
主题
LangChain 教程 27|RAG 检索增强:让 AI 拥有知识库
📖 本篇导读:这是 LangChain 系列教程的第 27 篇。本篇将深入讲解 RAG 的核心原理、知识库构建流程,以及三种 RAG 架构:2-Step、Agentic、Hybrid。读完预计需要 15 分钟。
简单来说
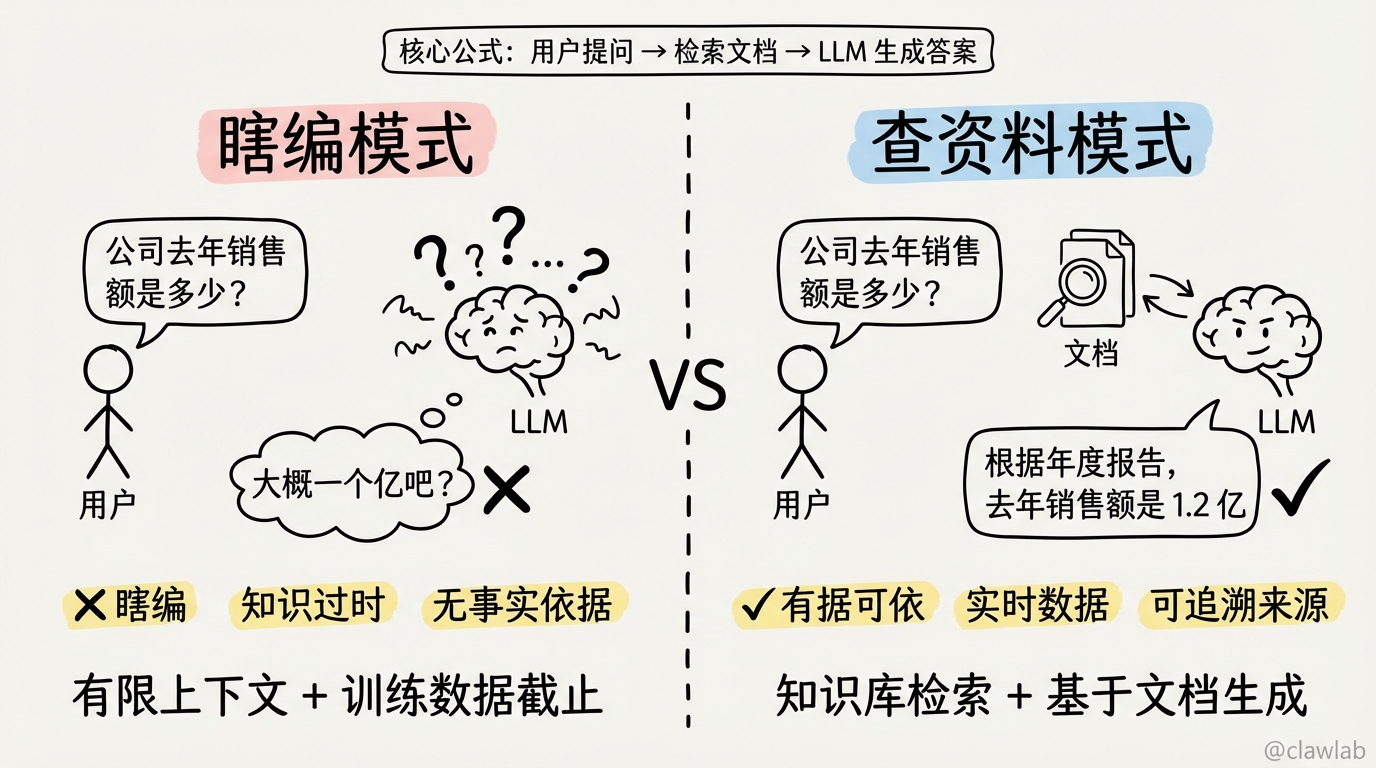
想象你是一个刚入职的新员工,老板问你:"公司去年的销售数据是多少?"
你会怎么回答?
❌ 瞎编:"大概一个亿吧?"(你根本不知道)
✅ 查资料:找到公司内部报表,然后回答:"根据年度报告,去年销售额是 1.2 亿"
大语言模型(LLM)也面临同样的问题:
- 有限上下文 —— 不能一次性读完所有文档
- 知识过时 —— 训练数据截止到某个时间点
RAG(Retrieval-Augmented Generation) 就是让 AI 学会"查资料再回答":
用户提问 → 从知识库检索相关文档 → 把文档给 LLM → LLM 基于文档回答这样 AI 的回答就有了事实依据,不再是"一本正经地胡说八道"。
本节目标
- 理解 RAG 的核心原理和价值
- 掌握知识库构建的完整流程
- 区分三种 RAG 架构:2-Step、Agentic、Hybrid
- 学会根据场景选择合适的架构
业务场景
假设你要构建一个企业知识问答系统:
- 员工问:"公司的报销流程是什么?" → 查公司制度文档
- 员工问:"项目 A 的技术方案是什么?" → 查项目文档
- 员工问:"上周五谁批准了这个需求?" → 查审批记录
这些信息都在公司内部,ChatGPT 不知道。你需要:
- 构建知识库 —— 把公司文档转成可搜索的形式
- 实现检索 —— 根据问题找到相关文档
- 生成回答 —— LLM 基于检索结果回答
核心概念:检索流水线
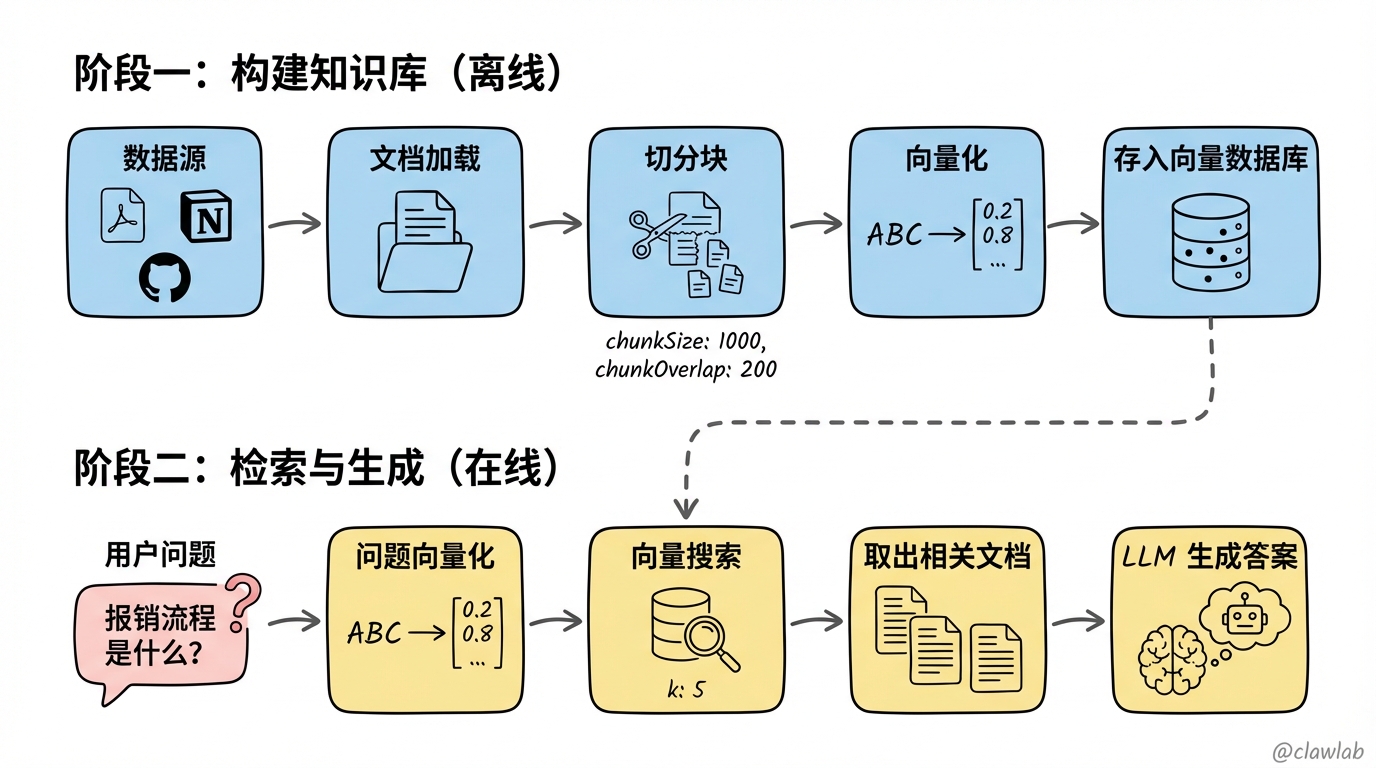
RAG 的工作流程分为两大阶段:
阶段一:构建知识库(离线)
数据源 → 文档加载 → 切分块 → 向量化 → 存入向量数据库typescript
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
const loader = new PDFLoader("./company-handbook.pdf");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200
});
const chunks = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings();
const vectorStore = await MemoryVectorStore.fromDocuments(chunks, embeddings);阶段二:检索与生成(在线)
用户问题 → 向量化 → 在向量库中搜索 → 取出相关文档 → 交给 LLM 生成答案typescript
const retriever = vectorStore.asRetriever({ k: 5 });
const relevantDocs = await retriever.invoke("公司报销流程是什么?");
const context = relevantDocs.map(doc => doc.pageContent).join("\n\n");
const answer = await model.invoke([
{
role: "system",
content: `基于以下上下文回答问题。如果上下文中没有相关信息,就说"我不知道"。
上下文:
${context}`
},
{ role: "user", content: "公司报销流程是什么?" }
]);
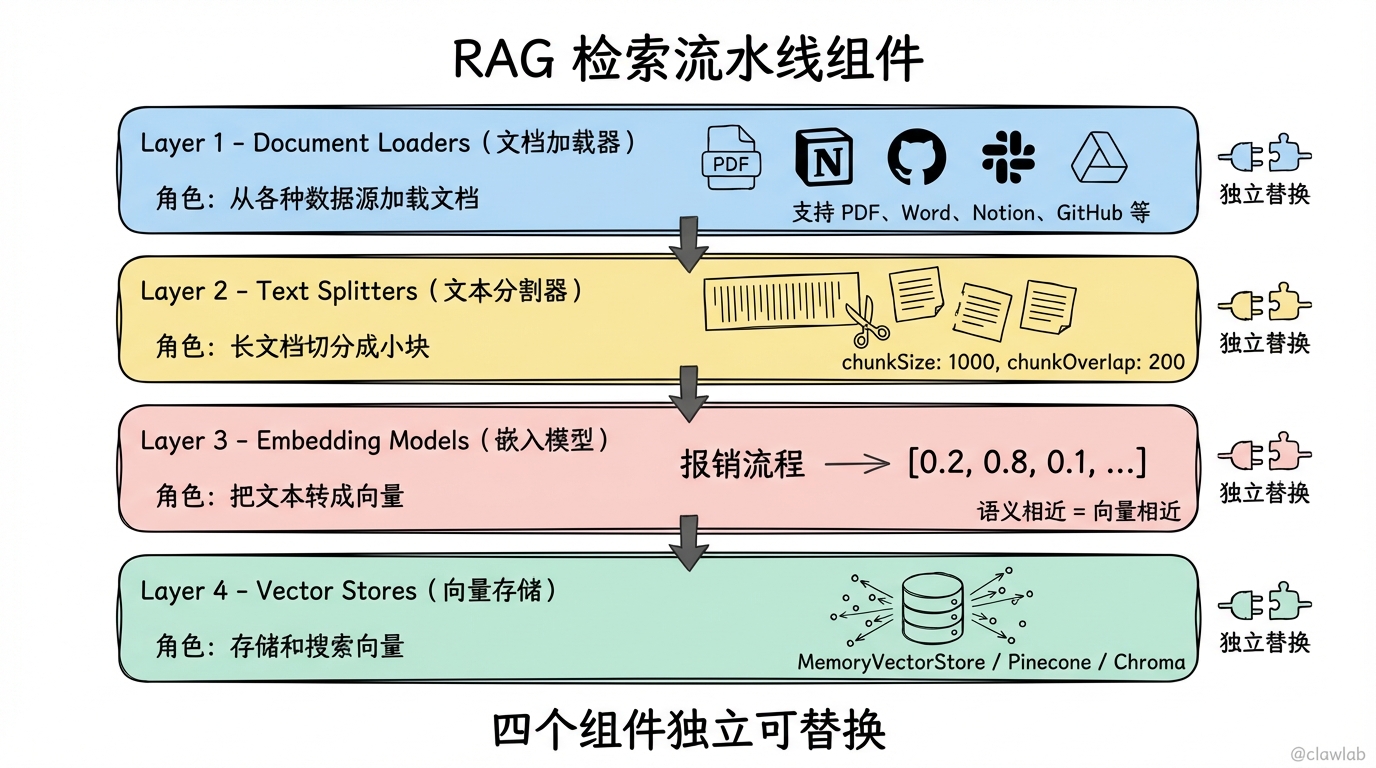
检索流水线组件
RAG 系统由四个核心组件组成,每个都可以独立替换:
1. 文档加载器(Document Loaders)
从各种数据源加载文档:
typescript
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { NotionLoader } from "@langchain/community/document_loaders/notion";
import { GithubRepoLoader } from "@langchain/community/document_loaders/github";
const pdfDocs = await new PDFLoader("./report.pdf").load();
const notionDocs = await new NotionLoader({ ... }).load();
const githubDocs = await new GithubRepoLoader("https://github.com/org/repo").load();支持的数据源包括:PDF、Word、Notion、Slack、Google Drive、GitHub 等。
2. 文本分割器(Text Splitters)
长文档需要切分成小块才能有效检索:
typescript
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
separators: ["\n\n", "\n", "。", ".", " "]
});
const chunks = await splitter.splitDocuments(docs);为什么要切分?
- LLM 上下文窗口有限
- 小块更精确,减少干扰信息
- 切分后可以定位具体段落
3. 嵌入模型(Embedding Models)
把文本转成向量,语义相近的文本向量也相近:
typescript
import { OpenAIEmbeddings } from "@langchain/openai";
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small"
});
const vector = await embeddings.embedQuery("什么是报销流程?");4. 向量存储(Vector Stores)
专门存储和搜索向量的数据库:
typescript
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
import { PineconeStore } from "@langchain/pinecone";
import { ChromaStore } from "@langchain/community/vectorstores/chroma";
const memoryStore = await MemoryVectorStore.fromDocuments(docs, embeddings);
const pineconeStore = await PineconeStore.fromDocuments(docs, embeddings, {
pineconeIndex: myPineconeIndex
});
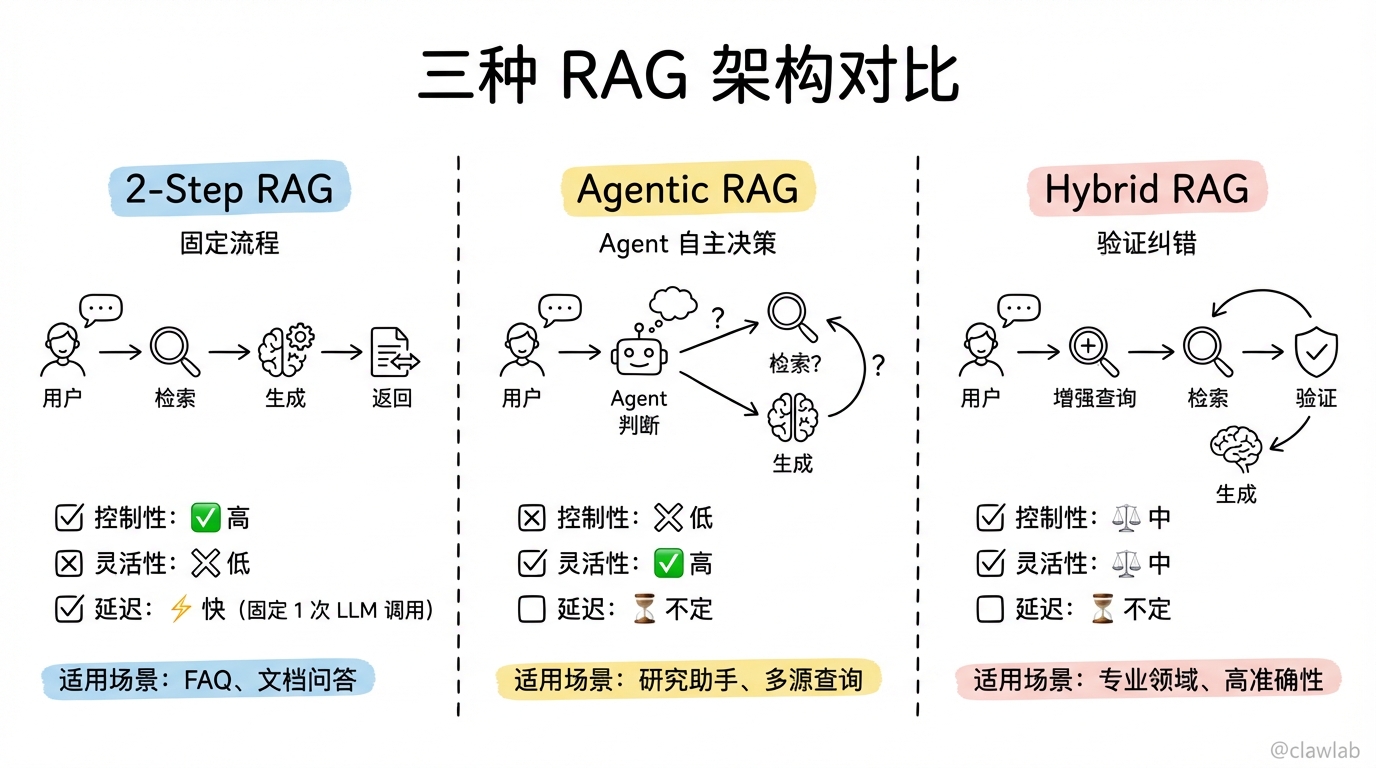
三种 RAG 架构
根据检索和生成的协作方式,RAG 分为三种架构:
| 架构 | 特点 | 控制性 | 灵活性 | 延迟 |
|---|---|---|---|---|
| 2-Step RAG | 先检索,后生成 | ✅ 高 | ❌ 低 | ⚡ 快 |
| Agentic RAG | Agent 决定何时检索 | ❌ 低 | ✅ 高 | ⏳ 不定 |
| Hybrid RAG | 混合,有验证步骤 | ⚖️ 中 | ⚖️ 中 | ⏳ 不定 |
架构 1:2-Step RAG
最简单的架构 —— 固定流程:先检索,后生成。
用户问题 → 检索相关文档 → 生成答案 → 返回给用户typescript
import { ChatOpenAI } from "@langchain/openai";
const model = new ChatOpenAI({ model: "gpt-4.1" });
async function twoStepRAG(question: string) {
const docs = await retriever.invoke(question);
const context = docs.map(d => d.pageContent).join("\n\n");
const response = await model.invoke([
{
role: "system",
content: `基于以下上下文回答问题。
上下文:
${context}
如果上下文中没有相关信息,请说明。`
},
{ role: "user", content: question }
]);
return response.content;
}
const answer = await twoStepRAG("公司年假政策是什么?");优点:
- 简单可预测
- 延迟稳定(固定 1 次 LLM 调用)
- 容易调试
缺点:
- 不灵活,每次都必须检索
- 检索结果不好时没有补救机会
适用场景:FAQ、文档问答、知识库查询
架构 2:Agentic RAG
Agent 自己决定何时检索、检索什么。
用户问题 → Agent 判断 → 需要检索?
↓ 是
使用检索工具 → 信息够吗?
↓ 不够
继续检索...
↓ 够了
生成答案 → 返回给用户typescript
import { createAgent, tool } from "langchain";
import * as z from "zod";
const searchKnowledgeBase = tool(
async ({ query }) => {
const docs = await retriever.invoke(query);
return docs.map(d => d.pageContent).join("\n\n---\n\n");
},
{
name: "search_knowledge_base",
description: "搜索公司知识库,获取政策、流程、项目等信息",
schema: z.object({
query: z.string().describe("搜索查询")
})
}
);
const fetchLatestNews = tool(
async ({ topic }) => {
return `关于 ${topic} 的最新消息...`;
},
{
name: "fetch_latest_news",
description: "获取最新行业新闻和动态",
schema: z.object({
topic: z.string().describe("新闻主题")
})
}
);
const ragAgent = createAgent({
model: "gpt-4.1",
tools: [searchKnowledgeBase, fetchLatestNews],
systemPrompt: `你是一个企业知识助手。
回答问题时:
1. 如果问题涉及公司内部信息(政策、流程、项目),使用 search_knowledge_base
2. 如果需要最新的外部信息,使用 fetch_latest_news
3. 如果是常识性问题,可以直接回答
始终基于检索到的信息回答,不要编造。`
});
const response = await ragAgent.invoke({
messages: [{ role: "user", content: "公司最近有什么新政策?" }]
});优点:
- 灵活,Agent 自主判断
- 可以多次检索,直到信息充足
- 可以结合多种工具
缺点:
- 延迟不可预测
- 可能过度检索或检索不当
- 调试困难
适用场景:复杂问答、研究助手、多源信息整合
架构 3:Hybrid RAG
结合两者优点,增加验证和纠错步骤。
用户问题 → 查询增强 → 检索文档 → 信息足够?
↓ 不够
优化查询 → 重新检索
↓ 够了
生成答案 → 答案质量OK?
↓ 不OK
重新生成或换方法
↓ OK
返回给用户typescript
import { StateGraph, START, END, Annotation } from "@langchain/langgraph";
const State = Annotation.Root({
question: Annotation<string>(),
enhancedQuery: Annotation<string>(),
documents: Annotation<string[]>(),
answer: Annotation<string>(),
isDocsSufficient: Annotation<boolean>(),
isAnswerGood: Annotation<boolean>(),
retryCount: Annotation<number>()
});
async function enhanceQuery(state: typeof State.State) {
const enhanced = await model.invoke([
{
role: "system",
content: "优化用户查询,使其更适合知识库检索。输出优化后的查询。"
},
{ role: "user", content: state.question }
]);
return { enhancedQuery: enhanced.content };
}
async function retrieveDocuments(state: typeof State.State) {
const docs = await retriever.invoke(state.enhancedQuery);
return { documents: docs.map(d => d.pageContent) };
}
async function validateDocuments(state: typeof State.State) {
const validation = await model.withStructuredOutput(z.object({
isSufficient: z.boolean(),
reason: z.string()
})).invoke([
{
role: "system",
content: "判断检索到的文档是否足够回答问题。"
},
{
role: "user",
content: `问题:${state.question}\n\n文档:${state.documents.join("\n")}`
}
]);
return { isDocsSufficient: validation.isSufficient };
}
async function generateAnswer(state: typeof State.State) {
const response = await model.invoke([
{
role: "system",
content: `基于以下文档回答问题:\n${state.documents.join("\n\n")}`
},
{ role: "user", content: state.question }
]);
return { answer: response.content };
}
async function validateAnswer(state: typeof State.State) {
const validation = await model.withStructuredOutput(z.object({
isGood: z.boolean(),
feedback: z.string()
})).invoke([
{
role: "system",
content: "评估答案质量:是否准确、完整、基于文档。"
},
{
role: "user",
content: `问题:${state.question}\n答案:${state.answer}\n文档:${state.documents.join("\n")}`
}
]);
return { isAnswerGood: validation.isGood };
}
function routeAfterDocValidation(state: typeof State.State) {
if (state.isDocsSufficient) return "generateAnswer";
if (state.retryCount >= 2) return "generateAnswer";
return "enhanceQuery";
}
function routeAfterAnswerValidation(state: typeof State.State) {
if (state.isAnswerGood) return "end";
if (state.retryCount >= 2) return "end";
return "generateAnswer";
}
const hybridRAG = new StateGraph(State)
.addNode("enhanceQuery", enhanceQuery)
.addNode("retrieveDocuments", retrieveDocuments)
.addNode("validateDocuments", validateDocuments)
.addNode("generateAnswer", generateAnswer)
.addNode("validateAnswer", validateAnswer)
.addEdge(START, "enhanceQuery")
.addEdge("enhanceQuery", "retrieveDocuments")
.addEdge("retrieveDocuments", "validateDocuments")
.addConditionalEdges("validateDocuments", routeAfterDocValidation)
.addEdge("generateAnswer", "validateAnswer")
.addConditionalEdges("validateAnswer", routeAfterAnswerValidation)
.compile();优点:
- 有质量保证
- 可以自我纠错
- 兼顾控制性和灵活性
缺点:
- 实现复杂
- 延迟较高
- 需要设计验证逻辑
适用场景:高质量要求的问答、专业领域、需要准确性保证的场景
完整示例:企业知识问答系统
typescript
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "@langchain/classic/vectorstores/memory";
import { createAgent, tool } from "langchain";
import * as z from "zod";
const loader = new PDFLoader("./company-handbook.pdf");
const docs = await loader.load();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200
});
const chunks = await splitter.splitDocuments(docs);
const embeddings = new OpenAIEmbeddings();
const vectorStore = await MemoryVectorStore.fromDocuments(chunks, embeddings);
const retriever = vectorStore.asRetriever({ k: 5 });
const searchCompanyDocs = tool(
async ({ query }) => {
const results = await retriever.invoke(query);
if (results.length === 0) {
return "未找到相关信息。";
}
return results.map((doc, i) =>
`[文档 ${i + 1}]\n${doc.pageContent}`
).join("\n\n---\n\n");
},
{
name: "search_company_docs",
description: `搜索公司内部文档。
可搜索内容包括:
- 公司政策(休假、报销、福利等)
- 工作流程(审批、报告、会议等)
- 组织架构(部门、职责、联系方式等)`,
schema: z.object({
query: z.string().describe("搜索关键词或问题")
})
}
);
const knowledgeBot = createAgent({
model: "gpt-4.1",
tools: [searchCompanyDocs],
systemPrompt: `你是公司内部知识助手。
工作原则:
1. 用户询问公司相关问题时,必须先搜索文档
2. 基于搜索结果回答,不要编造信息
3. 如果搜索不到相关信息,明确告知用户
4. 引用时说明来源:"根据公司手册..."
回答风格:
- 简洁明了
- 分点列出重要信息
- 如有疑问,建议联系相关部门`
});
async function chat() {
const questions = [
"公司的年假政策是什么?",
"如何申请报销?",
"IT 部门的联系方式是什么?"
];
for (const question of questions) {
console.log(`\n问:${question}`);
const response = await knowledgeBot.invoke({
messages: [{ role: "user", content: question }]
});
console.log(`答:${response.messages.at(-1)?.content}`);
}
}
chat();已有知识库怎么办?
如果你已经有现成的知识库(SQL 数据库、CRM、Wiki 等),不需要重建!
两种接入方式:
方式 1:包装成工具(Agentic RAG)
typescript
const searchCRM = tool(
async ({ customerId }) => {
const result = await crmApi.getCustomer(customerId);
return JSON.stringify(result);
},
{
name: "search_crm",
description: "查询客户信息",
schema: z.object({ customerId: z.string() })
}
);
const agent = createAgent({
tools: [searchCRM, searchKnowledgeBase, searchWiki]
});方式 2:查询后提供上下文(2-Step RAG)
typescript
async function answerWithExistingKB(question: string) {
const sqlResult = await db.query(`SELECT * FROM faq WHERE question LIKE '%${question}%'`);
const response = await model.invoke([
{
role: "system",
content: `基于以下数据库查询结果回答问题:\n${JSON.stringify(sqlResult)}`
},
{ role: "user", content: question }
]);
return response.content;
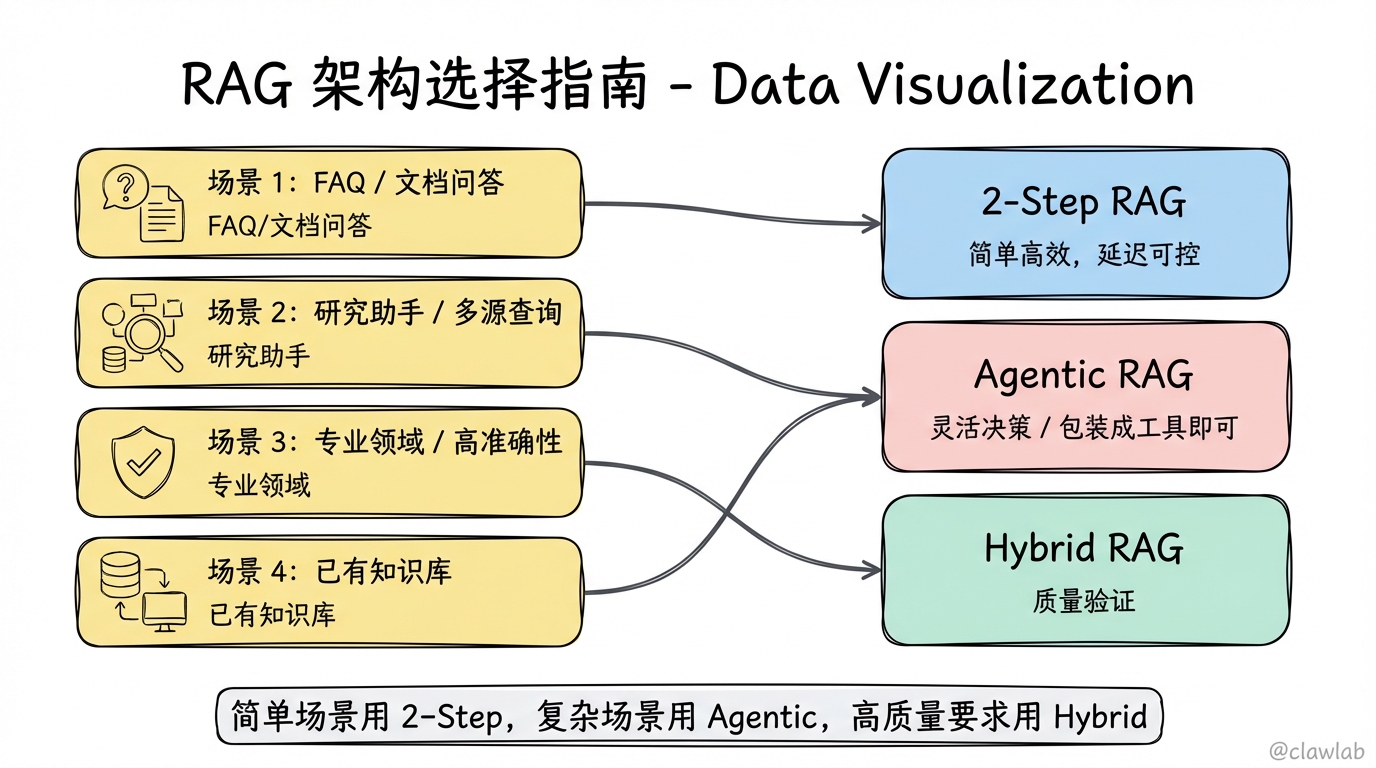
}如何选择 RAG 架构?
| 场景 | 推荐架构 | 原因 |
|---|---|---|
| FAQ / 文档问答 | 2-Step RAG | 简单高效,延迟可控 |
| 研究助手 / 多源查询 | Agentic RAG | 需要灵活决策 |
| 专业领域 / 高准确性 | Hybrid RAG | 需要质量验证 |
| 已有知识库 | Agentic RAG | 包装成工具即可 |
常见问题
Q1:检索结果不准确怎么办?
- 优化切分策略 —— 调整 chunkSize 和 overlap
- 改进嵌入模型 —— 尝试不同的 embedding 模型
- 查询增强 —— 重写用户查询,增加关键词
- 混合检索 —— 结合关键词搜索和向量搜索
Q2:知识库很大,向量存储选哪个?
- 开发/测试:MemoryVectorStore
- 小规模生产:Chroma、SQLite-VSS
- 大规模生产:Pinecone、Weaviate、Milvus
Q3:如何保证答案基于文档?
- 系统提示明确要求 —— "只基于上下文回答"
- 添加引用 —— 要求 LLM 标注来源
- 答案验证 —— Hybrid RAG 的验证步骤
本章小结
RAG 的核心要点:
解决的问题:
- LLM 知识有限且过时
- 让 AI 基于你的数据回答
检索流水线:
- 文档加载 → 切分 → 向量化 → 存储
- 查询 → 检索 → 生成
三种架构:
- 2-Step RAG:固定流程,简单高效
- Agentic RAG:Agent 自主决策,灵活
- Hybrid RAG:有验证步骤,高质量
核心组件:
- Document Loaders:加载各种数据源
- Text Splitters:切分长文档
- Embedding Models:文本向量化
- Vector Stores:存储和搜索向量
选择建议:
- 简单场景用 2-Step
- 复杂场景用 Agentic
- 高质量要求用 Hybrid
RAG 是构建企业级 AI 应用的核心技术,掌握它就能让 AI 真正服务于你的业务数据!