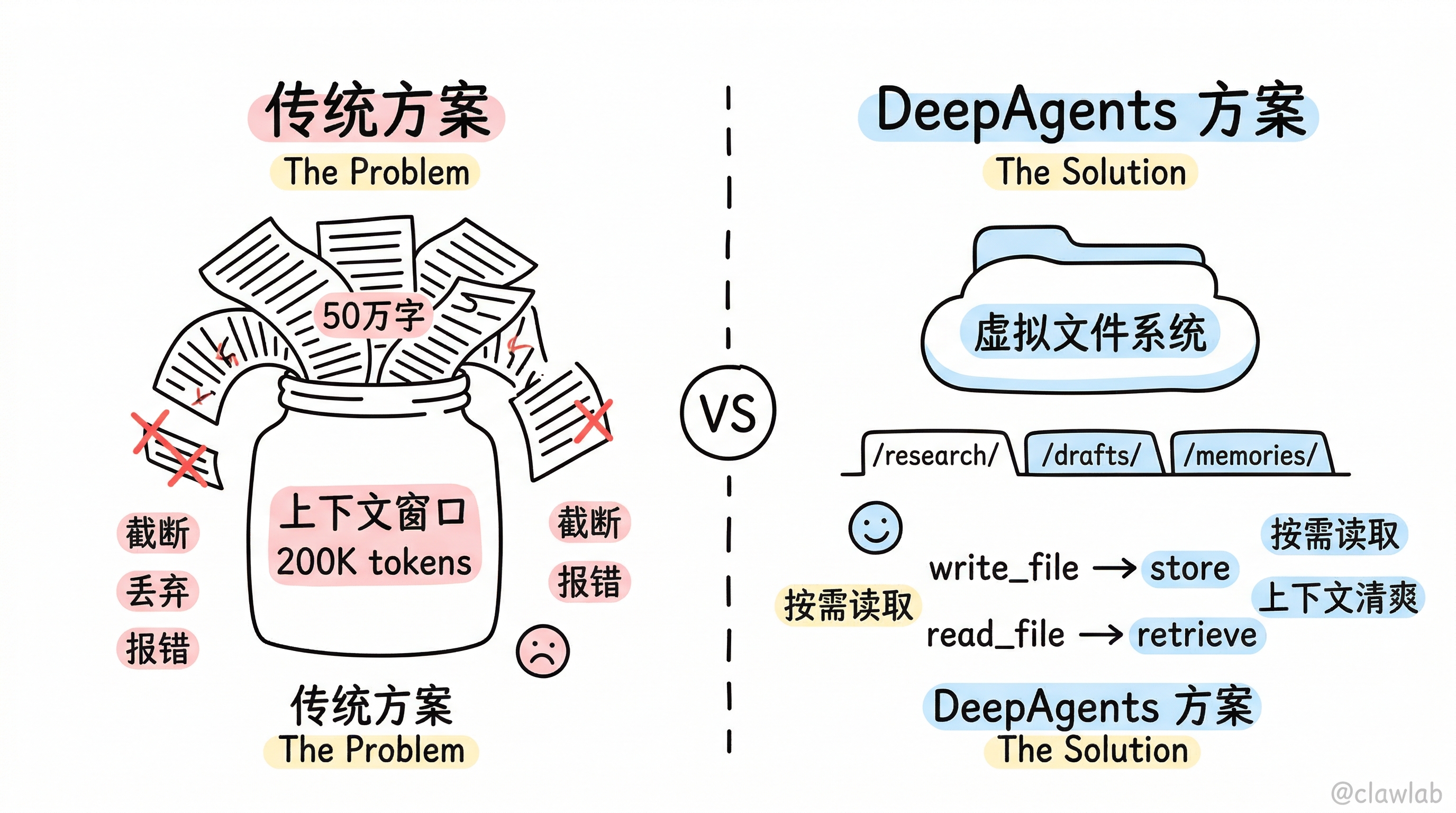
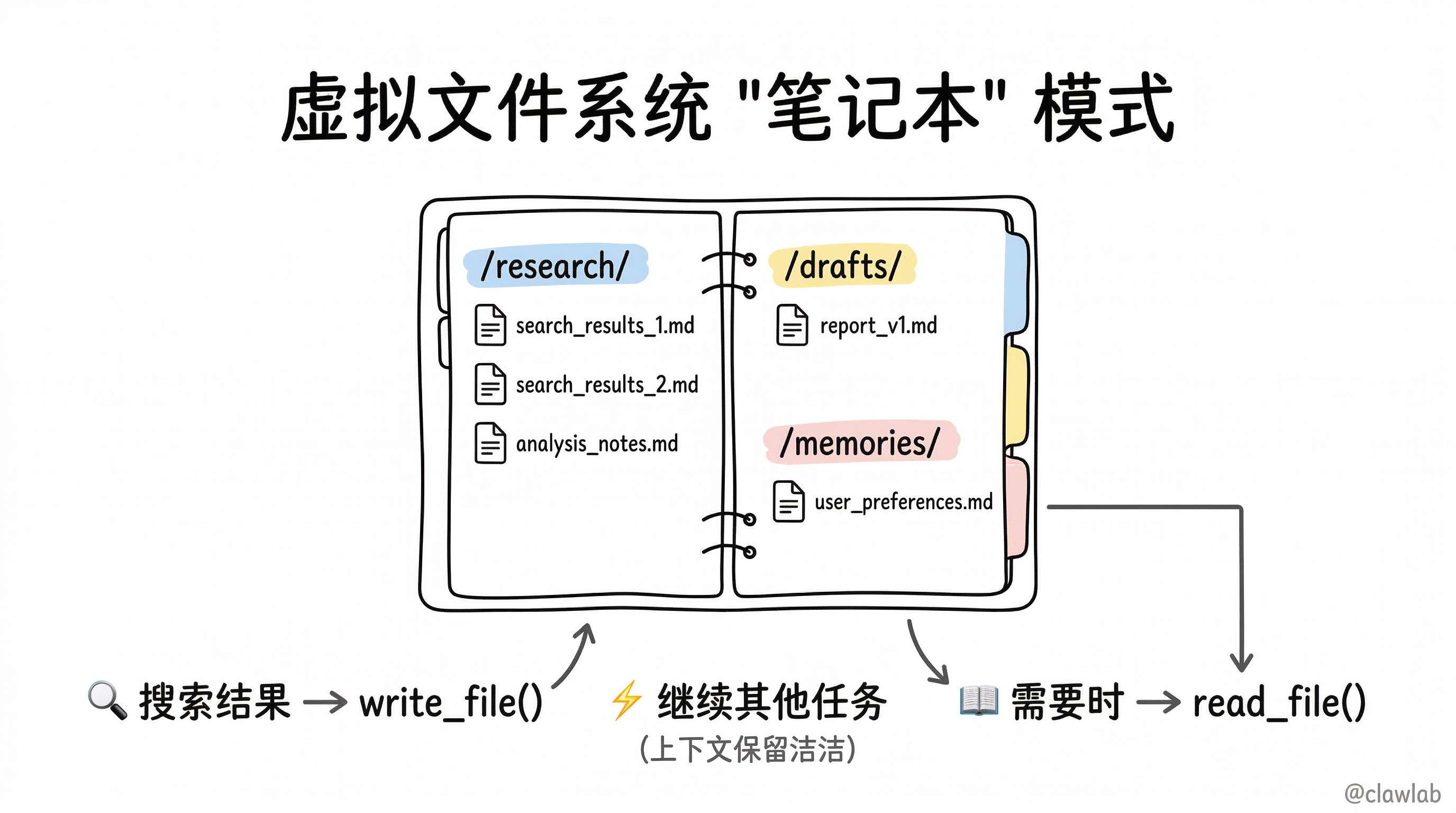
虚拟文件系统的核心理念
"笔记本"模式
DeepAgents 的虚拟文件系统就像研究员的笔记本:
┌─────────────────────────────────────────────────────────────┐
│ 虚拟文件系统 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ /research/ │ │
│ │ ├── search_results_1.md (搜索结果 1) │ │
│ │ ├── search_results_2.md (搜索结果 2) │ │
│ │ └── analysis_notes.md (分析笔记) │ │
│ │ /drafts/ │ │
│ │ └── report_v1.md (报告草稿) │ │
│ │ /memories/ │ │
│ │ └── user_preferences.md (用户偏好) │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘工作流程:
- 代理搜索得到大量结果 →
write_file("/research/results.md", ...) - 继续执行其他任务,上下文保持清爽
- 需要时再读取 →
read_file("/research/results.md")
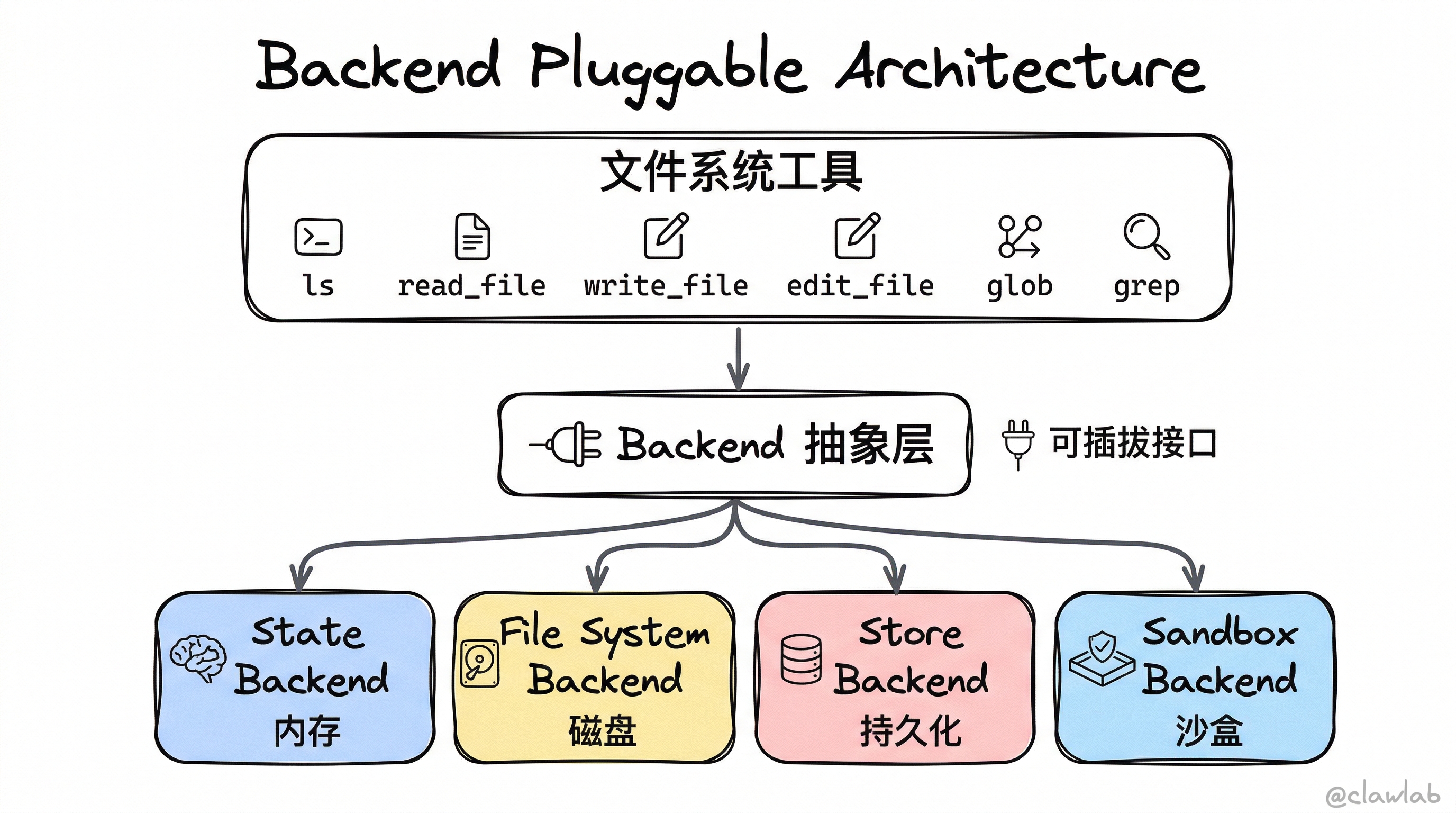
Backend 抽象层
虚拟文件系统的核心是 Backend(后端)抽象。不同的后端决定了文件"实际存储在哪里":
┌─────────────────┐
│ 文件系统工具 │
│ ls, read_file │
│ write_file... │
└────────┬────────┘
│
▼
┌─────────────────┐
│ Backend │ ← 可插拔接口
│ (抽象层) │
└────────┬────────┘
│
┌────┴────┬────────────┬──────────┐
▼ ▼ ▼ ▼
┌───────┐ ┌───────┐ ┌─────────┐ ┌─────────┐
│ State │ │ File │ │ Store │ │ Sandbox │
│Backend│ │System │ │ Backend │ │ Backend │
│(内存) │ │Backend│ │(持久化) │ │(沙盒) │
│ │ │(磁盘) │ │ │ │ │
└───────┘ └───────┘ └─────────┘ └─────────┘
六个核心文件系统工具
DeepAgents 提供六个文件系统工具,覆盖所有常见操作:
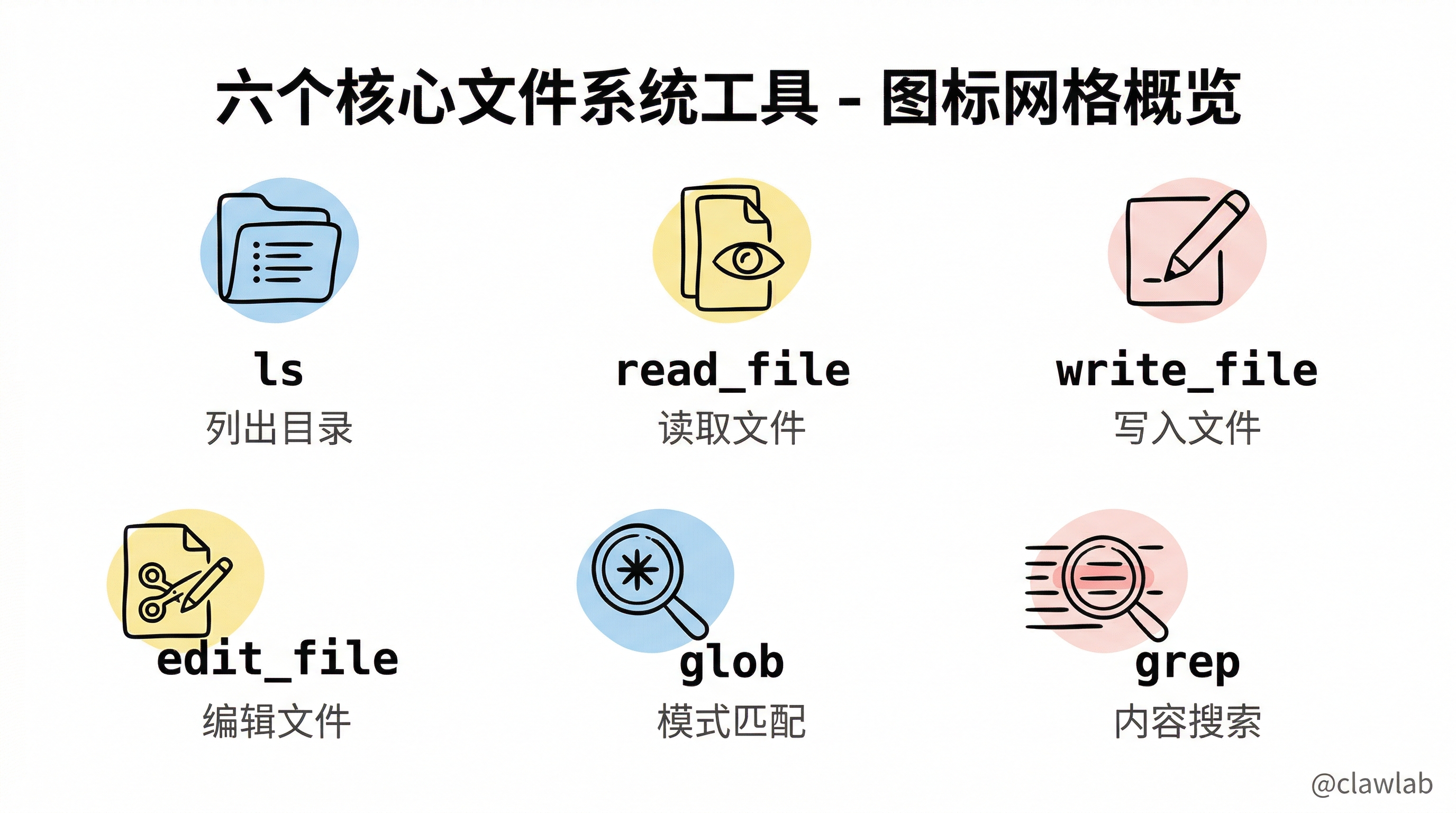
1. ls - 列出目录内容
typescript
// 代理调用
ls("/research")
// 返回结果
[
{ path: "/research/results.md", size: 15420, modified_at: "2024-01-15T10:30:00Z" },
{ path: "/research/notes.md", size: 2048, modified_at: "2024-01-15T11:00:00Z" },
]元数据字段:
path:文件路径is_dir:是否为目录size:文件大小(字节)modified_at:最后修改时间
2. read_file - 读取文件
typescript
// 基础读取
read_file("/research/results.md")
// 分段读取大文件(指定 offset 和 limit)
read_file("/research/large_data.md", { offset: 100, limit: 50 })
// 从第 100 行开始,读取 50 行特殊能力:支持读取图片文件(.png, .jpg, .jpeg, .gif, .webp),并以多模态内容块返回。
3. write_file - 写入文件
typescript
// 创建新文件
write_file("/drafts/report.md", "# 研究报告\n\n## 概述\n...")
// 返回结果
{ path: "/drafts/report.md", success: true }注意:write_file 只能创建新文件,不能覆盖已存在的文件。要修改文件,使用 edit_file。
4. edit_file - 编辑文件
typescript
// 精确字符串替换
edit_file("/drafts/report.md", {
old_string: "## 概述",
new_string: "## 执行摘要"
})
// 全局替换(replace_all: true)
edit_file("/drafts/report.md", {
old_string: "LangChain",
new_string: "DeepAgents",
replace_all: true
})设计考量:要求 old_string 在文件中唯一匹配(除非 replace_all: true),防止误修改。
5. glob - 模式匹配搜索文件
typescript
// 查找所有 Markdown 文件
glob("**/*.md")
// 查找特定目录下的 TypeScript 文件
glob("/src/**/*.ts")
// 返回匹配的文件列表
[
{ path: "/drafts/report.md" },
{ path: "/research/notes.md" },
]6. grep - 内容搜索
typescript
// 在所有文件中搜索关键词
grep("LangGraph", { path: "/" })
// 返回匹配结果
[
{ path: "/research/results.md", line: 15, text: "LangGraph 是一个状态管理框架..." },
{ path: "/research/results.md", line: 42, text: "...使用 LangGraph 构建工作流..." },
]输出模式:
- 默认:返回匹配的文件路径
content:返回匹配行的内容count:返回匹配数量
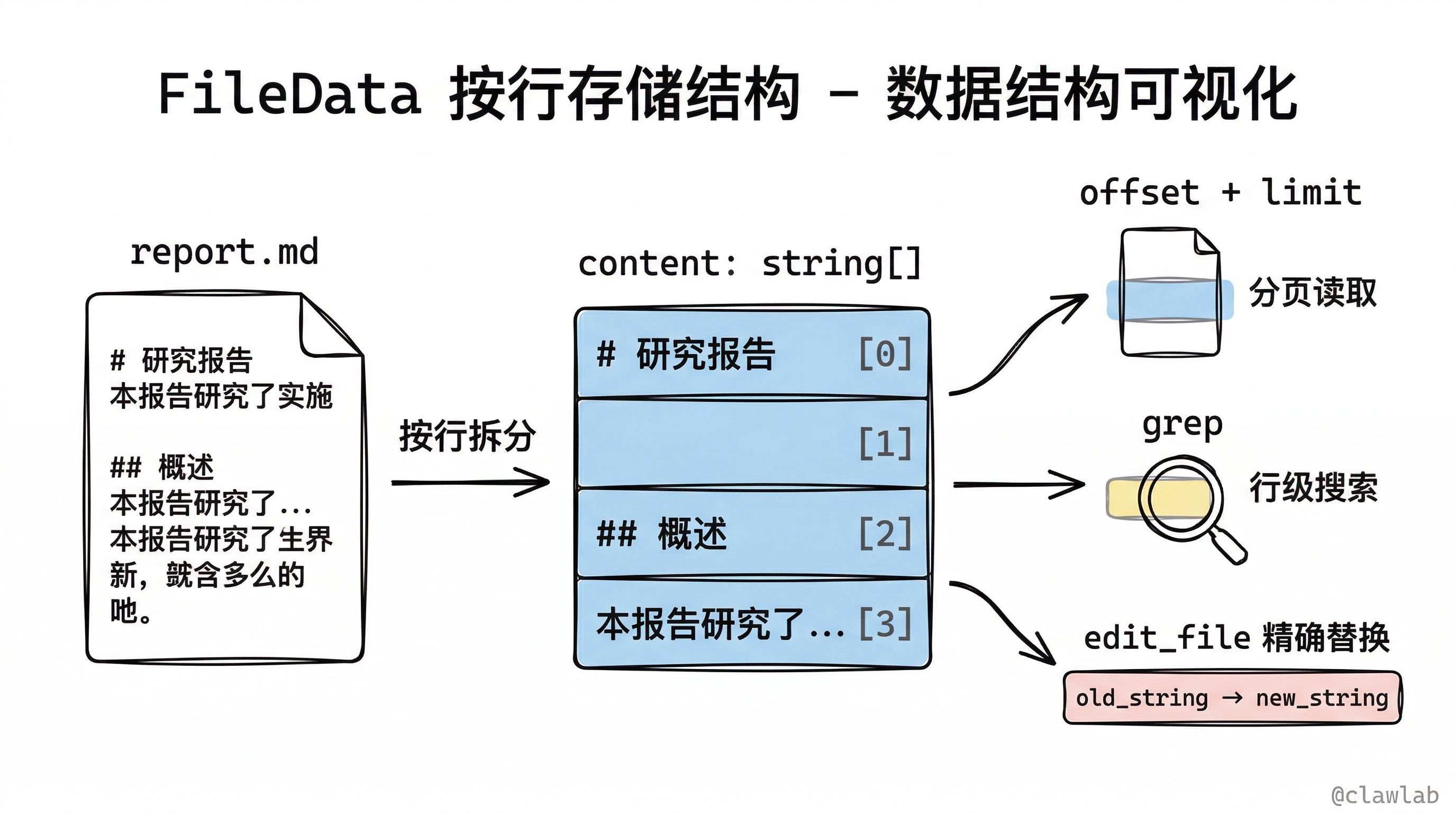
FileData 数据结构
所有存储在后端的文件都遵循 FileData 结构:
typescript
interface FileData {
content: string[]; // 文件内容(按行存储)
created_at: string; // 创建时间(ISO 8601)
modified_at: string; // 修改时间(ISO 8601)
}
// 示例
{
content: [
"# 研究报告",
"",
"## 概述",
"本报告研究了 DeepAgents 框架..."
],
created_at: "2024-01-15T10:30:00Z",
modified_at: "2024-01-15T11:45:00Z"
}为什么按行存储?
- 便于实现
offset和limit分页读取 - 支持行级别的 grep 搜索
- 方便 edit_file 的精确替换
创建 FileData 的辅助函数
typescript
import { createFileData } from "deepagents";
const fileData = createFileData("第一行\n第二行\n第三行");
// {
// content: ["第一行", "第二行", "第三行"],
// created_at: "2024-01-15T10:30:00Z",
// modified_at: "2024-01-15T10:30:00Z"
// }上下文管理:智能卸载
DeepAgents 的文件系统不仅是存储工具,还是上下文管理的核心机制。
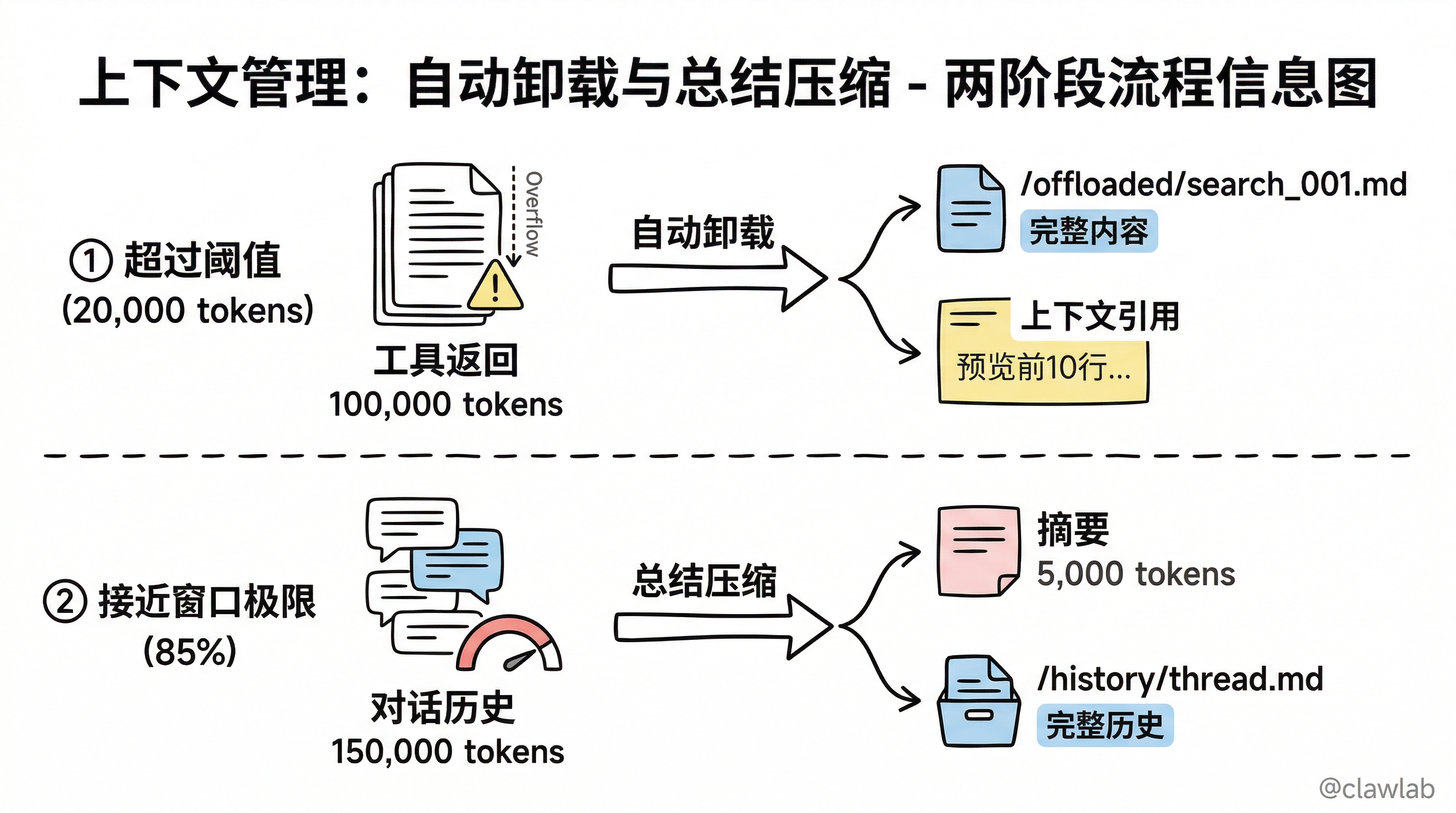
自动卸载大型内容
当工具调用的输入或结果超过阈值(默认 20,000 tokens)时,DeepAgents 会自动:
- 卸载到文件系统:将大内容保存为文件
- 替换为引用:在上下文中只保留文件路径和摘要
┌──────────────────────────────────────────────────────────┐
│ 工具返回 100,000 tokens 的搜索结果 │
└──────────────────────────────────────────────────────────┘
│
▼ 自动卸载
┌──────────────────────────────────────────────────────────┐
│ 1. write_file("/offloaded/search_001.md", 完整内容) │
│ 2. 上下文中替换为: │
│ "结果已保存到 /offloaded/search_001.md │
│ 预览前 10 行:..." │
└──────────────────────────────────────────────────────────┘总结压缩
当上下文接近窗口限制(85%)时,DeepAgents 会:
- 生成摘要:LLM 总结对话历史
- 保存原文:完整消息写入文件系统
- 替换上下文:用摘要替换详细历史
对话历史(150,000 tokens)
↓
┌───────────────────────────────────────┐
│ 摘要(5,000 tokens) │
│ + 完整历史保存到 /history/thread.md │
└───────────────────────────────────────┘
实践示例:研究助手
让我们构建一个利用文件系统管理上下文的研究助手:
typescript
import { createDeepAgent } from "deepagents";
import { tool } from "langchain";
import * as z from "zod";
const searchTool = tool(
async ({ query }) => {
// 模拟返回大量搜索结果
return `搜索 "${query}" 的结果:\n${"很长的内容...".repeat(1000)}`;
},
{
name: "search",
description: "搜索信息",
schema: z.object({ query: z.string() }),
}
);
const researchAssistant = createDeepAgent({
tools: [searchTool],
systemPrompt: `你是一名研究助手。执行研究任务时:
1. 使用 search 工具收集信息
2. 将搜索结果保存到 /research/ 目录
3. 在 /notes/ 目录整理分析笔记
4. 最终报告写入 /reports/
目录结构:
/research/ - 原始搜索结果
/notes/ - 分析笔记
/reports/ - 最终报告
注意:大型搜索结果会自动卸载到文件系统,你可以用 read_file 按需读取。`
});
async function main() {
const result = await researchAssistant.invoke({
messages: [{
role: "user",
content: "研究 DeepAgents 框架,写一份技术报告"
}]
});
console.log(result.messages[result.messages.length - 1].content);
}
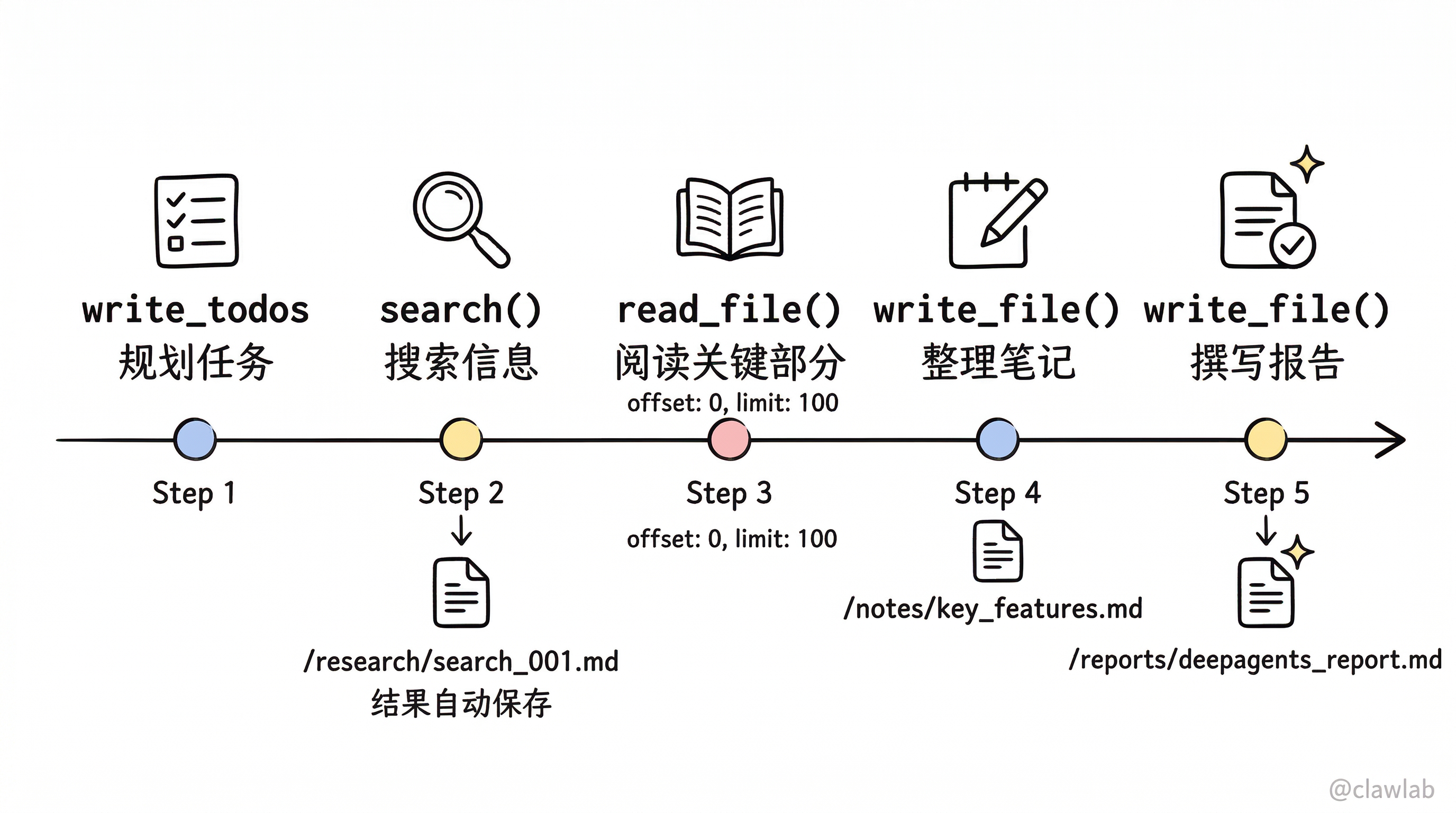
main();代理的执行流程:
1. write_todos([
"搜索 DeepAgents 官方文档",
"搜索 DeepAgents 使用案例",
"整理分析笔记",
"撰写技术报告"
])
2. search("DeepAgents official documentation")
→ 结果自动保存到 /research/search_001.md
3. search("DeepAgents use cases")
→ 结果自动保存到 /research/search_002.md
4. read_file("/research/search_001.md", { offset: 0, limit: 100 })
→ 阅读关键部分
5. write_file("/notes/key_features.md", "...")
→ 整理关键特性
6. write_file("/reports/deepagents_report.md", "...")
→ 撰写最终报告小结
本文介绍了 DeepAgents 虚拟文件系统的核心概念:
| 概念 | 说明 | 生活类比 |
|---|---|---|
| Backend | 可插拔的存储后端 | 不同的存储柜 |
| FileData | 文件数据结构 | 笔记本页面格式 |
| 文件系统工具 | ls/read/write/edit/glob/grep | 文件管理操作 |
| 自动卸载 | 大内容保存到文件 | 资料归档 |
| 总结压缩 | 历史摘要 + 原文保存 | 会议纪要 |
核心价值:
- ✅ 解决上下文窗口限制
- ✅ 支持长时间运行任务
- ✅ 提供可插拔的存储策略
- ✅ 实现智能的上下文管理
下一步
在下一篇文章中,我们将详细介绍五种后端类型:
- StateBackend(临时状态)
- FilesystemBackend(本地磁盘)
- StoreBackend(跨线程持久化)
- LocalShellBackend(本地 Shell)
- CompositeBackend(组合路由)
实践任务
- 创建一个代理,使用
write_file和read_file管理任务笔记 - 尝试让代理处理一个需要多步搜索和整理的研究任务
- 观察代理如何使用文件系统组织信息