
主题
LangChain 教程 08|短期记忆:会话上下文管理
📖 本篇导读:这是 LangChain 系列教程的第 8 篇。本篇将深入讲解短期记忆的实现原理、添加方法、状态扩展,以及处理长对话的常见策略。读完预计需要 8 分钟。
简单来说
短期记忆是 LangChain 中让 AI 代理能够记住之前交互内容的系统,就像人类对话中的短期记忆一样,它让代理能够在同一会话中保持上下文连贯性。短期记忆主要通过消息历史来实现,但由于模型上下文窗口的限制,我们需要使用各种策略来管理记忆,如修剪、删除或总结消息。
本节目标
- 理解短期记忆在 LangChain 中的作用和重要性
- 掌握如何为代理添加短期记忆
- 学会自定义代理状态和扩展记忆功能
- 掌握处理长对话的常见策略
- 了解如何在工具和中间件中访问和修改短期记忆
什么是短期记忆?
问题驱动
在构建对话式 AI 应用时,我们经常遇到以下挑战:
- 模型无法记住之前的对话内容,导致上下文丢失
- 长对话可能超出模型的上下文窗口限制
- 即使在上下文窗口内,长对话也会导致模型性能下降
- 长对话会增加响应时间和成本
短期记忆正是为了解决这些问题而设计的,它让代理能够在同一会话中保持上下文连贯性,同时通过各种策略管理记忆大小。
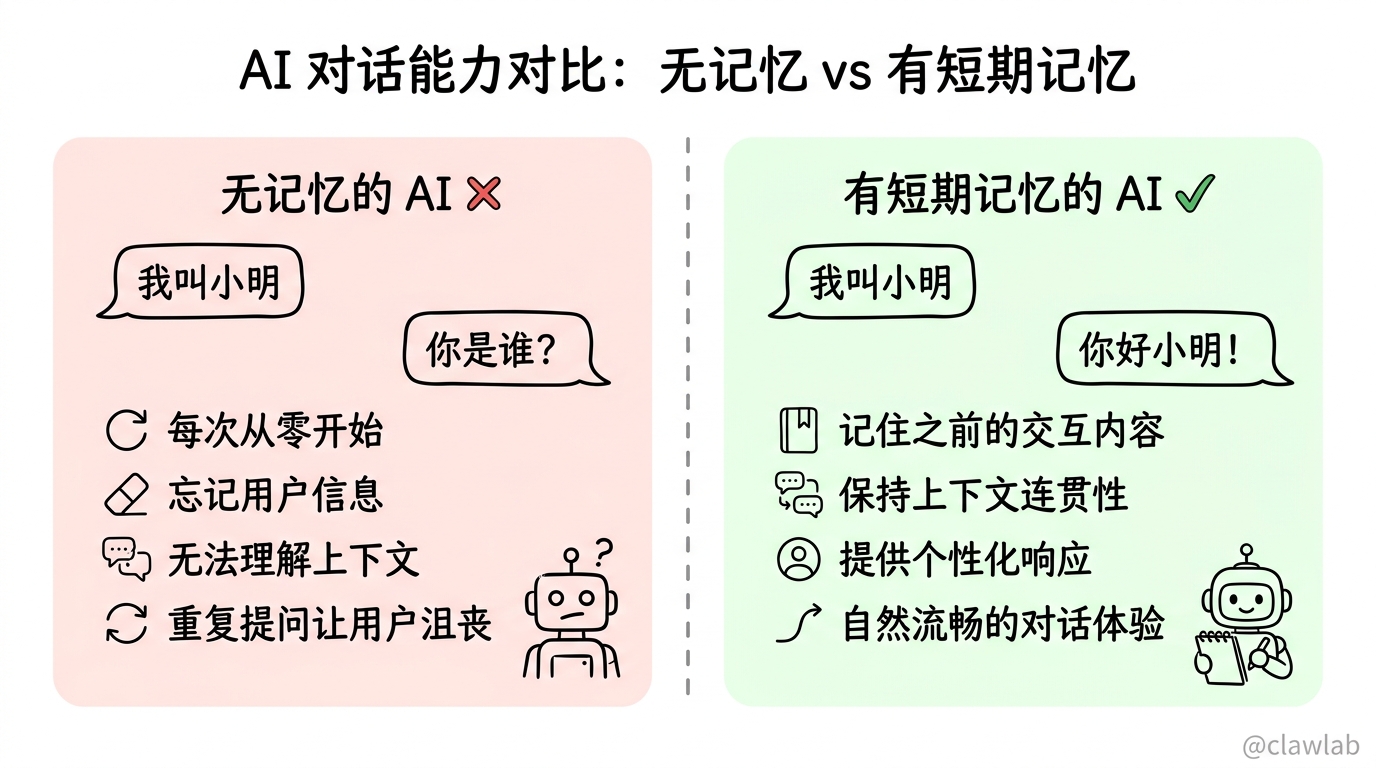
核心概念
短期记忆(也称为线程级持久性)让应用能够在单个线程或对话中记住之前的交互。对话历史是最常见的短期记忆形式。
LangChain 的代理将短期记忆作为代理状态的一部分进行管理,通过将这些状态存储在图的状态中,代理可以访问给定对话的完整上下文,同时保持不同线程之间的分离。
⚠️ 这里的「线程」和操作系统的线程不是一回事!
在计算机科学中,我们熟悉的是操作系统层面的概念:
- 进程(Process):独立运行的程序实例,拥有自己的内存空间
- 线程(Thread):进程内的执行单元,共享进程的内存,由 CPU 调度
- 协程(Coroutine):用户态的轻量级线程,由程序自身调度(如 JS 的
async/await)而 LangChain/LangGraph 中的 Thread(线程) 是一个业务概念,含义完全不同:
- 它指的是一轮独立的对话会话,类似聊天软件中的一个"对话窗口"
- 每个 Thread 用一个唯一的
thread_id来标识(如{ thread_id: "1" })- 同一个
thread_id下的所有消息共享同一份上下文记忆- 不同
thread_id之间的记忆是完全隔离的简单来说,LangChain 的 Thread ≈ 一个聊天会话,操作系统的 Thread ≈ 一个 CPU 执行流。两者只是恰好都叫"线程",概念上没有任何关系。
操作系统的线程 LangChain 的线程 ┌──────────────┐ ┌──────────────────┐ │ 进程 │ │ Agent │ │ ┌────────┐ │ │ ┌────────────┐ │ │ │ 线程 1 │ │ │ │ thread_id=1│ │ │ │ 线程 2 │ │ 完全不同! │ │ (用户A对话) │ │ │ │ 线程 3 │ │ ←————————→ │ ├────────────┤ │ │ └────────┘ │ │ │ thread_id=2│ │ │ 共享内存 │ │ │ (用户B对话) │ │ │ CPU调度 │ │ └────────────┘ │ └──────────────┘ │ 各自独立记忆 │ └──────────────────┘
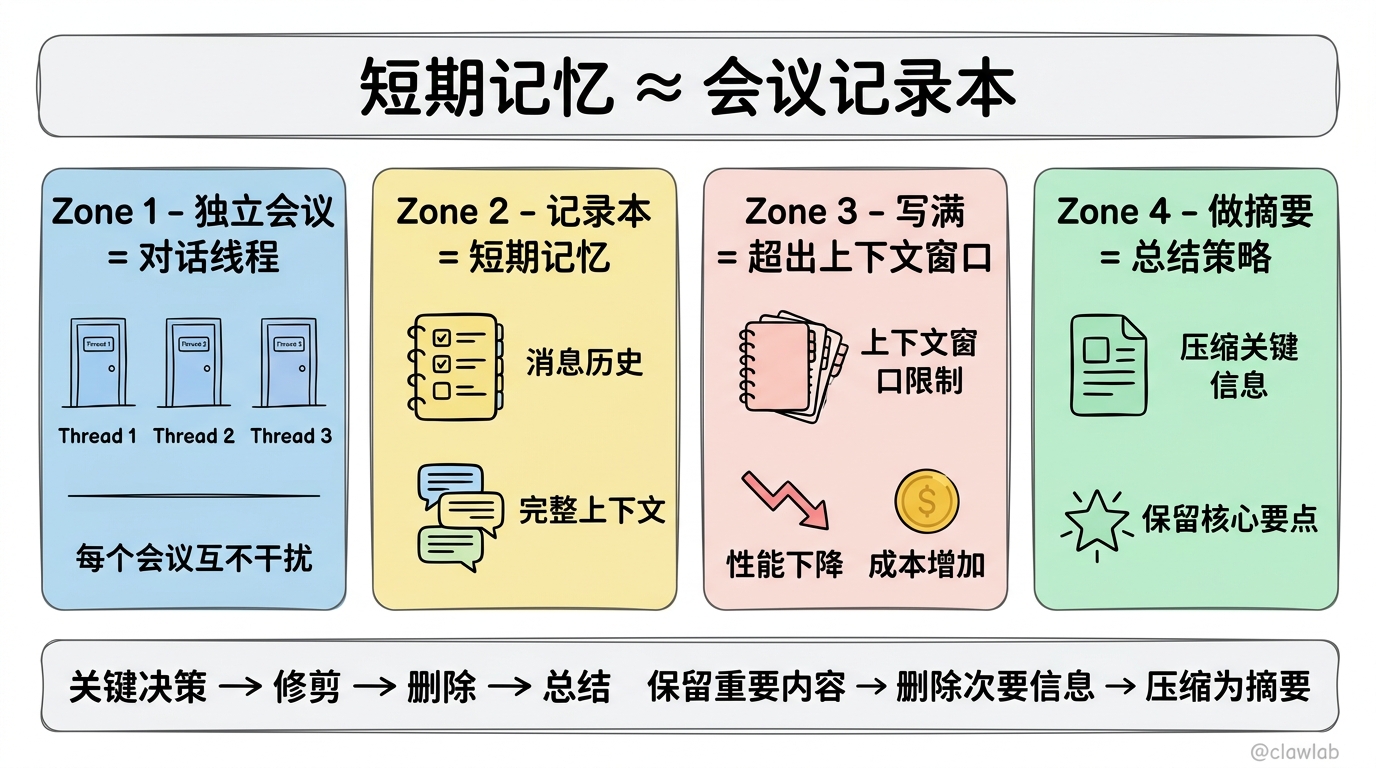
类比教学
想象一下短期记忆就像会议中的记录本:
- 每个对话线程就像一个独立的会议
- 会议记录本(短期记忆)记录了会议中的所有讨论内容
- 当会议时间过长时,记录本可能会写满(超出上下文窗口)
- 我们需要决定哪些内容重要(保留),哪些内容可以忽略(删除)
- 对于特别长的会议,我们可能需要做会议摘要(总结消息)
使用短期记忆
添加短期记忆
要为代理添加短期记忆(线程级持久性),您需要在创建代理时指定一个 checkpointer:
typescript
import { createAgent } from "langchain";
import { MemorySaver } from "@langchain/langgraph";
const checkpointer = new MemorySaver();
const agent = createAgent({
model: "claude-sonnet-4-5-20250929",
tools: [],
checkpointer,
});
await agent.invoke(
{ messages: [{ role: "user", content: "hi! i am Bob" }] },
{ configurable: { thread_id: "1" } }
);💡 为什么叫 Checkpointer?
Checkpoint(检查点) 这个概念来源于计算机科学中的经典术语:
- 在游戏中:检查点就是"存档点"——角色死了可以从存档点重新开始,不用从头来
- 在数据库中:检查点是将内存中的数据刷写到磁盘的时刻,用于崩溃恢复
- 在深度学习训练中:检查点是保存模型权重的快照,训练中断后可以从上次的检查点恢复
LangGraph 借用了同样的思想——在图执行的每一步(super-step)自动保存一份状态快照,这份快照就叫 Checkpoint。而负责执行"保存/读取快照"这个动作的组件,就叫 Checkpointer(检查点管理器)。
具体来说,Checkpointer 做了这些事情:
- 自动存档:Agent 每走一步(调用模型、执行工具),Checkpointer 就保存一份当前状态的快照
- 恢复记忆:下次用同一个
thread_id调用时,Checkpointer 自动加载上次的状态,Agent 就"记住"了之前的对话- 时间旅行:你可以回到任意一个历史检查点,查看或回滚状态(类似 Git 的 commit 历史)
- 容错恢复:如果某个节点执行失败,可以从最后一个成功的检查点重新开始
对话过程中 Checkpointer 的工作方式: 用户消息1 ──→ [Agent处理] ──→ 💾 Checkpoint 1(保存状态) │ 用户消息2 ──→ [加载 CP1] ──→ [Agent处理] ──→ 💾 Checkpoint 2 │ 用户消息3 ──→ [加载 CP2] ──→ [Agent处理] ──→ 💾 Checkpoint 3所以
MemorySaver是一个将检查点保存在内存中的 Checkpointer 实现,适合开发调试。生产环境需要换成持久化存储(如 PostgreSQL),这样即使服务重启,对话记忆也不会丢失。
⚠️ 每一步都存快照,会不会很浪费存储?
这是一个很自然的担忧。答案是:默认设计确实会产生存储开销,但 LangGraph 提供了多种机制来控制它。
首先,单个 Checkpoint 并没有你想象的那么大:
- 对于一个典型的聊天 Agent,每个 Checkpoint 主要存储的是消息列表(messages)和少量状态字段
- 一轮普通对话产生的 Checkpoint 大小通常在几 KB 到几十 KB 之间
- 并不是把整个程序内存都存下来,只存图的 state 部分
其次,存储开销和你获得的能力是对等的:
先理解一个关键点:每个 Checkpoint 都是当前状态的完整快照。也就是说,最新的那一个 Checkpoint 里已经包含了完整的对话历史(
messages数组是累积的),并不是每个 Checkpoint 只存"这一步新增的内容"。Checkpoint 1 的 messages: [用户消息1, AI回复1] Checkpoint 2 的 messages: [用户消息1, AI回复1, 用户消息2, AI回复2] Checkpoint 3 的 messages: [用户消息1, AI回复1, 用户消息2, AI回复2, 用户消息3, AI回复3] ↑ 每个 Checkpoint 都包含完整的对话历史!所以,多个 Checkpoint 之间存在大量重复数据——这就是存储冗余的来源。但正因为如此,我们才可以安全地只保留最新的一个 Checkpoint,对话记忆一条都不会丢。
能力 需要保留多少 Checkpoint 说明 对话记忆 只需最新的 1 个 最新 Checkpoint 里已包含全部对话历史,不会丢失任何记忆 时间旅行 / 调试 需要完整历史 要回到"第 3 步时的状态",就必须保留第 3 步的 Checkpoint 人工审核(Human-in-the-loop) 需要中断点的快照 暂停后需要从中断处恢复 故障恢复 至少最近一个成功的 失败后需要从上一个成功状态重跑 最后,LangGraph 提供了多种策略来控制存储量:
TTL(自动过期):为 Checkpoint 设置生存时间,过期自动删除
typescript// Redis 示例:Checkpoint 60 分钟后自动过期 const checkpointer = await RedisSaver.fromUrl("redis://localhost:6379", { defaultTTL: 60, // 60 分钟后过期 refreshOnRead: true // 读取时重置 TTL });Shallow Saver(只保留最新快照):如果你不需要时间旅行,可以用浅层存储,每个线程只保留最新一个 Checkpoint,旧的自动清理
typescript// 只保留最新的 Checkpoint,自动清理历史 import { ShallowRedisSaver } from "@langchain/langgraph-checkpoint-redis/shallow"; const checkpointer = await ShallowRedisSaver.fromUrl("redis://localhost:6379");压缩存储:部分 Checkpointer 实现支持对状态数据进行压缩后再存储,降低存储体积
压缩的工作原理:Checkpoint 在存储前要经过序列化(Serialization)——把内存中的 JavaScript 对象转换成可以存到数据库的字节流。LangGraph 默认使用
JsonPlusSerializer(基于 msgpack + JSON),它能处理 LangChain 原生对象、日期、枚举等复杂类型。压缩就是在序列化之后、写入存储之前,对这段字节流再做一次类似 gzip 的处理:内存中的 State 对象 │ ▼ ① 序列化(JsonPlusSerializer) │ 把对象变成字节流(如 JSON / msgpack 格式) ▼ ② 压缩(gzip / snappy 等) │ 把字节流压缩,体积通常缩小 50%-80% ▼ ③ 写入存储(DynamoDB / S3 / Redis ...) 读取时反向操作:存储 → 解压 → 反序列化 → State 对象以 AWS DynamoDB Checkpointer 为例,只需一个配置项即可开启:
python# Python 示例(DynamoDB Checkpointer) checkpointer = DynamoDBSaver( table_name="my_checkpoints_table", region_name="us-east-1", ttl_seconds=86400 * 30, # 30 天后过期 enable_checkpoint_compression=True, # 开启压缩 s3_offload_config={ # 大于 350KB 的自动转存 S3 "bucket_name": "my-checkpoint-bucket", } )DynamoDB Checkpointer 还有一个智能设计——大小分流:
- 小于 350 KB 的 Checkpoint → 直接存 DynamoDB(快速读写)
- 大于 350 KB 的 Checkpoint → 自动转存到 S3(突破 DynamoDB 单条记录大小限制),DynamoDB 里只存一个指针
压缩 + 分流 + TTL 三管齐下,生产环境的存储成本就可以控制在合理范围内。
总结:默认行为是"宁可多存、确保安全",但在生产环境中你可以根据实际需要选择合适的策略。如果只需要对话记忆,用 Shallow Saver 就够了;如果需要完整历史,加上 TTL 自动清理过期数据即可。
生产环境使用
在生产环境中,您应该使用由数据库支持的检查点:
typescript
import { PostgresSaver } from "@langchain/langgraph-checkpoint-postgres";
const DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable";
const checkpointer = PostgresSaver.fromConnString(DB_URI);LangChain 支持多种检查点库,包括 SQLite、Postgres 和 Azure Cosmos DB 等。
自定义代理记忆
您可以通过创建带有状态模式的自定义中间件来扩展代理状态:
typescript
import { createAgent, createMiddleware } from "langchain";
import { StateSchema, MemorySaver } from "@langchain/langgraph";
import * as z from "zod";
// 定义自定义状态
const CustomState = new StateSchema({
userId: z.string(),
preferences: z.record(z.string(), z.any()),
});
// 创建状态扩展中间件
const stateExtensionMiddleware = createMiddleware({
name: "StateExtension",
stateSchema: CustomState,
});
// 创建检查点
const checkpointer = new MemorySaver();
// 创建带有自定义状态的代理
const agent = createAgent({
model: "gpt-5",
tools: [],
middleware: [stateExtensionMiddleware],
checkpointer,
});
// 在调用时传递自定义状态
const result = await agent.invoke({
messages: [{ role: "user", content: "Hello" }],
userId: "user_123",
preferences: { theme: "dark" },
});常见模式
启用短期记忆后,长对话可能会超出 LLM 的上下文窗口。以下是处理长对话的常见策略:
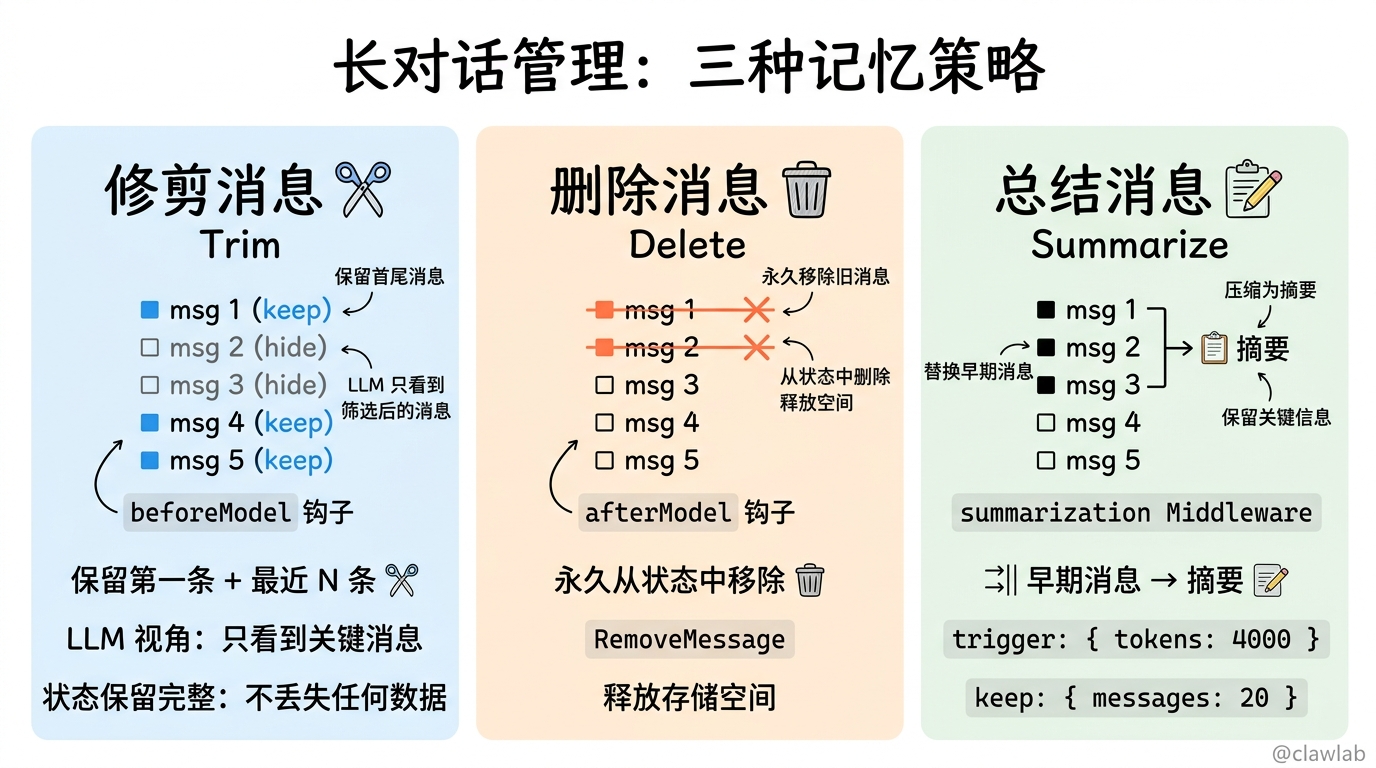
1. 修剪消息
删除最早或最近的 N 条消息(在调用 LLM 之前):
typescript
import { RemoveMessage } from "@langchain/core/messages";
import { createAgent, createMiddleware } from "langchain";
import { MemorySaver, REMOVE_ALL_MESSAGES } from "@langchain/langgraph";
// 创建消息修剪中间件
const trimMessages = createMiddleware({
name: "TrimMessages",
beforeModel: (state) => {
const messages = state.messages;
if (messages.length <= 3) {
return; // 不需要更改
}
// 保留第一条消息和最近的几条消息
const firstMsg = messages[0];
const recentMessages =
messages.length % 2 === 0 ? messages.slice(-3) : messages.slice(-4);
const newMessages = [firstMsg, ...recentMessages];
return {
messages: [
new RemoveMessage({ id: REMOVE_ALL_MESSAGES }),
...newMessages,
],
};
},
});
// 创建代理
const checkpointer = new MemorySaver();
const agent = createAgent({
model: "gpt-4.1",
tools: [],
middleware: [trimMessages],
checkpointer,
});2. 删除消息
从 LangGraph 状态中永久删除消息:
typescript
import { RemoveMessage } from "@langchain/core/messages";
import { createAgent, createMiddleware } from "langchain";
import { MemorySaver } from "@langchain/langgraph";
// 创建消息删除中间件
const deleteOldMessages = createMiddleware({
name: "DeleteOldMessages",
afterModel: (state) => {
const messages = state.messages;
if (messages.length > 2) {
// 删除最早的两条消息
return {
messages: messages
.slice(0, 2)
.map((m) => new RemoveMessage({ id: m.id! })),
};
}
return;
},
});
// 创建代理
const agent = createAgent({
model: "gpt-4.1",
tools: [],
systemPrompt: "Please be concise and to the point.",
middleware: [deleteOldMessages],
checkpointer: new MemorySaver(),
});3. 总结消息
总结早期消息并将它们替换为摘要:
typescript
import { createAgent, summarizationMiddleware } from "langchain";
import { MemorySaver } from "@langchain/langgraph";
// 创建检查点
const checkpointer = new MemorySaver();
// 创建带有摘要中间件的代理
const agent = createAgent({
model: "gpt-4.1",
tools: [],
middleware: [
summarizationMiddleware({
model: "gpt-4.1-mini",
trigger: { tokens: 4000 }, // 当消息达到 4000 tokens 时触发摘要
keep: { messages: 20 }, // 保留最近的 20 条消息
}),
],
checkpointer,
});
// 测试长对话
const config = { configurable: { thread_id: "1" } };
await agent.invoke({ messages: "hi, my name is bob" }, config);
await agent.invoke({ messages: "write a short poem about cats" }, config);
await agent.invoke({ messages: "now do the same but for dogs" }, config);
const finalResponse = await agent.invoke({ messages: "what's my name?" }, config);
console.log(finalResponse.messages.at(-1)?.content);
// Your name is Bob!4. 自定义策略
根据业务需求创建自定义策略,例如消息过滤、重要性排序等。
访问记忆
您可以通过多种方式访问和修改代理的短期记忆(状态):
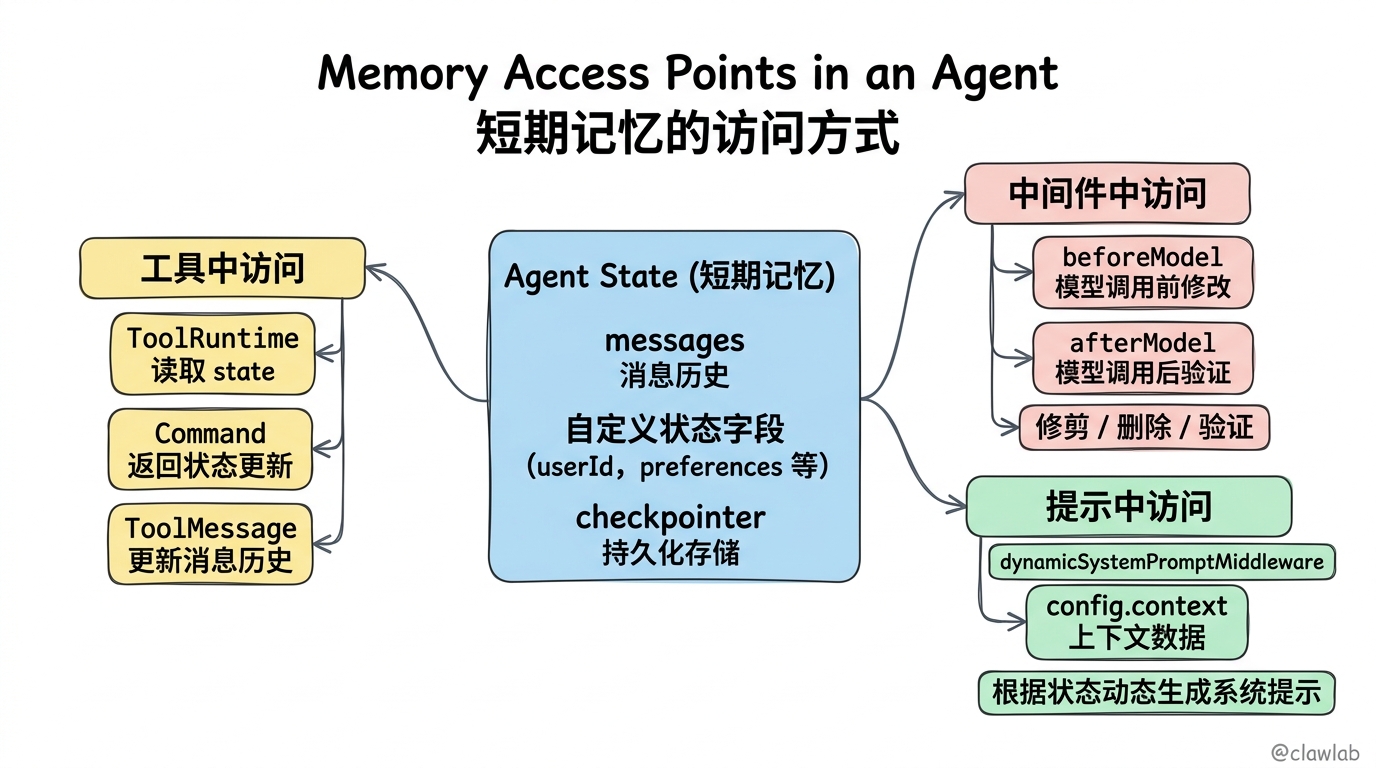
在工具中访问短期记忆
使用 runtime 参数(类型为 ToolRuntime)在工具中访问短期记忆(状态):
typescript
import { createAgent, tool, type ToolRuntime } from "langchain";
import { StateSchema } from "@langchain/langgraph";
import * as z from "zod";
// 定义自定义状态
const CustomState = new StateSchema({
userId: z.string(),
});
// 创建访问用户信息的工具
const getUserInfo = tool(
async (_, config: ToolRuntime<typeof CustomState.State>) => {
const userId = config.state.userId;
return userId === "user_123" ? "John Doe" : "Unknown User";
},
{
name: "get_user_info",
description: "Get user info",
schema: z.object({}),
}
);
// 创建代理
const agent = createAgent({
model: "gpt-5-nano",
tools: [getUserInfo],
stateSchema: CustomState,
});
// 测试工具
const result = await agent.invoke(
{
messages: [{ role: "user", content: "what's my name?" }],
userId: "user_123",
},
{
context: {},
}
);
console.log(result.messages.at(-1)?.content);
// Outputs: "Your name is John Doe."在工具中修改短期记忆
要在执行过程中修改代理的短期记忆(状态),您可以直接从工具返回状态更新:
typescript
import { tool, createAgent, ToolMessage, type ToolRuntime } from "langchain";
import { Command, StateSchema } from "@langchain/langgraph";
import * as z from "zod";
// 定义自定义状态
const CustomState = new StateSchema({
userId: z.string().optional(),
});
// 创建更新用户信息的工具
const updateUserInfo = tool(
async (_, config: ToolRuntime<typeof CustomState.State>) => {
const userId = config.state.userId;
const name = userId === "user_123" ? "John Smith" : "Unknown user";
return new Command({
update: {
userName: name,
// 更新消息历史
messages: [
new ToolMessage({
content: "Successfully looked up user information",
tool_call_id: config.toolCall?.id ?? "",
}),
],
},
});
},
{
name: "update_user_info",
description: "Look up and update user info.",
schema: z.object({}),
}
);
// 创建问候工具
const greet = tool(
async (_, config) => {
const userName = config.context?.userName;
return `Hello ${userName}!`;
},
{
name: "greet",
description: "Use this to greet the user once you found their info.",
schema: z.object({}),
}
);
// 创建代理
const agent = createAgent({
model: "openai:gpt-5-mini",
tools: [updateUserInfo, greet],
stateSchema: CustomState,
});
// 测试代理
const result = await agent.invoke({
messages: [{ role: "user", content: "greet the user" }],
userId: "user_123",
});
console.log(result.messages.at(-1)?.content);
// Output: "Hello! I'm here to help — what would you like to do today?"在提示中访问短期记忆
在中间件中访问短期记忆(状态),以基于对话历史或自定义状态字段创建动态提示:
typescript
import * as z from "zod";
import { createAgent, tool, dynamicSystemPromptMiddleware } from "langchain";
// 定义上下文模式
const contextSchema = z.object({
userName: z.string(),
});
type ContextSchema = z.infer<typeof contextSchema>;
// 创建天气工具
const getWeather = tool(
async ({ city }) => {
return `The weather in ${city} is always sunny!`;
},
{
name: "get_weather",
description: "Get user info",
schema: z.object({
city: z.string(),
}),
}
);
// 创建代理
const agent = createAgent({
model: "gpt-5-nano",
tools: [getWeather],
contextSchema,
middleware: [
dynamicSystemPromptMiddleware<ContextSchema>((_, config) => {
return `You are a helpful assistant. Address the user as ${config.context?.userName}.`;
}),
],
});
// 测试代理
const result = await agent.invoke(
{
messages: [{ role: "user", content: "What is the weather in SF?" }],
},
{
context: {
userName: "John Smith",
},
}
);
// 输出结果
for (const message of result.messages) {
console.log(message);
}在模型调用前访问记忆
使用 beforeModel 钩子在模型调用前访问和修改记忆:
typescript
import { RemoveMessage } from "@langchain/core/messages";
import { createAgent, createMiddleware, trimMessages } from "langchain";
import { MemorySaver } from "@langchain/langgraph";
import { REMOVE_ALL_MESSAGES } from "@langchain/langgraph";
// 创建消息修剪中间件
const trimMessageHistory = createMiddleware({
name: "TrimMessages",
beforeModel: async (state) => {
// 修剪消息
const trimmed = await trimMessages(state.messages, {
maxTokens: 384,
strategy: "last",
startOn: "human",
endOn: ["human", "tool"],
tokenCounter: (msgs) => msgs.length,
});
// 返回修剪后的消息
return {
messages: [new RemoveMessage({ id: REMOVE_ALL_MESSAGES }), ...trimmed],
};
},
});
// 创建代理
const checkpointer = new MemorySaver();
const agent = createAgent({
model: "gpt-5-nano",
tools: [],
middleware: [trimMessageHistory],
checkpointer,
});在模型调用后访问记忆
使用 afterModel 钩子在模型调用后访问和修改记忆:
typescript
import { RemoveMessage } from "@langchain/core/messages";
import { createAgent, createMiddleware } from "langchain";
import { REMOVE_ALL_MESSAGES } from "@langchain/langgraph";
// 创建响应验证中间件
const validateResponse = createMiddleware({
name: "ValidateResponse",
afterModel: (state) => {
const lastMessage = state.messages.at(-1)?.content;
if (
typeof lastMessage === "string" &&
lastMessage.toLowerCase().includes("confidential")
) {
// 如果响应包含机密信息,删除所有消息
return {
messages: [
new RemoveMessage({ id: REMOVE_ALL_MESSAGES }),
],
};
}
return;
},
});
// 创建代理
const agent = createAgent({
model: "gpt-5-nano",
tools: [],
middleware: [validateResponse],
});业务场景
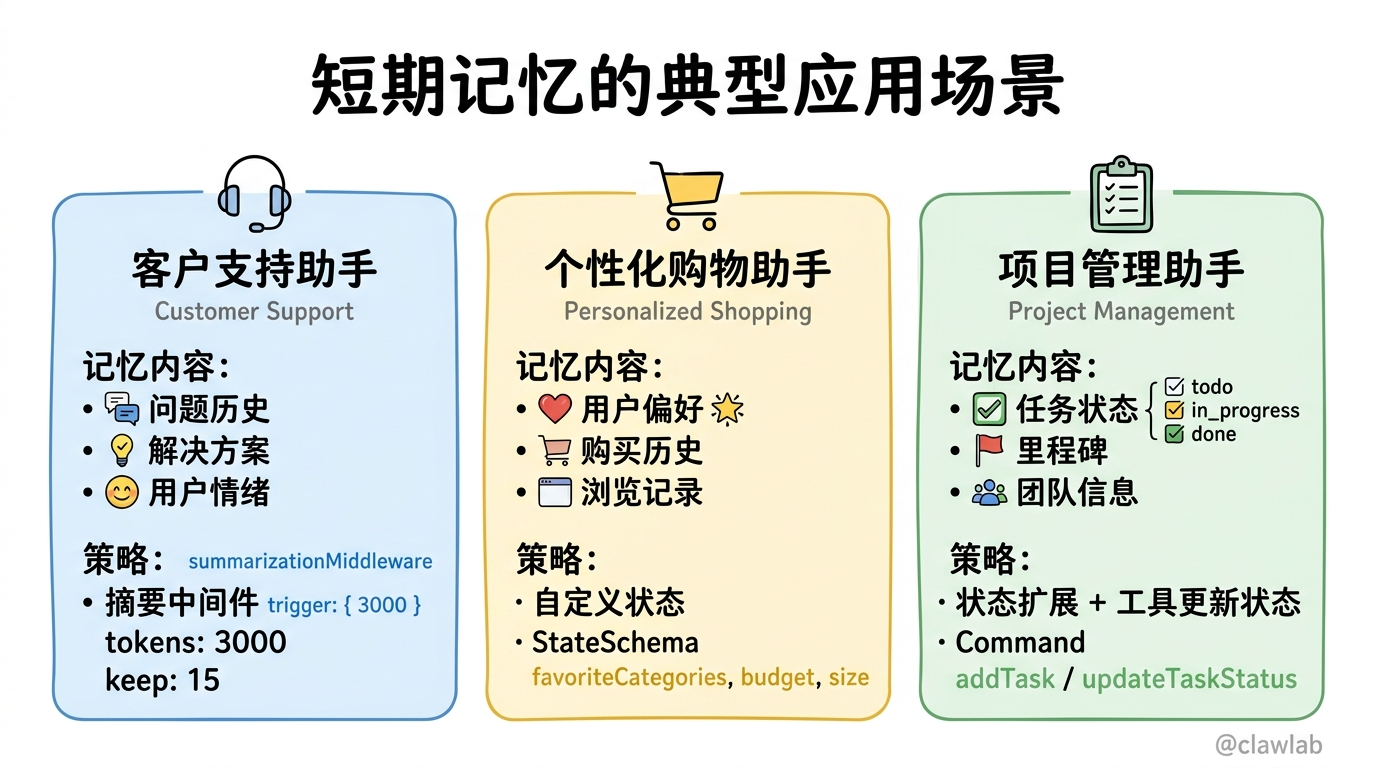
场景一:客户支持助手
问题:如何构建一个能够记住客户之前问题和解决方案的客户支持助手?
解决方案:使用短期记忆存储客户对话历史,并在长对话时使用摘要策略
typescript
import { createAgent, summarizationMiddleware } from "langchain";
import { MemorySaver } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
// 创建检查点
const checkpointer = new MemorySaver();
// 创建客户支持助手
const supportAgent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [], // 可以添加知识库查询等工具
systemPrompt: `你是一位专业的客户支持助手,能够帮助用户解决各种问题。
请保持友好、耐心的态度,提供详细、准确的解答。
记住用户之前提到的问题和解决方案,避免重复提问。`,
middleware: [
summarizationMiddleware({
model: new ChatOpenAI({ model: "gpt-4.1-mini" }),
trigger: { tokens: 3000 },
keep: { messages: 15 },
}),
],
checkpointer,
});
// 测试客户支持对话
const config = { configurable: { thread_id: "support_1" } };
// 第一次交互
await supportAgent.invoke(
{ messages: [{ role: "user", content: "你好,我的账户无法登录,提示密码错误,但我确定密码是正确的。" }] },
config
);
// 第二次交互
await supportAgent.invoke(
{ messages: [{ role: "user", content: "我已经尝试了多次,还是无法登录。我上次登录是在昨天。" }] },
config
);
// 第三次交互
await supportAgent.invoke(
{ messages: [{ role: "user", content: "我记得我上周修改过密码,但现在忘记了新密码。" }] },
config
);
// 第四次交互(测试记忆)
const finalResponse = await supportAgent.invoke(
{ messages: [{ role: "user", content: "你能帮我总结一下我遇到的问题以及解决方案吗?" }] },
config
);
console.log(finalResponse.messages.at(-1)?.content);场景二:个性化购物助手
问题:如何构建一个能够记住用户偏好和购买历史的购物助手?
解决方案:使用自定义状态存储用户偏好,并在对话中使用这些信息
typescript
import * as z from "zod";
import { createAgent, createMiddleware, tool } from "langchain";
import { StateSchema, MemorySaver } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
// 定义用户偏好状态
const UserPreferenceState = new StateSchema({
userId: z.string(),
preferences: z.object({
favoriteCategories: z.array(z.string()),
budget: z.number().optional(),
size: z.string().optional(),
color: z.string().optional(),
}),
purchaseHistory: z.array(z.object({
productId: z.string(),
productName: z.string(),
date: z.string(),
})),
});
// 创建状态扩展中间件
const userPreferenceMiddleware = createMiddleware({
name: "UserPreference",
stateSchema: UserPreferenceState,
});
// 创建产品推荐工具
const recommendProducts = tool(
({ category }, config) => {
const preferences = config.state.preferences;
const history = config.state.purchaseHistory;
// 基于用户偏好和购买历史推荐产品
const recommendations = [
`根据您对 ${category} 的兴趣,推荐以下产品:`,
`- 产品 A: 符合您喜欢的 ${preferences.color || "颜色"}`,
`- 产品 B: 在您的预算范围内`,
`- 产品 C: 与您之前购买的 ${history[0]?.productName || "产品"} 类似`,
];
return recommendations.join("\n");
},
{
name: "recommend_products",
description: "根据用户偏好推荐产品",
schema: z.object({
category: z.string().describe("产品类别"),
}),
}
);
// 创建检查点
const checkpointer = new MemorySaver();
// 创建购物助手
const shoppingAgent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [recommendProducts],
systemPrompt: `你是一位个性化购物助手,能够根据用户的偏好和购买历史推荐产品。
请使用友好、专业的语气,提供符合用户需求的建议。
记住用户之前提到的偏好和购买记录。`,
middleware: [userPreferenceMiddleware],
checkpointer,
});
// 测试购物助手
const config = { configurable: { thread_id: "shopping_1" } };
// 初始化用户信息
const initialState = {
messages: [{ role: "user", content: "你好,我想购买一些新衣服。" }],
userId: "user_456",
preferences: {
favoriteCategories: ["T恤", "牛仔裤", "运动鞋"],
budget: 500,
size: "M",
color: "蓝色",
},
purchaseHistory: [
{ productId: "p1", productName: "蓝色牛仔裤", date: "2024-01-15" },
{ productId: "p2", productName: "白色T恤", date: "2024-02-10" },
],
};
// 第一次交互
await shoppingAgent.invoke(initialState, config);
// 第二次交互(测试个性化推荐)
const response = await shoppingAgent.invoke(
{ messages: [{ role: "user", content: "你能推荐一些T恤吗?" }] },
config
);
console.log(response.messages.at(-1)?.content);场景三:项目管理助手
问题:如何构建一个能够记住项目进展和任务状态的项目管理助手?
解决方案:使用短期记忆跟踪项目进展,并在对话中更新任务状态
typescript
import * as z from "zod";
import { createAgent, createMiddleware, tool, Command } from "langchain";
import { StateSchema, MemorySaver } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
// 定义任务状态
const TaskState = z.object({
id: z.string(),
title: z.string(),
status: z.enum(["todo", "in_progress", "done"]),
assignee: z.string().optional(),
deadline: z.string().optional(),
});
// 定义项目状态
const ProjectState = new StateSchema({
projectId: z.string(),
projectName: z.string(),
tasks: z.array(TaskState),
milestones: z.array(z.object({
id: z.string(),
title: z.string(),
date: z.string(),
})),
});
// 创建状态扩展中间件
const projectMiddleware = createMiddleware({
name: "ProjectManagement",
stateSchema: ProjectState,
});
// 创建添加任务工具
const addTask = tool(
({ title, assignee, deadline }, config) => {
const newTask = {
id: `task_${Date.now()}`,
title,
status: "todo" as const,
assignee,
deadline,
};
// 更新任务列表
const updatedTasks = [...config.state.tasks, newTask];
return new Command({
update: {
tasks: updatedTasks,
},
content: `任务已添加:${title}`,
});
},
{
name: "add_task",
description: "添加新任务",
schema: z.object({
title: z.string().describe("任务标题"),
assignee: z.string().optional().describe("负责人"),
deadline: z.string().optional().describe("截止日期"),
}),
}
);
// 创建更新任务状态工具
const updateTaskStatus = tool(
({ taskId, status }, config) => {
const updatedTasks = config.state.tasks.map(task =>
task.id === taskId ? { ...task, status } : task
);
return new Command({
update: {
tasks: updatedTasks,
},
content: `任务状态已更新:${status}`,
});
},
{
name: "update_task_status",
description: "更新任务状态",
schema: z.object({
taskId: z.string().describe("任务ID"),
status: z.enum(["todo", "in_progress", "done"]).describe("新状态"),
}),
}
);
// 创建获取项目概览工具
const getProjectOverview = tool(
(_, config) => {
const project = config.state;
const todoTasks = project.tasks.filter(t => t.status === "todo").length;
const inProgressTasks = project.tasks.filter(t => t.status === "in_progress").length;
const doneTasks = project.tasks.filter(t => t.status === "done").length;
return `项目概览:${project.projectName}\n\n` +
`任务状态:\n` +
`- 待办:${todoTasks}\n` +
`- 进行中:${inProgressTasks}\n` +
`- 已完成:${doneTasks}\n\n` +
`最近里程碑:\n` +
`${project.milestones.slice(0, 3).map(m => `- ${m.title} (${m.date})`).join("\n")}`;
},
{
name: "get_project_overview",
description: "获取项目概览",
schema: z.object({}),
}
);
// 创建检查点
const checkpointer = new MemorySaver();
// 创建项目管理助手
const projectAgent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [addTask, updateTaskStatus, getProjectOverview],
systemPrompt: `你是一位专业的项目管理助手,能够帮助用户跟踪项目进展和任务状态。\n请保持清晰、简洁的沟通风格,提供准确的项目信息。\n记住项目的任务状态和里程碑,帮助用户有效地管理项目。`,
middleware: [projectMiddleware],
checkpointer,
});
// 初始化项目
const initialState = {
messages: [{ role: "user", content: "你好,我需要帮助管理一个新的项目。" }],
projectId: "project_1",
projectName: "网站重构项目",
tasks: [
{ id: "task_1", title: "需求分析", status: "done", assignee: "张三", deadline: "2024-03-01" },
{ id: "task_2", title: "设计原型", status: "done", assignee: "李四", deadline: "2024-03-15" },
{ id: "task_3", title: "前端开发", status: "in_progress", assignee: "王五", deadline: "2024-04-15" },
],
milestones: [
{ id: "milestone_1", title: "需求确认", date: "2024-03-01" },
{ id: "milestone_2", title: "设计完成", date: "2024-03-15" },
{ id: "milestone_3", title: "开发完成", date: "2024-04-30" },
{ id: "milestone_4", title: "项目上线", date: "2024-05-15" },
],
};
// 测试项目管理助手
const config = { configurable: { thread_id: "project_1" } };
// 初始化对话
await projectAgent.invoke(initialState, config);
// 添加新任务
await projectAgent.invoke(
{ messages: [{ role: "user", content: "请添加一个新任务:后端API开发,负责人是赵六,截止日期是2024-04-20。" }] },
config
);
// 更新任务状态
await projectAgent.invoke(
{ messages: [{ role: "user", content: "请将前端开发任务标记为已完成。" }] },
config
);
// 获取项目概览
const overviewResponse = await projectAgent.invoke(
{ messages: [{ role: "user", content: "请给我项目的当前概览。" }] },
config
);
console.log(overviewResponse.messages.at(-1)?.content);技术要点
1. 记忆管理策略
- 上下文窗口限制:了解并尊重模型的上下文窗口限制
- 记忆修剪:使用适当的策略修剪或删除旧消息
- 记忆总结:对长对话进行总结,保留关键信息
- 记忆优先级:根据信息重要性调整记忆策略
2. 状态管理
- 自定义状态:根据业务需求定义自定义状态结构
- 状态扩展:使用中间件扩展代理状态
- 状态持久化:在生产环境中使用数据库存储状态
- 状态一致性:确保状态更新的一致性和可靠性
3. 性能优化
- 记忆大小:控制记忆大小,避免超出上下文窗口
- 总结时机:选择合适的时机触发记忆总结
- 中间件顺序:合理安排中间件顺序,优化处理流程
- 并行处理:在适当情况下使用并行处理提高性能
4. 安全性
- 敏感信息:避免在记忆中存储敏感信息
- 状态验证:验证状态更新的合法性
- 访问控制:控制对状态的访问权限
- 数据加密:在存储敏感状态时使用加密
5. 最佳实践
明确的系统提示:指导代理如何使用记忆
通过系统提示告诉模型它拥有对话记忆、应该如何利用上下文,避免模型"忘记"自己已经知道的信息:
typescript
const agent = createAgent({
model: "gpt-4.1",
tools: [],
prompt: `你是一个客户支持助手。
记忆使用规则:
1. 用户首次提到姓名时,在后续对话中主动使用该姓名称呼用户
2. 用户提到过的偏好(如语言、格式要求)应在整个对话中保持
3. 如果用户之前已经描述过问题,不要重复询问,直接引用之前的描述
4. 对话中出现的关键信息(订单号、产品名称等)应在需要时主动引用`,
checkpointer,
});一致的状态结构:保持可预测性
定义 state schema 时使用明确的类型和默认值,避免出现 undefined 或结构不一致的情况:
typescript
import { z } from "zod";
const stateSchema = z.object({
messages: z.array(z.any()).default([]),
userName: z.string().default(""),
language: z.enum(["zh", "en", "ja"]).default("zh"),
issueResolved: z.boolean().default(false),
mentionedOrderIds: z.array(z.string()).default([]),
});
const middleware = createMiddleware({
name: "TrackUserInfo",
stateSchema,
beforeModel: (state) => {
return state;
},
});💡 为什么要这样做? 如果状态字段有时候存在有时候不存在(比如有的 Checkpoint 有
userName,有的没有),代码里就需要到处写if (state.userName)这样的防御性判断,容易出 bug。给每个字段设置.default()能确保状态结构始终一致。
合理的触发条件:为记忆管理策略设置阈值
不要等到上下文爆炸了才处理,提前设置合理的触发阈值:
typescript
import { createMiddleware } from "langchain";
import { trimMessages } from "@langchain/core/messages";
import { summarizeMessages } from "./utils";
const memoryManagement = createMiddleware({
name: "MemoryManagement",
beforeModel: async (state) => {
const messageCount = state.messages.length;
if (messageCount > 50) {
const summary = await summarizeMessages(state.messages.slice(0, -10));
return {
...state,
messages: [
{ role: "system", content: `之前的对话摘要:${summary}` },
...state.messages.slice(-10),
],
};
}
if (messageCount > 20) {
return {
...state,
messages: trimMessages(state.messages, {
maxTokens: 4000,
strategy: "last",
}),
};
}
return state;
},
});💡 分级策略:消息少(< 20 条)→ 全部保留;消息中等(20-50 条)→ 修剪保留最近的;消息很多(> 50 条)→ 摘要 + 最近 10 条。这样既节省 token 又不会丢失重要上下文。
监控和调试:观测记忆管理的实际表现
利用 getState 和 getStateHistory 检查记忆状态,在开发阶段提前发现问题:
typescript
const config = { configurable: { thread_id: "debug-session-1" } };
const snapshot = await agent.getState(config);
console.log("当前消息数量:", snapshot.values.messages.length);
console.log("下一步节点:", snapshot.next);
console.log("最新消息:", snapshot.values.messages.at(-1)?.content);
for await (const state of agent.getStateHistory(config)) {
console.log(
`Step ${state.metadata.step}: ` +
`${state.values.messages.length} messages, ` +
`next: [${state.next.join(", ")}]`
);
}在生产环境中,可以添加指标监控来追踪记忆的健康状况:
typescript
const memoryMonitor = createMiddleware({
name: "MemoryMonitor",
beforeModel: (state) => {
const msgCount = state.messages.length;
const estimatedTokens = JSON.stringify(state.messages).length / 4;
if (estimatedTokens > 100_000) {
console.warn(
`[MemoryMonitor] thread token estimate: ${estimatedTokens}, ` +
`consider triggering summarization`
);
}
console.log(
`[MemoryMonitor] messages: ${msgCount}, ~tokens: ${estimatedTokens}`
);
return state;
},
});💡 关注什么指标?
- 消息数量:是否接近触发修剪/摘要的阈值
- 估算 token 数:是否接近模型上下文窗口上限
- Checkpoint 大小:存储是否增长过快
- 响应延迟:上下文过长时模型响应会明显变慢,这也是需要介入记忆管理的信号
总结
短期记忆是 LangChain 中构建有效对话式 AI 应用的关键组件,它让代理能够在同一会话中保持上下文连贯性,提供更加个性化、连贯的用户体验。通过合理的记忆管理策略,我们可以在模型上下文窗口限制和对话连贯性之间取得平衡。
核心优势
- 上下文连贯性:保持对话的上下文连贯性,避免上下文丢失
- 个性化体验:根据用户历史交互提供个性化服务
- 效率提升:减少重复提问,提高对话效率
- 智能决策:基于历史信息做出更智能的决策
应用前景
短期记忆的应用前景非常广阔,从客户支持、购物助手到项目管理、教育辅导,几乎所有对话式 AI 应用都可以受益于有效的短期记忆管理。随着模型能力的不断提升和上下文窗口的不断扩大,短期记忆管理策略也将不断演进,为用户提供更加自然、智能的对话体验。
通过掌握短期记忆的使用和管理技巧,开发者可以构建更加智能、高效、个性化的 AI 应用,为用户创造更大的价值。