
主题
LangChain 教程 34|项目实战:AI 研究助手
📖 本篇导读:这是 LangChain 系列教程的第 34 篇。本篇将构建一个 AI 研究助手,支持多源文献检索、自动摘要提取、观点对比分析和研究报告撰写。读完预计需要 25 分钟。
项目概述
难度:⭐⭐⭐⭐⭐
核心功能:
- 多源文献检索:学术数据库、论文仓库、网络资源
- 自动摘要提取:从长文档中提取关键信息
- 观点对比分析:比较不同文献的观点异同
- 研究报告撰写:生成结构化的研究报告
技术栈:
- AI 框架:LangChain 1.x + LangGraph
- Agent 架构:Agentic RAG + Subagents + MCP + 上下文管理
- 前端:React 18 + TypeScript + Ant Design + Zustand
- 后端:Express + Prisma + MySQL + Redis
- 向量数据库:Chroma
- 文档处理:PDF.js + Mammoth
第一部分:架构设计
1.1 什么是 Agentic RAG?
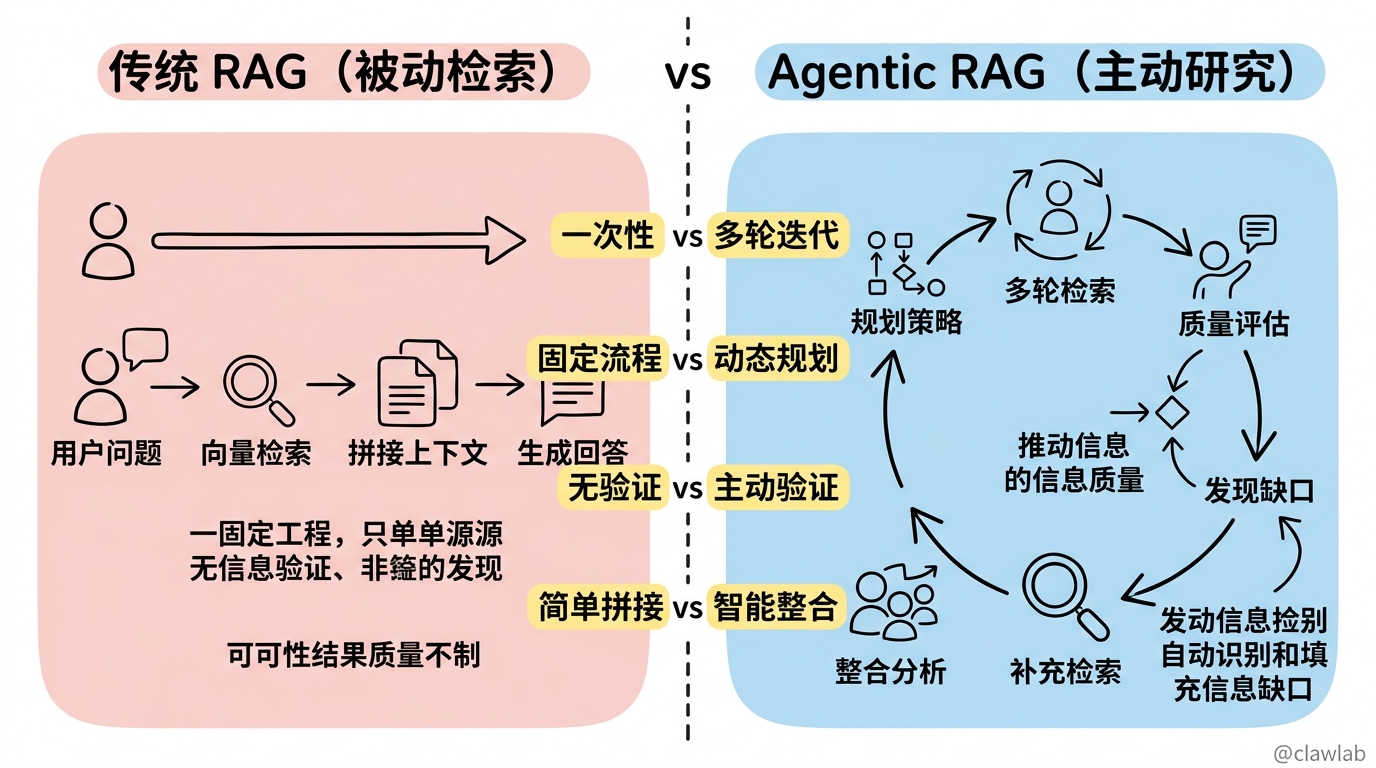
传统 RAG vs Agentic RAG
传统 RAG 是一个相对被动的检索-生成流程:
传统 RAG:
用户问题 → 向量检索 → 拼接上下文 → 生成回答Agentic RAG 则是一个主动、智能的研究过程:
Agentic RAG:
用户问题 → 规划检索策略 → 多轮主动检索 → 验证信息质量
→ 发现信息缺口 → 补充检索 → 整合分析 → 生成回答核心区别:
| 特性 | 传统 RAG | Agentic RAG |
|---|---|---|
| 检索方式 | 一次性检索 | 多轮迭代检索 |
| 策略制定 | 固定流程 | 动态规划 |
| 信息验证 | 无 | 主动验证 |
| 缺口发现 | 无 | 自动识别并补充 |
| 来源整合 | 简单拼接 | 智能整合去重 |
生活化比喻:
传统 RAG 像是图书馆的自动借书机器 —— 你说要借什么书,它就去书架上拿。
Agentic RAG 像是一个研究生助理:
- 你说"我想研究量子计算的最新进展"
- 他先思考:"量子计算?我应该看计算机期刊、物理期刊,还有看看谷歌、IBM 的最新论文"
- 他去不同地方搜索,找到一些论文
- 读完发现:"这篇提到了 error correction,但没详细说,我应该再找找这方面的资料"
- 继续搜索,补充信息
- 最后整理所有材料,给你一份完整的研究报告
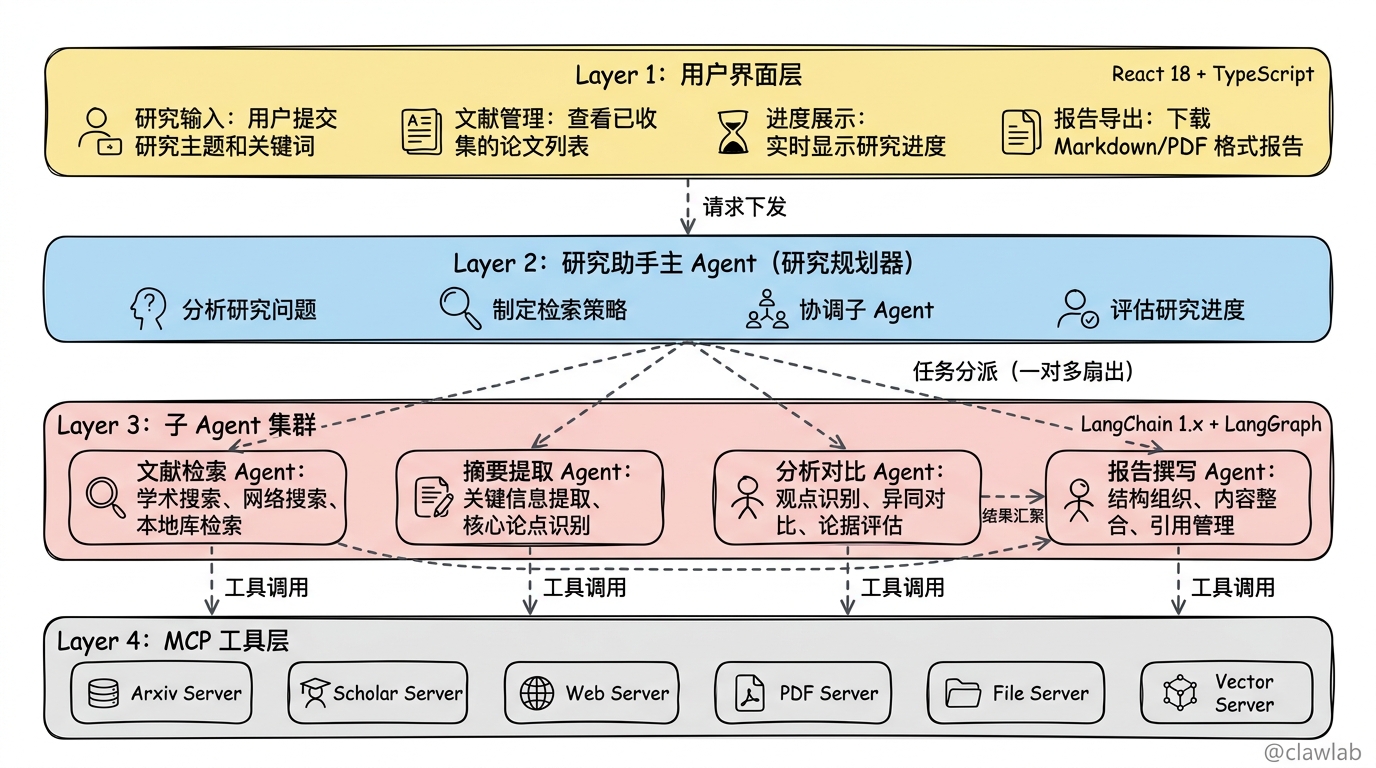
1.2 系统整体架构
┌─────────────────────────────────────────────────────────────┐
│ 用户界面层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 研究输入 │ │ 文献管理 │ │ 进度展示 │ │ 报告导出 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 研究助手主 Agent │
│ ┌─────────────────────────────────────────────────────────┐│
│ │ 研究规划器 ││
│ │ • 分析研究问题 ││
│ │ • 制定检索策略 ││
│ │ • 协调子 Agent ││
│ │ • 评估研究进度 ││
│ └─────────────────────────────────────────────────────────┘│
└─────────────────────────────────────────────────────────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 文献检索 Agent │ │ 摘要提取 Agent │ │ 分析对比 Agent │
│ │ │ │ │ │
│ • 学术搜索 │ │ • 关键信息提取 │ │ • 观点识别 │
│ • 网络搜索 │ │ • 核心论点识别 │ │ • 异同对比 │
│ • 本地库检索 │ │ • 方法论提取 │ │ • 论据评估 │
│ • 结果排序过滤 │ │ • 结论总结 │ │ • 关系图谱 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
└───────────────────┼───────────────────┘
▼
┌─────────────────┐
│ 报告撰写 Agent │
│ │
│ • 结构组织 │
│ • 内容整合 │
│ • 引用管理 │
│ • 格式输出 │
└─────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ 上下文管理层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 会话历史 │ │ 文献缓存 │ │ 检索状态 │ │ 报告草稿 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ MCP 工具层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 学术搜索 │ │ 网络搜索 │ │ PDF 处理 │ │ 文件系统 │ │
│ │ Server │ │ Server │ │ Server │ │ Server │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
1.3 Agentic RAG 工作流详解
┌───────────────────────────────────────────────────────────────┐
│ Agentic RAG 工作流 │
├───────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ │
│ │ START │ │
│ └────┬────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 问题分析 │ ← 理解研究主题,识别关键概念 │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 策略规划 │ ← 确定检索源、关键词、优先级 │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ 执行检索 │───────→│ 质量评估 │ │
│ └────────┬────────┘ └────────┬────────┘ │
│ │ │ │
│ │ ▼ │
│ │ ┌─────────────────┐ │
│ │ │ 信息是否充足? │ │
│ │ └────────┬────────┘ │
│ │ ┌─────┴─────┐ │
│ │ │ │ │
│ │ 否 是 │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌───────────────┐ │ │
│ │ │ 发现信息缺口 │ │ │
│ │ └───────┬───────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌───────────────┐ │ │
│ └───────────│ 补充检索策略 │ │ │
│ └───────────────┘ │ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 信息整合 │ │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 生成报告 │ │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────┐ │
│ │ END │ │
│ └─────────┘ │
│ │
└───────────────────────────────────────────────────────────────┘1.4 数据库设计
prisma
// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
// 用户表
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
passwordHash String
projects ResearchProject[]
papers Paper[]
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
// 研究项目
model ResearchProject {
id Int @id @default(autoincrement())
userId Int
user User @relation(fields: [userId], references: [id])
title String
description String? @db.Text
topic String
keywords String @db.Text // JSON array
status String @default("active") // active, completed, archived
papers ProjectPaper[]
reports ResearchReport[]
sessions ResearchSession[]
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
@@index([userId])
@@index([status])
}
// 论文/文献
model Paper {
id Int @id @default(autoincrement())
userId Int
user User @relation(fields: [userId], references: [id])
title String @db.Text
authors String @db.Text // JSON array
abstract String? @db.LongText
content String? @db.LongText
source String // arxiv, semantic_scholar, google_scholar, web, local
sourceUrl String? @db.Text
sourceId String? // 外部ID
doi String?
publishedAt DateTime?
venue String? // 期刊/会议名称
citations Int @default(0)
// 处理状态
isProcessed Boolean @default(false)
summary String? @db.LongText // AI 生成的摘要
keyPoints String? @db.LongText // JSON array,关键观点
methodology String? @db.Text // 方法论
conclusions String? @db.Text // 结论
// 向量嵌入
embeddingId String? // Chroma 中的 ID
projects ProjectPaper[]
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
@@unique([source, sourceId])
@@index([userId])
@@index([source])
@@index([isProcessed])
}
// 项目-论文关联表
model ProjectPaper {
id Int @id @default(autoincrement())
projectId Int
project ResearchProject @relation(fields: [projectId], references: [id])
paperId Int
paper Paper @relation(fields: [paperId], references: [id])
relevance Float @default(0) // 相关性评分
notes String? @db.Text // 用户笔记
tags String? @db.Text // JSON array
createdAt DateTime @default(now())
@@unique([projectId, paperId])
@@index([projectId])
@@index([paperId])
}
// 研究报告
model ResearchReport {
id Int @id @default(autoincrement())
projectId Int
project ResearchProject @relation(fields: [projectId], references: [id])
title String
content String @db.LongText
format String @default("markdown") // markdown, html, pdf
version Int @default(1)
// 报告结构
outline String? @db.LongText // JSON,报告大纲
sections String? @db.LongText // JSON,各节内容
references String? @db.LongText // JSON,引用列表
status String @default("draft") // draft, final
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
@@index([projectId])
@@index([status])
}
// 研究会话
model ResearchSession {
id Int @id @default(autoincrement())
projectId Int
project ResearchProject @relation(fields: [projectId], references: [id])
messages Message[]
// 会话上下文
context String? @db.LongText // JSON,当前研究上下文
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
@@index([projectId])
}
// 对话消息
model Message {
id Int @id @default(autoincrement())
sessionId Int
session ResearchSession @relation(fields: [sessionId], references: [id])
role String // user, assistant, system
content String @db.LongText
// 元数据
metadata String? @db.LongText // JSON,包含搜索结果、引用等
createdAt DateTime @default(now())
@@index([sessionId])
}
// 检索记录
model SearchLog {
id Int @id @default(autoincrement())
projectId Int?
query String @db.Text
source String // 搜索源
results Int // 结果数量
duration Int // 耗时(毫秒)
createdAt DateTime @default(now())
@@index([projectId])
@@index([source])
}第二部分:MCP 集成 - 多源文献检索
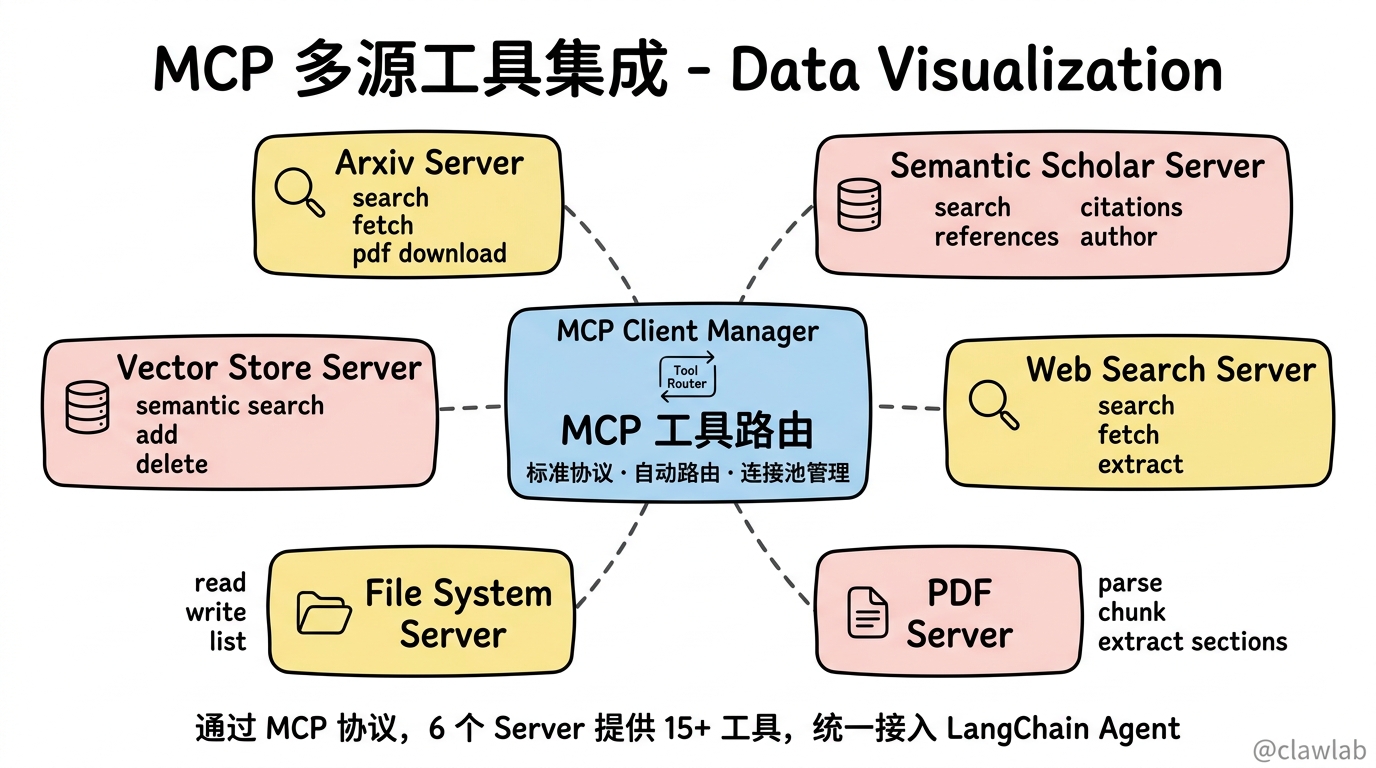
2.1 MCP 服务架构
MCP(Model Context Protocol)为我们提供了标准化的工具接口。研究助手需要对接多个数据源:
┌─────────────────────────────────────────────────────────────┐
│ MCP Client Manager │
│ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Tool Router │ │
│ │ 根据工具名称路由到正确的 MCP Server │ │
│ └────────────────────────────────────────────────────┘ │
│ │ │
│ ┌────────────────────┼────────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Arxiv │ │ Scholar │ │ Web │ │
│ │ Server │ │ Server │ │ Server │ │
│ ├─────────┤ ├─────────┤ ├─────────┤ │
│ │• search │ │• search │ │• search │ │
│ │• fetch │ │• cite │ │• fetch │ │
│ │• pdf │ │• author │ │• extract│ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │
│ ┌────────────────────┼────────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ PDF │ │ File │ │ Vector │ │
│ │ Server │ │ Server │ │ Server │ │
│ ├─────────┤ ├─────────┤ ├─────────┤ │
│ │• parse │ │• read │ │• search │ │
│ │• extract│ │• write │ │• add │ │
│ │• chunk │ │• list │ │• delete │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
2.2 学术搜索 MCP Server
typescript
// src/mcp/servers/arxiv-server.ts
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import {
CallToolRequestSchema,
ListToolsRequestSchema,
Tool,
} from '@modelcontextprotocol/sdk/types.js';
import axios from 'axios';
import { XMLParser } from 'fast-xml-parser';
interface ArxivPaper {
id: string;
title: string;
authors: string[];
abstract: string;
published: string;
updated: string;
categories: string[];
pdfUrl: string;
doi?: string;
}
interface SearchResult {
papers: ArxivPaper[];
totalResults: number;
query: string;
}
const ARXIV_API_URL = 'http://export.arxiv.org/api/query';
async function searchArxiv(
query: string,
maxResults: number = 10,
start: number = 0,
sortBy: 'relevance' | 'lastUpdatedDate' | 'submittedDate' = 'relevance'
): Promise<SearchResult> {
const params = new URLSearchParams({
search_query: `all:${query}`,
start: start.toString(),
max_results: maxResults.toString(),
sortBy,
sortOrder: 'descending',
});
const response = await axios.get(`${ARXIV_API_URL}?${params}`);
const parser = new XMLParser({
ignoreAttributes: false,
attributeNamePrefix: '@_',
});
const result = parser.parse(response.data);
const feed = result.feed;
if (!feed.entry) {
return { papers: [], totalResults: 0, query };
}
const entries = Array.isArray(feed.entry) ? feed.entry : [feed.entry];
const papers: ArxivPaper[] = entries.map((entry: any) => {
const authors = Array.isArray(entry.author)
? entry.author.map((a: any) => a.name)
: [entry.author?.name || 'Unknown'];
const categories = Array.isArray(entry.category)
? entry.category.map((c: any) => c['@_term'])
: [entry.category?.['@_term'] || 'Unknown'];
const links = Array.isArray(entry.link) ? entry.link : [entry.link];
const pdfLink = links.find((l: any) => l['@_title'] === 'pdf');
return {
id: entry.id.split('/abs/').pop() || entry.id,
title: entry.title.replace(/\n/g, ' ').trim(),
authors,
abstract: entry.summary.replace(/\n/g, ' ').trim(),
published: entry.published,
updated: entry.updated,
categories,
pdfUrl: pdfLink?.['@_href'] || `https://arxiv.org/pdf/${entry.id.split('/abs/').pop()}`,
doi: entry['arxiv:doi']?.['#text'],
};
});
const totalResults = parseInt(feed['opensearch:totalResults'] || '0', 10);
return { papers, totalResults, query };
}
async function fetchPaperDetails(arxivId: string): Promise<ArxivPaper | null> {
const params = new URLSearchParams({
id_list: arxivId,
});
const response = await axios.get(`${ARXIV_API_URL}?${params}`);
const parser = new XMLParser({
ignoreAttributes: false,
attributeNamePrefix: '@_',
});
const result = parser.parse(response.data);
const entry = result.feed.entry;
if (!entry) {
return null;
}
const authors = Array.isArray(entry.author)
? entry.author.map((a: any) => a.name)
: [entry.author?.name || 'Unknown'];
const categories = Array.isArray(entry.category)
? entry.category.map((c: any) => c['@_term'])
: [entry.category?.['@_term'] || 'Unknown'];
return {
id: arxivId,
title: entry.title.replace(/\n/g, ' ').trim(),
authors,
abstract: entry.summary.replace(/\n/g, ' ').trim(),
published: entry.published,
updated: entry.updated,
categories,
pdfUrl: `https://arxiv.org/pdf/${arxivId}`,
doi: entry['arxiv:doi']?.['#text'],
};
}
async function downloadPdf(arxivId: string): Promise<Buffer> {
const pdfUrl = `https://arxiv.org/pdf/${arxivId}.pdf`;
const response = await axios.get(pdfUrl, {
responseType: 'arraybuffer',
});
return Buffer.from(response.data);
}
const tools: Tool[] = [
{
name: 'arxiv_search',
description: 'Search for academic papers on arXiv. Returns paper titles, authors, abstracts, and links.',
inputSchema: {
type: 'object',
properties: {
query: {
type: 'string',
description: 'Search query for finding papers',
},
maxResults: {
type: 'number',
description: 'Maximum number of results to return (default: 10, max: 50)',
default: 10,
},
sortBy: {
type: 'string',
enum: ['relevance', 'lastUpdatedDate', 'submittedDate'],
description: 'Sort order for results',
default: 'relevance',
},
},
required: ['query'],
},
},
{
name: 'arxiv_fetch',
description: 'Fetch detailed information about a specific arXiv paper by its ID',
inputSchema: {
type: 'object',
properties: {
arxivId: {
type: 'string',
description: 'arXiv paper ID (e.g., "2301.00234" or "cs.AI/0601001")',
},
},
required: ['arxivId'],
},
},
{
name: 'arxiv_download_pdf',
description: 'Download the PDF of an arXiv paper. Returns the PDF as base64.',
inputSchema: {
type: 'object',
properties: {
arxivId: {
type: 'string',
description: 'arXiv paper ID',
},
},
required: ['arxivId'],
},
},
];
const server = new Server(
{
name: 'arxiv-server',
version: '1.0.0',
},
{
capabilities: {
tools: {},
},
}
);
server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools,
}));
server.setRequestHandler(CallToolRequestSchema, async (request) => {
const { name, arguments: args } = request.params;
try {
switch (name) {
case 'arxiv_search': {
const { query, maxResults = 10, sortBy = 'relevance' } = args as {
query: string;
maxResults?: number;
sortBy?: 'relevance' | 'lastUpdatedDate' | 'submittedDate';
};
const results = await searchArxiv(query, Math.min(maxResults, 50), 0, sortBy);
return {
content: [
{
type: 'text',
text: JSON.stringify(results, null, 2),
},
],
};
}
case 'arxiv_fetch': {
const { arxivId } = args as { arxivId: string };
const paper = await fetchPaperDetails(arxivId);
if (!paper) {
return {
content: [{ type: 'text', text: `Paper not found: ${arxivId}` }],
isError: true,
};
}
return {
content: [
{
type: 'text',
text: JSON.stringify(paper, null, 2),
},
],
};
}
case 'arxiv_download_pdf': {
const { arxivId } = args as { arxivId: string };
const pdfBuffer = await downloadPdf(arxivId);
return {
content: [
{
type: 'text',
text: JSON.stringify({
arxivId,
size: pdfBuffer.length,
base64: pdfBuffer.toString('base64'),
}),
},
],
};
}
default:
return {
content: [{ type: 'text', text: `Unknown tool: ${name}` }],
isError: true,
};
}
} catch (error) {
return {
content: [
{
type: 'text',
text: `Error: ${error instanceof Error ? error.message : 'Unknown error'}`,
},
],
isError: true,
};
}
});
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
}
main().catch(console.error);2.3 Semantic Scholar MCP Server
typescript
// src/mcp/servers/semantic-scholar-server.ts
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import {
CallToolRequestSchema,
ListToolsRequestSchema,
Tool,
} from '@modelcontextprotocol/sdk/types.js';
import axios from 'axios';
interface SemanticScholarPaper {
paperId: string;
title: string;
abstract: string | null;
authors: Array<{ authorId: string; name: string }>;
year: number | null;
venue: string | null;
citationCount: number;
referenceCount: number;
fieldsOfStudy: string[] | null;
url: string;
openAccessPdf: { url: string } | null;
tldr: { text: string } | null;
}
interface SearchResponse {
total: number;
offset: number;
data: SemanticScholarPaper[];
}
interface AuthorInfo {
authorId: string;
name: string;
affiliations: string[];
paperCount: number;
citationCount: number;
hIndex: number;
}
const API_BASE = 'https://api.semanticscholar.org/graph/v1';
const API_KEY = process.env.SEMANTIC_SCHOLAR_API_KEY;
const headers = API_KEY ? { 'x-api-key': API_KEY } : {};
async function searchPapers(
query: string,
limit: number = 10,
fields: string[] = ['paperId', 'title', 'abstract', 'authors', 'year', 'venue', 'citationCount', 'openAccessPdf', 'tldr'],
yearFilter?: { min?: number; max?: number }
): Promise<SearchResponse> {
const params: Record<string, string> = {
query,
limit: limit.toString(),
fields: fields.join(','),
};
if (yearFilter?.min) params.year = `${yearFilter.min}-`;
if (yearFilter?.max) params.year = yearFilter.min ? `${yearFilter.min}-${yearFilter.max}` : `-${yearFilter.max}`;
const response = await axios.get<SearchResponse>(`${API_BASE}/paper/search`, {
params,
headers,
});
return response.data;
}
async function getPaperDetails(paperId: string): Promise<SemanticScholarPaper> {
const fields = [
'paperId', 'title', 'abstract', 'authors', 'year', 'venue',
'citationCount', 'referenceCount', 'fieldsOfStudy', 'url',
'openAccessPdf', 'tldr'
].join(',');
const response = await axios.get<SemanticScholarPaper>(
`${API_BASE}/paper/${paperId}`,
{
params: { fields },
headers,
}
);
return response.data;
}
async function getPaperCitations(
paperId: string,
limit: number = 10
): Promise<{ citingPaper: SemanticScholarPaper }[]> {
const response = await axios.get(
`${API_BASE}/paper/${paperId}/citations`,
{
params: {
fields: 'paperId,title,authors,year,citationCount',
limit: limit.toString(),
},
headers,
}
);
return response.data.data;
}
async function getPaperReferences(
paperId: string,
limit: number = 10
): Promise<{ citedPaper: SemanticScholarPaper }[]> {
const response = await axios.get(
`${API_BASE}/paper/${paperId}/references`,
{
params: {
fields: 'paperId,title,authors,year,citationCount',
limit: limit.toString(),
},
headers,
}
);
return response.data.data;
}
async function getAuthorInfo(authorId: string): Promise<AuthorInfo> {
const response = await axios.get<AuthorInfo>(
`${API_BASE}/author/${authorId}`,
{
params: {
fields: 'authorId,name,affiliations,paperCount,citationCount,hIndex',
},
headers,
}
);
return response.data;
}
async function getAuthorPapers(
authorId: string,
limit: number = 10
): Promise<SemanticScholarPaper[]> {
const response = await axios.get(
`${API_BASE}/author/${authorId}/papers`,
{
params: {
fields: 'paperId,title,year,citationCount,venue',
limit: limit.toString(),
},
headers,
}
);
return response.data.data;
}
const tools: Tool[] = [
{
name: 'semantic_scholar_search',
description: 'Search for academic papers in Semantic Scholar database',
inputSchema: {
type: 'object',
properties: {
query: {
type: 'string',
description: 'Search query for finding papers',
},
limit: {
type: 'number',
description: 'Maximum number of results (default: 10, max: 100)',
default: 10,
},
yearMin: {
type: 'number',
description: 'Minimum publication year',
},
yearMax: {
type: 'number',
description: 'Maximum publication year',
},
},
required: ['query'],
},
},
{
name: 'semantic_scholar_paper_details',
description: 'Get detailed information about a specific paper',
inputSchema: {
type: 'object',
properties: {
paperId: {
type: 'string',
description: 'Semantic Scholar paper ID, DOI, or arXiv ID',
},
},
required: ['paperId'],
},
},
{
name: 'semantic_scholar_citations',
description: 'Get papers that cite a specific paper',
inputSchema: {
type: 'object',
properties: {
paperId: {
type: 'string',
description: 'Semantic Scholar paper ID',
},
limit: {
type: 'number',
description: 'Maximum number of citations to return',
default: 10,
},
},
required: ['paperId'],
},
},
{
name: 'semantic_scholar_references',
description: 'Get papers referenced by a specific paper',
inputSchema: {
type: 'object',
properties: {
paperId: {
type: 'string',
description: 'Semantic Scholar paper ID',
},
limit: {
type: 'number',
description: 'Maximum number of references to return',
default: 10,
},
},
required: ['paperId'],
},
},
{
name: 'semantic_scholar_author',
description: 'Get information about an author and their papers',
inputSchema: {
type: 'object',
properties: {
authorId: {
type: 'string',
description: 'Semantic Scholar author ID',
},
includePapers: {
type: 'boolean',
description: 'Whether to include author papers',
default: false,
},
},
required: ['authorId'],
},
},
];
const server = new Server(
{
name: 'semantic-scholar-server',
version: '1.0.0',
},
{
capabilities: {
tools: {},
},
}
);
server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools,
}));
server.setRequestHandler(CallToolRequestSchema, async (request) => {
const { name, arguments: args } = request.params;
try {
switch (name) {
case 'semantic_scholar_search': {
const { query, limit = 10, yearMin, yearMax } = args as {
query: string;
limit?: number;
yearMin?: number;
yearMax?: number;
};
const yearFilter = yearMin || yearMax ? { min: yearMin, max: yearMax } : undefined;
const results = await searchPapers(query, Math.min(limit, 100), undefined, yearFilter);
return {
content: [{ type: 'text', text: JSON.stringify(results, null, 2) }],
};
}
case 'semantic_scholar_paper_details': {
const { paperId } = args as { paperId: string };
const paper = await getPaperDetails(paperId);
return {
content: [{ type: 'text', text: JSON.stringify(paper, null, 2) }],
};
}
case 'semantic_scholar_citations': {
const { paperId, limit = 10 } = args as { paperId: string; limit?: number };
const citations = await getPaperCitations(paperId, limit);
return {
content: [{ type: 'text', text: JSON.stringify(citations, null, 2) }],
};
}
case 'semantic_scholar_references': {
const { paperId, limit = 10 } = args as { paperId: string; limit?: number };
const references = await getPaperReferences(paperId, limit);
return {
content: [{ type: 'text', text: JSON.stringify(references, null, 2) }],
};
}
case 'semantic_scholar_author': {
const { authorId, includePapers = false } = args as {
authorId: string;
includePapers?: boolean;
};
const authorInfo = await getAuthorInfo(authorId);
let result: any = authorInfo;
if (includePapers) {
const papers = await getAuthorPapers(authorId);
result = { ...authorInfo, papers };
}
return {
content: [{ type: 'text', text: JSON.stringify(result, null, 2) }],
};
}
default:
return {
content: [{ type: 'text', text: `Unknown tool: ${name}` }],
isError: true,
};
}
} catch (error) {
return {
content: [
{
type: 'text',
text: `Error: ${error instanceof Error ? error.message : 'Unknown error'}`,
},
],
isError: true,
};
}
});
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
}
main().catch(console.error);2.4 PDF 处理 MCP Server
typescript
// src/mcp/servers/pdf-server.ts
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import {
CallToolRequestSchema,
ListToolsRequestSchema,
Tool,
} from '@modelcontextprotocol/sdk/types.js';
import * as pdfParse from 'pdf-parse';
import * as fs from 'fs/promises';
import * as path from 'path';
interface PDFMetadata {
title: string | null;
author: string | null;
subject: string | null;
keywords: string | null;
creator: string | null;
producer: string | null;
creationDate: Date | null;
modificationDate: Date | null;
}
interface PDFContent {
text: string;
pages: number;
metadata: PDFMetadata;
}
interface TextChunk {
content: string;
pageNumber: number;
chunkIndex: number;
startChar: number;
endChar: number;
}
async function parsePDF(filePath: string): Promise<PDFContent> {
const absolutePath = path.resolve(filePath);
const dataBuffer = await fs.readFile(absolutePath);
const data = await pdfParse(dataBuffer);
return {
text: data.text,
pages: data.numpages,
metadata: {
title: data.info?.Title || null,
author: data.info?.Author || null,
subject: data.info?.Subject || null,
keywords: data.info?.Keywords || null,
creator: data.info?.Creator || null,
producer: data.info?.Producer || null,
creationDate: data.info?.CreationDate ? new Date(data.info.CreationDate) : null,
modificationDate: data.info?.ModDate ? new Date(data.info.ModDate) : null,
},
};
}
async function parsePDFFromBuffer(buffer: Buffer): Promise<PDFContent> {
const data = await pdfParse(buffer);
return {
text: data.text,
pages: data.numpages,
metadata: {
title: data.info?.Title || null,
author: data.info?.Author || null,
subject: data.info?.Subject || null,
keywords: data.info?.Keywords || null,
creator: data.info?.Creator || null,
producer: data.info?.Producer || null,
creationDate: data.info?.CreationDate ? new Date(data.info.CreationDate) : null,
modificationDate: data.info?.ModDate ? new Date(data.info.ModDate) : null,
},
};
}
function chunkText(
text: string,
chunkSize: number = 1000,
overlap: number = 200
): TextChunk[] {
const chunks: TextChunk[] = [];
const paragraphs = text.split(/\n\n+/);
let currentChunk = '';
let currentStartChar = 0;
let charPosition = 0;
let chunkIndex = 0;
for (const paragraph of paragraphs) {
if (currentChunk.length + paragraph.length > chunkSize && currentChunk.length > 0) {
chunks.push({
content: currentChunk.trim(),
pageNumber: 0,
chunkIndex,
startChar: currentStartChar,
endChar: charPosition,
});
chunkIndex++;
const overlapStart = Math.max(0, currentChunk.length - overlap);
currentChunk = currentChunk.slice(overlapStart);
currentStartChar = charPosition - currentChunk.length;
}
currentChunk += (currentChunk ? '\n\n' : '') + paragraph;
charPosition += paragraph.length + 2;
}
if (currentChunk.trim()) {
chunks.push({
content: currentChunk.trim(),
pageNumber: 0,
chunkIndex,
startChar: currentStartChar,
endChar: charPosition,
});
}
return chunks;
}
function extractSections(text: string): Record<string, string> {
const sections: Record<string, string> = {};
const sectionPatterns = [
/^(abstract|摘要)[:\s]*/im,
/^(introduction|引言|1\.?\s*introduction)[:\s]*/im,
/^(background|背景|related work|相关工作)[:\s]*/im,
/^(method|methodology|方法)[:\s]*/im,
/^(experiment|experiments|实验)[:\s]*/im,
/^(result|results|结果)[:\s]*/im,
/^(discussion|讨论)[:\s]*/im,
/^(conclusion|conclusions|结论)[:\s]*/im,
/^(reference|references|参考文献)[:\s]*/im,
];
const lines = text.split('\n');
let currentSection = 'preamble';
let currentContent: string[] = [];
for (const line of lines) {
let foundSection = false;
for (const pattern of sectionPatterns) {
if (pattern.test(line)) {
if (currentContent.length > 0) {
sections[currentSection] = currentContent.join('\n').trim();
}
const match = line.match(pattern);
currentSection = match ? match[1].toLowerCase() : 'unknown';
currentContent = [];
foundSection = true;
break;
}
}
if (!foundSection) {
currentContent.push(line);
}
}
if (currentContent.length > 0) {
sections[currentSection] = currentContent.join('\n').trim();
}
return sections;
}
const tools: Tool[] = [
{
name: 'pdf_parse',
description: 'Parse a PDF file and extract its text content and metadata',
inputSchema: {
type: 'object',
properties: {
filePath: {
type: 'string',
description: 'Path to the PDF file',
},
},
required: ['filePath'],
},
},
{
name: 'pdf_parse_base64',
description: 'Parse a PDF from base64 encoded content',
inputSchema: {
type: 'object',
properties: {
base64Content: {
type: 'string',
description: 'Base64 encoded PDF content',
},
},
required: ['base64Content'],
},
},
{
name: 'pdf_chunk',
description: 'Split PDF text into overlapping chunks for processing',
inputSchema: {
type: 'object',
properties: {
filePath: {
type: 'string',
description: 'Path to the PDF file',
},
chunkSize: {
type: 'number',
description: 'Target size for each chunk in characters (default: 1000)',
default: 1000,
},
overlap: {
type: 'number',
description: 'Overlap between chunks in characters (default: 200)',
default: 200,
},
},
required: ['filePath'],
},
},
{
name: 'pdf_extract_sections',
description: 'Extract common academic paper sections (abstract, introduction, methods, etc.)',
inputSchema: {
type: 'object',
properties: {
filePath: {
type: 'string',
description: 'Path to the PDF file',
},
},
required: ['filePath'],
},
},
];
const server = new Server(
{
name: 'pdf-server',
version: '1.0.0',
},
{
capabilities: {
tools: {},
},
}
);
server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools,
}));
server.setRequestHandler(CallToolRequestSchema, async (request) => {
const { name, arguments: args } = request.params;
try {
switch (name) {
case 'pdf_parse': {
const { filePath } = args as { filePath: string };
const content = await parsePDF(filePath);
return {
content: [
{
type: 'text',
text: JSON.stringify({
pages: content.pages,
metadata: content.metadata,
textLength: content.text.length,
textPreview: content.text.slice(0, 2000) + (content.text.length > 2000 ? '...' : ''),
}, null, 2),
},
],
};
}
case 'pdf_parse_base64': {
const { base64Content } = args as { base64Content: string };
const buffer = Buffer.from(base64Content, 'base64');
const content = await parsePDFFromBuffer(buffer);
return {
content: [
{
type: 'text',
text: JSON.stringify({
pages: content.pages,
metadata: content.metadata,
textLength: content.text.length,
textPreview: content.text.slice(0, 2000) + (content.text.length > 2000 ? '...' : ''),
}, null, 2),
},
],
};
}
case 'pdf_chunk': {
const { filePath, chunkSize = 1000, overlap = 200 } = args as {
filePath: string;
chunkSize?: number;
overlap?: number;
};
const content = await parsePDF(filePath);
const chunks = chunkText(content.text, chunkSize, overlap);
return {
content: [
{
type: 'text',
text: JSON.stringify({
totalChunks: chunks.length,
chunks: chunks.map(c => ({
...c,
contentPreview: c.content.slice(0, 200) + (c.content.length > 200 ? '...' : ''),
})),
}, null, 2),
},
],
};
}
case 'pdf_extract_sections': {
const { filePath } = args as { filePath: string };
const content = await parsePDF(filePath);
const sections = extractSections(content.text);
return {
content: [
{
type: 'text',
text: JSON.stringify({
sectionsFound: Object.keys(sections),
sections: Object.fromEntries(
Object.entries(sections).map(([key, value]) => [
key,
{
length: value.length,
preview: value.slice(0, 500) + (value.length > 500 ? '...' : ''),
},
])
),
}, null, 2),
},
],
};
}
default:
return {
content: [{ type: 'text', text: `Unknown tool: ${name}` }],
isError: true,
};
}
} catch (error) {
return {
content: [
{
type: 'text',
text: `Error: ${error instanceof Error ? error.message : 'Unknown error'}`,
},
],
isError: true,
};
}
});
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
}
main().catch(console.error);2.5 MCP Client Manager
typescript
// src/mcp/client-manager.ts
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
import { Tool } from '@langchain/core/tools';
import { spawn, ChildProcess } from 'child_process';
import * as path from 'path';
interface MCPServerConfig {
name: string;
command: string;
args?: string[];
env?: Record<string, string>;
}
interface MCPConnection {
client: Client;
transport: StdioClientTransport;
process: ChildProcess;
tools: Map<string, any>;
}
export class MCPClientManager {
private connections: Map<string, MCPConnection> = new Map();
private configs: Map<string, MCPServerConfig> = new Map();
constructor() {
this.initializeConfigs();
}
private initializeConfigs() {
const serverDir = path.join(__dirname, 'servers');
this.configs.set('arxiv', {
name: 'arxiv',
command: 'npx',
args: ['ts-node', path.join(serverDir, 'arxiv-server.ts')],
});
this.configs.set('semantic-scholar', {
name: 'semantic-scholar',
command: 'npx',
args: ['ts-node', path.join(serverDir, 'semantic-scholar-server.ts')],
env: {
SEMANTIC_SCHOLAR_API_KEY: process.env.SEMANTIC_SCHOLAR_API_KEY || '',
},
});
this.configs.set('pdf', {
name: 'pdf',
command: 'npx',
args: ['ts-node', path.join(serverDir, 'pdf-server.ts')],
});
this.configs.set('web-search', {
name: 'web-search',
command: 'npx',
args: ['ts-node', path.join(serverDir, 'web-search-server.ts')],
env: {
TAVILY_API_KEY: process.env.TAVILY_API_KEY || '',
},
});
this.configs.set('vector-store', {
name: 'vector-store',
command: 'npx',
args: ['ts-node', path.join(serverDir, 'vector-store-server.ts')],
});
}
async connect(serverName: string): Promise<void> {
if (this.connections.has(serverName)) {
return;
}
const config = this.configs.get(serverName);
if (!config) {
throw new Error(`Unknown MCP server: ${serverName}`);
}
const serverProcess = spawn(config.command, config.args || [], {
stdio: ['pipe', 'pipe', 'pipe'],
env: { ...process.env, ...config.env },
});
const transport = new StdioClientTransport({
reader: serverProcess.stdout!,
writer: serverProcess.stdin!,
});
const client = new Client(
{
name: 'research-assistant-client',
version: '1.0.0',
},
{
capabilities: {},
}
);
await client.connect(transport);
const toolsResponse = await client.listTools();
const tools = new Map<string, any>();
for (const tool of toolsResponse.tools) {
tools.set(tool.name, tool);
}
this.connections.set(serverName, {
client,
transport,
process: serverProcess,
tools,
});
console.log(`Connected to MCP server: ${serverName} (${tools.size} tools)`);
}
async connectAll(): Promise<void> {
const connectPromises = Array.from(this.configs.keys()).map(name =>
this.connect(name).catch(err => {
console.error(`Failed to connect to ${name}:`, err.message);
})
);
await Promise.all(connectPromises);
}
async disconnect(serverName: string): Promise<void> {
const connection = this.connections.get(serverName);
if (!connection) {
return;
}
await connection.client.close();
connection.process.kill();
this.connections.delete(serverName);
}
async disconnectAll(): Promise<void> {
const disconnectPromises = Array.from(this.connections.keys()).map(name =>
this.disconnect(name)
);
await Promise.all(disconnectPromises);
}
async callTool(toolName: string, args: Record<string, any>): Promise<any> {
for (const [serverName, connection] of this.connections) {
if (connection.tools.has(toolName)) {
const result = await connection.client.callTool({
name: toolName,
arguments: args,
});
return result;
}
}
throw new Error(`Tool not found: ${toolName}`);
}
getAllTools(): Tool[] {
const langchainTools: Tool[] = [];
for (const [serverName, connection] of this.connections) {
for (const [toolName, toolDef] of connection.tools) {
const tool = this.createLangChainTool(toolName, toolDef, connection.client);
langchainTools.push(tool);
}
}
return langchainTools;
}
getToolsByServer(serverName: string): Tool[] {
const connection = this.connections.get(serverName);
if (!connection) {
return [];
}
const langchainTools: Tool[] = [];
for (const [toolName, toolDef] of connection.tools) {
const tool = this.createLangChainTool(toolName, toolDef, connection.client);
langchainTools.push(tool);
}
return langchainTools;
}
private createLangChainTool(
toolName: string,
toolDef: any,
client: Client
): Tool {
return {
name: toolName,
description: toolDef.description,
schema: toolDef.inputSchema,
invoke: async (input: Record<string, any>) => {
const result = await client.callTool({
name: toolName,
arguments: input,
});
if (result.content && Array.isArray(result.content)) {
const textContent = result.content.find((c: any) => c.type === 'text');
if (textContent) {
return textContent.text;
}
}
return JSON.stringify(result);
},
} as Tool;
}
listConnectedServers(): string[] {
return Array.from(this.connections.keys());
}
listAvailableTools(): Array<{ server: string; tool: string; description: string }> {
const toolList: Array<{ server: string; tool: string; description: string }> = [];
for (const [serverName, connection] of this.connections) {
for (const [toolName, toolDef] of connection.tools) {
toolList.push({
server: serverName,
tool: toolName,
description: toolDef.description,
});
}
}
return toolList;
}
}
export const mcpManager = new MCPClientManager();第三部分:上下文管理
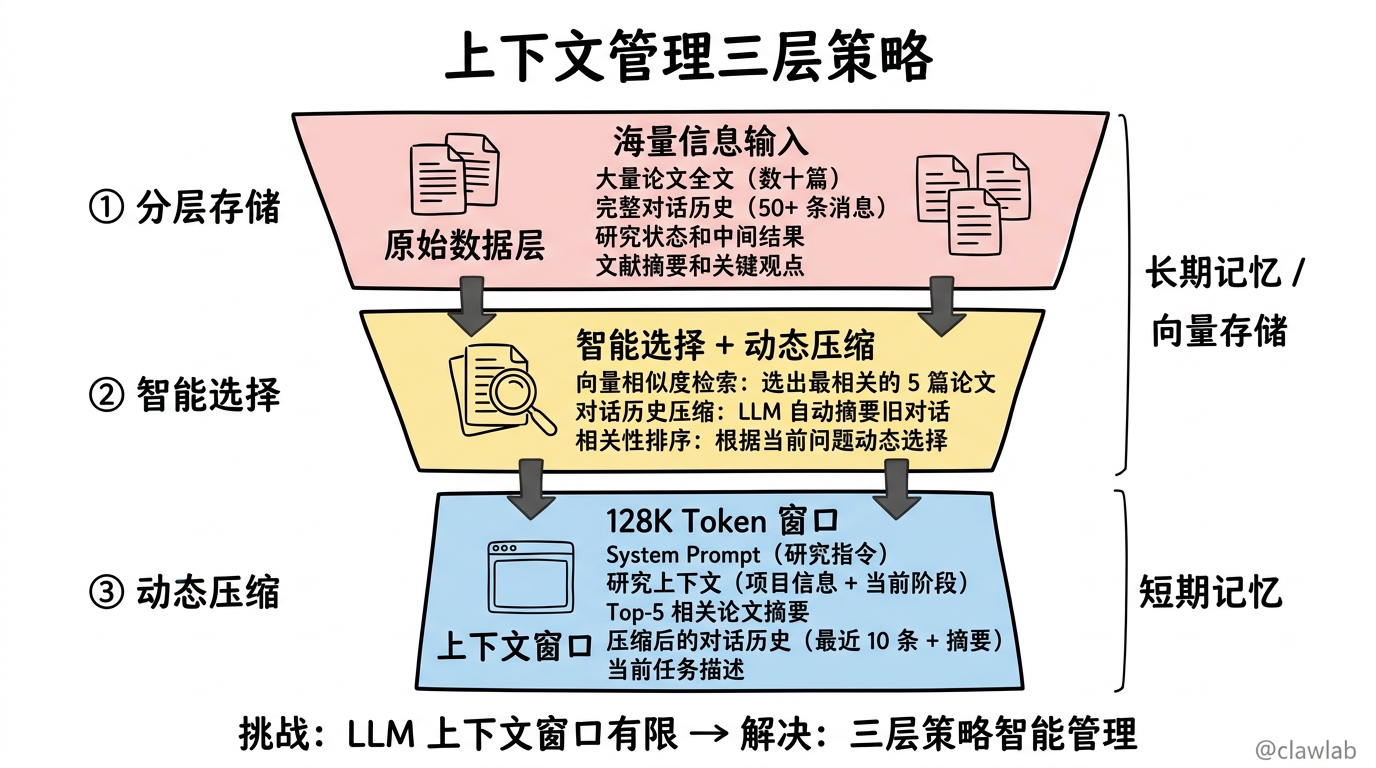
3.1 上下文管理的重要性
研究助手需要处理大量信息,包括:
- 用户的研究问题和要求
- 检索到的多篇论文
- 已提取的摘要和关键观点
- 生成中的报告草稿
- 对话历史
核心挑战:LLM 有上下文窗口限制,我们需要智能地管理这些信息。
┌─────────────────────────────────────────────────────────────┐
│ 上下文管理策略 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ 短期记忆 │ │ 长期记忆 │ │
│ │ (当前会话) │ │ (跨会话持久化) │ │
│ ├─────────────────┤ ├─────────────────┤ │
│ │ • 当前问题 │ │ • 已处理论文 │ │
│ │ • 最近对话 │ │ • 提取的摘要 │ │
│ │ • 工作状态 │ │ • 知识图谱 │ │
│ │ • 临时结果 │ │ • 用户偏好 │ │
│ └─────────────────┘ └─────────────────┘ │
│ │ │ │
│ └────────┬───────────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 上下文窗口 │ │
│ │ (Token 限制) │ │
│ └─────────────────┘ │
│ │ │
│ ┌────────┼────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 压缩 │ │ 选择 │ │ 摘要 │ │
│ │ 历史 │ │ 相关 │ │ 长文档 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
3.2 上下文管理器实现
typescript
// src/context/context-manager.ts
import { ChatOpenAI } from '@langchain/openai';
import { HumanMessage, AIMessage, SystemMessage, BaseMessage } from '@langchain/core/messages';
import { ChromaClient, Collection } from 'chromadb';
import { OpenAIEmbeddings } from '@langchain/openai';
import { PrismaClient } from '@prisma/client';
interface Paper {
id: number;
title: string;
abstract: string;
summary?: string;
keyPoints?: string[];
}
interface ContextWindow {
systemPrompt: string;
researchContext: string;
relevantPapers: Paper[];
conversationHistory: BaseMessage[];
currentTask: string;
tokenCount: number;
}
interface ResearchState {
projectId: number;
topic: string;
keywords: string[];
processedPapers: number[];
currentPhase: 'search' | 'analyze' | 'compare' | 'write';
findings: string[];
reportDraft: string;
}
export class ContextManager {
private llm: ChatOpenAI;
private embeddings: OpenAIEmbeddings;
private chromaClient: ChromaClient;
private prisma: PrismaClient;
private collection: Collection | null = null;
private maxTokens: number = 128000;
private reservedTokens: number = 4000;
private maxHistoryMessages: number = 20;
private researchState: Map<number, ResearchState> = new Map();
private conversationCache: Map<number, BaseMessage[]> = new Map();
constructor() {
this.llm = new ChatOpenAI({
modelName: 'gpt-4o-mini',
temperature: 0,
});
this.embeddings = new OpenAIEmbeddings();
this.chromaClient = new ChromaClient();
this.prisma = new PrismaClient();
}
async initialize(): Promise<void> {
this.collection = await this.chromaClient.getOrCreateCollection({
name: 'research_papers',
metadata: { description: 'Research paper embeddings' },
});
}
async buildContext(
projectId: number,
currentQuery: string,
sessionId: number
): Promise<ContextWindow> {
const project = await this.prisma.researchProject.findUnique({
where: { id: projectId },
include: {
papers: {
include: { paper: true },
orderBy: { relevance: 'desc' },
},
},
});
if (!project) {
throw new Error(`Project not found: ${projectId}`);
}
const relevantPapers = await this.selectRelevantPapers(
currentQuery,
project.papers.map(p => p.paper),
5
);
const conversationHistory = await this.getCompressedHistory(sessionId);
const researchState = this.researchState.get(projectId);
const researchContext = this.buildResearchContext(project, researchState);
const systemPrompt = this.buildSystemPrompt(project.topic);
const currentTask = this.inferCurrentTask(currentQuery, researchState);
const tokenCount = await this.estimateTokenCount({
systemPrompt,
researchContext,
relevantPapers,
conversationHistory,
currentTask,
});
if (tokenCount > this.maxTokens - this.reservedTokens) {
return await this.compressContext({
systemPrompt,
researchContext,
relevantPapers,
conversationHistory,
currentTask,
tokenCount,
});
}
return {
systemPrompt,
researchContext,
relevantPapers,
conversationHistory,
currentTask,
tokenCount,
};
}
private async selectRelevantPapers(
query: string,
papers: Paper[],
limit: number
): Promise<Paper[]> {
if (!this.collection || papers.length === 0) {
return papers.slice(0, limit);
}
const queryEmbedding = await this.embeddings.embedQuery(query);
const results = await this.collection.query({
queryEmbeddings: [queryEmbedding],
nResults: limit,
where: {
paperId: { $in: papers.map(p => p.id.toString()) },
},
});
if (!results.ids[0] || results.ids[0].length === 0) {
return papers.slice(0, limit);
}
const paperMap = new Map(papers.map(p => [p.id.toString(), p]));
const relevantPapers: Paper[] = [];
for (const id of results.ids[0]) {
const paper = paperMap.get(id);
if (paper) {
relevantPapers.push(paper);
}
}
return relevantPapers;
}
private async getCompressedHistory(sessionId: number): Promise<BaseMessage[]> {
const cached = this.conversationCache.get(sessionId);
if (cached) {
return cached.slice(-this.maxHistoryMessages);
}
const messages = await this.prisma.message.findMany({
where: { sessionId },
orderBy: { createdAt: 'desc' },
take: 50,
});
const history: BaseMessage[] = messages.reverse().map(msg => {
if (msg.role === 'user') {
return new HumanMessage(msg.content);
} else if (msg.role === 'assistant') {
return new AIMessage(msg.content);
} else {
return new SystemMessage(msg.content);
}
});
if (history.length > this.maxHistoryMessages) {
const compressedHistory = await this.compressConversationHistory(history);
this.conversationCache.set(sessionId, compressedHistory);
return compressedHistory;
}
this.conversationCache.set(sessionId, history);
return history;
}
private async compressConversationHistory(
history: BaseMessage[]
): Promise<BaseMessage[]> {
const oldMessages = history.slice(0, -10);
const recentMessages = history.slice(-10);
if (oldMessages.length === 0) {
return recentMessages;
}
const historyText = oldMessages
.map(m => `${m._getType()}: ${m.content}`)
.join('\n');
const summaryResponse = await this.llm.invoke([
new SystemMessage('Summarize the following conversation history concisely, preserving key information and context:'),
new HumanMessage(historyText),
]);
const summaryMessage = new SystemMessage(
`[Previous conversation summary]: ${summaryResponse.content}`
);
return [summaryMessage, ...recentMessages];
}
private buildResearchContext(
project: any,
state?: ResearchState
): string {
let context = `研究项目: ${project.title}\n`;
context += `研究主题: ${project.topic}\n`;
const keywords = JSON.parse(project.keywords || '[]');
context += `关键词: ${keywords.join(', ')}\n`;
if (state) {
context += `\n当前阶段: ${this.getPhaseDescription(state.currentPhase)}\n`;
context += `已处理论文数: ${state.processedPapers.length}\n`;
if (state.findings.length > 0) {
context += `\n主要发现:\n`;
state.findings.slice(-5).forEach((finding, i) => {
context += `${i + 1}. ${finding}\n`;
});
}
if (state.reportDraft) {
context += `\n报告进度: 已完成草稿\n`;
}
}
return context;
}
private getPhaseDescription(phase: string): string {
const descriptions: Record<string, string> = {
search: '文献检索阶段 - 正在搜索和收集相关文献',
analyze: '分析阶段 - 正在分析和提取论文关键信息',
compare: '对比阶段 - 正在比较不同论文的观点',
write: '撰写阶段 - 正在生成研究报告',
};
return descriptions[phase] || '未知阶段';
}
private buildSystemPrompt(topic: string): string {
return `你是一个专业的 AI 研究助手,正在帮助用户研究「${topic}」这个主题。
你的职责包括:
1. 搜索和分析学术文献
2. 提取关键信息和观点
3. 比较不同来源的异同
4. 撰写结构化的研究报告
在回答时,请:
- 引用具体的论文和来源
- 提供客观、准确的信息
- 指出不同观点之间的关系
- 如果信息不足,主动建议补充搜索`;
}
private inferCurrentTask(query: string, state?: ResearchState): string {
const searchKeywords = ['搜索', '查找', '检索', 'search', 'find'];
const analyzeKeywords = ['分析', '解读', '理解', 'analyze', 'explain'];
const compareKeywords = ['比较', '对比', '异同', 'compare', 'difference'];
const writeKeywords = ['报告', '总结', '撰写', 'report', 'summarize', 'write'];
const queryLower = query.toLowerCase();
if (searchKeywords.some(k => queryLower.includes(k))) {
return 'search';
}
if (analyzeKeywords.some(k => queryLower.includes(k))) {
return 'analyze';
}
if (compareKeywords.some(k => queryLower.includes(k))) {
return 'compare';
}
if (writeKeywords.some(k => queryLower.includes(k))) {
return 'write';
}
return state?.currentPhase || 'search';
}
private async estimateTokenCount(context: Partial<ContextWindow>): Promise<number> {
const text = [
context.systemPrompt || '',
context.researchContext || '',
context.currentTask || '',
...(context.relevantPapers || []).map(p => `${p.title}\n${p.abstract}\n${p.summary || ''}`),
...(context.conversationHistory || []).map(m => m.content as string),
].join('\n');
return Math.ceil(text.length / 4);
}
private async compressContext(context: ContextWindow): Promise<ContextWindow> {
let compressed = { ...context };
while (compressed.tokenCount > this.maxTokens - this.reservedTokens) {
if (compressed.relevantPapers.length > 2) {
compressed.relevantPapers = compressed.relevantPapers.slice(0, -1);
} else if (compressed.conversationHistory.length > 5) {
compressed.conversationHistory = await this.compressConversationHistory(
compressed.conversationHistory
);
} else {
compressed.relevantPapers = compressed.relevantPapers.map(p => ({
...p,
abstract: p.abstract.slice(0, 500) + '...',
}));
}
compressed.tokenCount = await this.estimateTokenCount(compressed);
}
return compressed;
}
updateResearchState(projectId: number, updates: Partial<ResearchState>): void {
const current = this.researchState.get(projectId) || {
projectId,
topic: '',
keywords: [],
processedPapers: [],
currentPhase: 'search' as const,
findings: [],
reportDraft: '',
};
this.researchState.set(projectId, { ...current, ...updates });
}
addFinding(projectId: number, finding: string): void {
const state = this.researchState.get(projectId);
if (state) {
state.findings.push(finding);
if (state.findings.length > 20) {
state.findings = state.findings.slice(-20);
}
}
}
addProcessedPaper(projectId: number, paperId: number): void {
const state = this.researchState.get(projectId);
if (state && !state.processedPapers.includes(paperId)) {
state.processedPapers.push(paperId);
}
}
clearCache(sessionId?: number): void {
if (sessionId) {
this.conversationCache.delete(sessionId);
} else {
this.conversationCache.clear();
}
}
}
export const contextManager = new ContextManager();3.3 长文档处理
typescript
// src/context/document-processor.ts
import { ChatOpenAI } from '@langchain/openai';
import { HumanMessage, SystemMessage } from '@langchain/core/messages';
import { Document } from '@langchain/core/documents';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
interface ProcessedDocument {
title: string;
summary: string;
keyPoints: string[];
methodology: string;
conclusions: string;
chunks: DocumentChunk[];
}
interface DocumentChunk {
content: string;
index: number;
metadata: {
section?: string;
pageNumber?: number;
};
}
interface SectionSummary {
section: string;
summary: string;
keyPoints: string[];
}
export class DocumentProcessor {
private llm: ChatOpenAI;
private splitter: RecursiveCharacterTextSplitter;
constructor() {
this.llm = new ChatOpenAI({
modelName: 'gpt-4o-mini',
temperature: 0,
});
this.splitter = new RecursiveCharacterTextSplitter({
chunkSize: 2000,
chunkOverlap: 200,
separators: ['\n\n', '\n', '. ', ' ', ''],
});
}
async processDocument(
content: string,
title: string,
extractSections: boolean = true
): Promise<ProcessedDocument> {
const chunks = await this.splitDocument(content);
let sectionSummaries: SectionSummary[] = [];
if (extractSections) {
sectionSummaries = await this.extractAndSummarizeSections(content);
}
const summary = await this.generateOverallSummary(
title,
content.slice(0, 10000),
sectionSummaries
);
const keyPoints = await this.extractKeyPoints(content.slice(0, 15000));
const methodology = await this.extractMethodology(content);
const conclusions = await this.extractConclusions(content);
return {
title,
summary,
keyPoints,
methodology,
conclusions,
chunks,
};
}
private async splitDocument(content: string): Promise<DocumentChunk[]> {
const docs = await this.splitter.createDocuments([content]);
return docs.map((doc, index) => ({
content: doc.pageContent,
index,
metadata: doc.metadata,
}));
}
private async extractAndSummarizeSections(
content: string
): Promise<SectionSummary[]> {
const sectionPatterns: Record<string, RegExp> = {
abstract: /(?:^|\n)(abstract|摘要)[:\s]*\n?([\s\S]*?)(?=\n(?:1\.|introduction|引言|keywords|关键词)|\n\n\n)/i,
introduction: /(?:^|\n)((?:1\.?\s*)?introduction|引言)[:\s]*\n?([\s\S]*?)(?=\n(?:2\.|related|background|方法|method)|\n\n\n)/i,
methods: /(?:^|\n)((?:\d\.?\s*)?method(?:ology|s)?|方法)[:\s]*\n?([\s\S]*?)(?=\n(?:\d\.|experiment|result|实验|结果)|\n\n\n)/i,
results: /(?:^|\n)((?:\d\.?\s*)?results?|结果)[:\s]*\n?([\s\S]*?)(?=\n(?:\d\.|discussion|conclusion|讨论|结论)|\n\n\n)/i,
conclusion: /(?:^|\n)((?:\d\.?\s*)?conclusions?|结论)[:\s]*\n?([\s\S]*?)(?=\n(?:reference|acknowledge|参考|致谢)|\n\n\n|$)/i,
};
const summaries: SectionSummary[] = [];
for (const [section, pattern] of Object.entries(sectionPatterns)) {
const match = content.match(pattern);
if (match && match[2]) {
const sectionContent = match[2].trim().slice(0, 5000);
if (sectionContent.length > 100) {
const summary = await this.summarizeSection(section, sectionContent);
summaries.push(summary);
}
}
}
return summaries;
}
private async summarizeSection(
section: string,
content: string
): Promise<SectionSummary> {
const response = await this.llm.invoke([
new SystemMessage(`你是一个学术论文分析助手。请分析以下论文的「${section}」部分,提供:
1. 简洁摘要(2-3句话)
2. 关键要点(3-5个)
以 JSON 格式输出:{"summary": "...", "keyPoints": ["...", "..."]}`),
new HumanMessage(content),
]);
try {
const result = JSON.parse(response.content as string);
return {
section,
summary: result.summary,
keyPoints: result.keyPoints,
};
} catch {
return {
section,
summary: content.slice(0, 200) + '...',
keyPoints: [],
};
}
}
private async generateOverallSummary(
title: string,
content: string,
sectionSummaries: SectionSummary[]
): Promise<string> {
const sectionsContext = sectionSummaries
.map(s => `${s.section}: ${s.summary}`)
.join('\n');
const response = await this.llm.invoke([
new SystemMessage(`你是一个学术论文分析助手。根据论文内容和各部分摘要,生成一个全面的论文摘要(200-300字)。
论文标题: ${title}
各部分摘要:
${sectionsContext}`),
new HumanMessage(`请根据以上信息和以下论文内容生成摘要:\n\n${content.slice(0, 5000)}`),
]);
return response.content as string;
}
private async extractKeyPoints(content: string): Promise<string[]> {
const response = await this.llm.invoke([
new SystemMessage(`从以下学术论文中提取 5-8 个关键要点。每个要点应该简洁明了,包含具体信息。
以 JSON 数组格式输出:["要点1", "要点2", ...]`),
new HumanMessage(content),
]);
try {
return JSON.parse(response.content as string);
} catch {
return [];
}
}
private async extractMethodology(content: string): Promise<string> {
const methodPattern = /(?:method(?:ology|s)?|approach|技术方法|研究方法)[:\s]*\n?([\s\S]{500,3000})/i;
const match = content.match(methodPattern);
if (!match) {
return '';
}
const response = await this.llm.invoke([
new SystemMessage('请简洁描述这篇论文使用的研究方法或技术路线(100-200字):'),
new HumanMessage(match[1]),
]);
return response.content as string;
}
private async extractConclusions(content: string): Promise<string> {
const conclusionPattern = /(?:conclusion|结论)[:\s]*\n?([\s\S]{200,2000})/i;
const match = content.match(conclusionPattern);
if (!match) {
const lastPart = content.slice(-3000);
const response = await this.llm.invoke([
new SystemMessage('请从以下文本中提取论文的主要结论(100-150字):'),
new HumanMessage(lastPart),
]);
return response.content as string;
}
const response = await this.llm.invoke([
new SystemMessage('请简洁总结这篇论文的主要结论(100-150字):'),
new HumanMessage(match[1]),
]);
return response.content as string;
}
async processMultipleDocuments(
documents: Array<{ content: string; title: string }>
): Promise<ProcessedDocument[]> {
const results: ProcessedDocument[] = [];
for (const doc of documents) {
try {
const processed = await this.processDocument(doc.content, doc.title);
results.push(processed);
} catch (error) {
console.error(`Error processing document ${doc.title}:`, error);
}
}
return results;
}
async createHierarchicalSummary(
documents: ProcessedDocument[]
): Promise<string> {
const docSummaries = documents
.map((d, i) => `[${i + 1}] ${d.title}\n${d.summary}`)
.join('\n\n');
const response = await this.llm.invoke([
new SystemMessage(`你是一个研究综述助手。根据以下多篇论文的摘要,生成一个综合性的研究领域概述:
要求:
1. 识别主要研究方向和趋势
2. 指出论文之间的关联
3. 总结该领域的主要进展
4. 指出尚待解决的问题`),
new HumanMessage(docSummaries),
]);
return response.content as string;
}
}
export const documentProcessor = new DocumentProcessor();第四部分:Agent 实现
4.1 研究规划器(主 Agent)
typescript
// src/agents/research-planner.ts
import { ChatOpenAI } from '@langchain/openai';
import { HumanMessage, SystemMessage, AIMessage } from '@langchain/core/messages';
import { z } from 'zod';
const ResearchPlanSchema = z.object({
understanding: z.string().describe('对研究问题的理解'),
searchStrategy: z.object({
primaryKeywords: z.array(z.string()).describe('主要搜索关键词'),
alternativeKeywords: z.array(z.string()).describe('备选/相关关键词'),
targetSources: z.array(z.enum(['arxiv', 'semantic_scholar', 'web', 'local'])).describe('目标搜索源'),
timeRange: z.object({
from: z.number().optional(),
to: z.number().optional(),
}).describe('时间范围筛选'),
expectedPapers: z.number().describe('预期需要的论文数量'),
}),
analysisApproach: z.object({
focusAreas: z.array(z.string()).describe('重点分析领域'),
comparisonDimensions: z.array(z.string()).describe('对比分析维度'),
expectedFindings: z.array(z.string()).describe('预期发现的内容类型'),
}),
outputFormat: z.object({
reportStructure: z.array(z.string()).describe('报告结构大纲'),
includeSections: z.array(z.string()).describe('需要包含的章节'),
}),
estimatedSteps: z.number().describe('预计步骤数'),
});
type ResearchPlan = z.infer<typeof ResearchPlanSchema>;
const GapAnalysisSchema = z.object({
hasGaps: z.boolean().describe('是否存在信息缺口'),
gaps: z.array(z.object({
description: z.string().describe('缺口描述'),
suggestedAction: z.string().describe('建议的补充行动'),
priority: z.enum(['high', 'medium', 'low']).describe('优先级'),
})),
completeness: z.number().min(0).max(100).describe('当前研究完成度百分比'),
recommendation: z.enum(['continue_search', 'proceed_analysis', 'generate_report']).describe('建议的下一步'),
});
type GapAnalysis = z.infer<typeof GapAnalysisSchema>;
export class ResearchPlanner {
private llm: ChatOpenAI;
private plannerLLM: ChatOpenAI;
constructor() {
this.llm = new ChatOpenAI({
modelName: 'gpt-4o',
temperature: 0.3,
});
this.plannerLLM = this.llm.withStructuredOutput(ResearchPlanSchema);
}
async createResearchPlan(
topic: string,
requirements?: string,
constraints?: {
maxPapers?: number;
timeRange?: { from?: number; to?: number };
focusAreas?: string[];
}
): Promise<ResearchPlan> {
const systemPrompt = `你是一个专业的研究规划助手。根据用户的研究主题和需求,制定详细的研究计划。
考虑因素:
1. 研究主题的范围和深度
2. 可用的文献来源
3. 时间和资源限制
4. 输出格式要求
请制定一个全面、可执行的研究计划。`;
const userPrompt = `研究主题:${topic}
${requirements ? `具体要求:${requirements}` : ''}
${constraints ? `限制条件:
- 最大论文数:${constraints.maxPapers || '不限'}
- 时间范围:${constraints.timeRange ? `${constraints.timeRange.from || '不限'} - ${constraints.timeRange.to || '至今'}` : '不限'}
- 重点领域:${constraints.focusAreas?.join(', ') || '不限'}` : ''}
请制定研究计划。`;
const plan = await this.plannerLLM.invoke([
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
]);
return plan;
}
async analyzeInformationGaps(
originalPlan: ResearchPlan,
collectedPapers: Array<{
title: string;
abstract: string;
summary?: string;
}>,
extractedFindings: string[]
): Promise<GapAnalysis> {
const gapAnalyzerLLM = this.llm.withStructuredOutput(GapAnalysisSchema);
const papersContext = collectedPapers
.map((p, i) => `[${i + 1}] ${p.title}\n${p.summary || p.abstract.slice(0, 300)}`)
.join('\n\n');
const findingsContext = extractedFindings.join('\n- ');
const systemPrompt = `你是一个研究质量评估助手。分析当前收集的信息是否足够完成研究目标。
评估维度:
1. 覆盖度:是否覆盖了计划中的所有重点领域
2. 深度:每个领域的信息是否足够深入
3. 多样性:是否包含不同的观点和方法
4. 时效性:信息是否足够新
5. 可靠性:来源是否可靠`;
const userPrompt = `研究计划:
- 主题理解:${originalPlan.understanding}
- 重点领域:${originalPlan.analysisApproach.focusAreas.join(', ')}
- 对比维度:${originalPlan.analysisApproach.comparisonDimensions.join(', ')}
- 预期发现:${originalPlan.analysisApproach.expectedFindings.join(', ')}
已收集论文(${collectedPapers.length}篇):
${papersContext}
已提取发现:
- ${findingsContext}
请评估信息完整性并识别缺口。`;
const analysis = await gapAnalyzerLLM.invoke([
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
]);
return analysis;
}
async generateSupplementarySearches(
gaps: GapAnalysis['gaps'],
previousSearches: string[]
): Promise<Array<{
query: string;
source: string;
rationale: string;
}>> {
const SearchSuggestionsSchema = z.object({
searches: z.array(z.object({
query: z.string(),
source: z.enum(['arxiv', 'semantic_scholar', 'web']),
rationale: z.string(),
})),
});
const suggesterLLM = this.llm.withStructuredOutput(SearchSuggestionsSchema);
const gapsDescription = gaps
.map(g => `- ${g.description} (${g.priority}): ${g.suggestedAction}`)
.join('\n');
const response = await suggesterLLM.invoke([
new SystemMessage(`你是一个搜索策略优化助手。根据识别的信息缺口,生成补充搜索建议。
之前的搜索:
${previousSearches.join(', ')}
要求:
1. 避免重复之前的搜索
2. 针对性填补信息缺口
3. 考虑不同搜索源的特点`),
new HumanMessage(`需要填补的信息缺口:\n${gapsDescription}`),
]);
return response.searches;
}
async decideNextStep(
currentState: {
phase: string;
papersCollected: number;
findingsExtracted: number;
gapAnalysis?: GapAnalysis;
}
): Promise<{
action: 'search' | 'analyze' | 'compare' | 'write' | 'complete';
reason: string;
details: Record<string, any>;
}> {
const DecisionSchema = z.object({
action: z.enum(['search', 'analyze', 'compare', 'write', 'complete']),
reason: z.string(),
details: z.record(z.any()),
});
const deciderLLM = this.llm.withStructuredOutput(DecisionSchema);
const response = await deciderLLM.invoke([
new SystemMessage(`你是一个研究流程控制助手。根据当前研究状态,决定下一步行动。
可选行动:
- search: 需要继续搜索更多文献
- analyze: 需要分析已收集的文献
- compare: 需要进行观点对比
- write: 可以开始撰写报告
- complete: 研究已完成`),
new HumanMessage(`当前状态:
- 阶段:${currentState.phase}
- 已收集论文:${currentState.papersCollected}篇
- 已提取发现:${currentState.findingsExtracted}条
- 完成度:${currentState.gapAnalysis?.completeness || 0}%
- 建议:${currentState.gapAnalysis?.recommendation || '未评估'}
请决定下一步行动。`),
]);
return response;
}
}
export const researchPlanner = new ResearchPlanner();4.2 文献检索 Agent
typescript
// src/agents/search-agent.ts
import { ChatOpenAI } from '@langchain/openai';
import { createReactAgent } from '@langchain/langgraph/prebuilt';
import { HumanMessage, SystemMessage } from '@langchain/core/messages';
import { tool } from '@langchain/core/tools';
import { z } from 'zod';
import { mcpManager } from '../mcp/client-manager';
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
interface SearchResult {
source: string;
papers: Array<{
id: string;
title: string;
authors: string[];
abstract: string;
url: string;
publishedAt?: string;
citations?: number;
}>;
totalResults: number;
}
const searchArxivTool = tool(
async ({ query, maxResults, sortBy }) => {
const result = await mcpManager.callTool('arxiv_search', {
query,
maxResults: maxResults || 10,
sortBy: sortBy || 'relevance',
});
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'search_arxiv',
description: 'Search for papers on arXiv',
schema: z.object({
query: z.string().describe('Search query'),
maxResults: z.number().optional().describe('Maximum results (default: 10)'),
sortBy: z.enum(['relevance', 'lastUpdatedDate', 'submittedDate']).optional(),
}),
}
);
const searchSemanticScholarTool = tool(
async ({ query, limit, yearMin, yearMax }) => {
const result = await mcpManager.callTool('semantic_scholar_search', {
query,
limit: limit || 10,
yearMin,
yearMax,
});
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'search_semantic_scholar',
description: 'Search for papers in Semantic Scholar',
schema: z.object({
query: z.string().describe('Search query'),
limit: z.number().optional().describe('Maximum results'),
yearMin: z.number().optional().describe('Minimum publication year'),
yearMax: z.number().optional().describe('Maximum publication year'),
}),
}
);
const getCitationsTool = tool(
async ({ paperId, limit }) => {
const result = await mcpManager.callTool('semantic_scholar_citations', {
paperId,
limit: limit || 10,
});
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'get_citations',
description: 'Get papers that cite a specific paper',
schema: z.object({
paperId: z.string().describe('Semantic Scholar paper ID'),
limit: z.number().optional().describe('Maximum citations to return'),
}),
}
);
const getReferencesTool = tool(
async ({ paperId, limit }) => {
const result = await mcpManager.callTool('semantic_scholar_references', {
paperId,
limit: limit || 10,
});
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'get_references',
description: 'Get papers referenced by a specific paper',
schema: z.object({
paperId: z.string().describe('Semantic Scholar paper ID'),
limit: z.number().optional().describe('Maximum references to return'),
}),
}
);
const savePaperTool = tool(
async ({ title, authors, abstract, source, sourceUrl, sourceId, doi, publishedAt, venue, citations, userId, projectId }) => {
const paper = await prisma.paper.upsert({
where: {
source_sourceId: {
source,
sourceId,
},
},
update: {
title,
authors: JSON.stringify(authors),
abstract,
sourceUrl,
doi,
publishedAt: publishedAt ? new Date(publishedAt) : null,
venue,
citations: citations || 0,
},
create: {
userId,
title,
authors: JSON.stringify(authors),
abstract,
source,
sourceUrl,
sourceId,
doi,
publishedAt: publishedAt ? new Date(publishedAt) : null,
venue,
citations: citations || 0,
},
});
if (projectId) {
await prisma.projectPaper.upsert({
where: {
projectId_paperId: {
projectId,
paperId: paper.id,
},
},
update: {},
create: {
projectId,
paperId: paper.id,
},
});
}
return JSON.stringify({ success: true, paperId: paper.id });
},
{
name: 'save_paper',
description: 'Save a paper to the database',
schema: z.object({
title: z.string(),
authors: z.array(z.string()),
abstract: z.string(),
source: z.string(),
sourceUrl: z.string().optional(),
sourceId: z.string(),
doi: z.string().optional(),
publishedAt: z.string().optional(),
venue: z.string().optional(),
citations: z.number().optional(),
userId: z.number(),
projectId: z.number().optional(),
}),
}
);
export function createSearchAgent() {
const llm = new ChatOpenAI({
modelName: 'gpt-4o',
temperature: 0,
});
const tools = [
searchArxivTool,
searchSemanticScholarTool,
getCitationsTool,
getReferencesTool,
savePaperTool,
];
const systemPrompt = `你是一个专业的文献检索助手,负责帮助研究人员查找相关学术论文。
你可以使用以下工具:
1. search_arxiv - 在 arXiv 上搜索论文
2. search_semantic_scholar - 在 Semantic Scholar 上搜索论文
3. get_citations - 获取引用某篇论文的后续研究
4. get_references - 获取某篇论文引用的参考文献
5. save_paper - 将找到的论文保存到数据库
搜索策略:
1. 根据研究主题生成多个搜索关键词
2. 在不同数据源进行搜索以获得更全面的结果
3. 使用引用追踪找到相关的重要论文
4. 过滤和排序结果,优先选择高质量论文
质量判断标准:
- 引用数(越高越好)
- 发表时间(优先最新研究)
- 发表期刊/会议(知名度)
- 作者影响力
- 与研究主题的相关度`;
return createReactAgent({
llm,
tools,
messageModifier: new SystemMessage(systemPrompt),
});
}
export class SearchAgent {
private agent: ReturnType<typeof createSearchAgent>;
constructor() {
this.agent = createSearchAgent();
}
async search(
query: string,
options: {
userId: number;
projectId?: number;
maxPapers?: number;
yearRange?: { from?: number; to?: number };
sources?: string[];
}
): Promise<SearchResult[]> {
const prompt = `请搜索关于「${query}」的学术论文。
要求:
- 最多找 ${options.maxPapers || 10} 篇相关论文
${options.yearRange ? `- 时间范围:${options.yearRange.from || '不限'} - ${options.yearRange.to || '至今'}` : ''}
${options.sources ? `- 搜索源:${options.sources.join(', ')}` : '- 在所有可用数据源搜索'}
找到论文后,请将相关论文保存到数据库(userId: ${options.userId}${options.projectId ? `, projectId: ${options.projectId}` : ''})。`;
const result = await this.agent.invoke({
messages: [new HumanMessage(prompt)],
});
const lastMessage = result.messages[result.messages.length - 1];
return this.parseSearchResults(lastMessage.content as string);
}
async exploreCitations(
paperId: string,
direction: 'citations' | 'references' | 'both'
): Promise<any[]> {
let prompt = '';
if (direction === 'citations') {
prompt = `请获取论文 ${paperId} 的引用列表(被哪些论文引用了)。`;
} else if (direction === 'references') {
prompt = `请获取论文 ${paperId} 的参考文献列表。`;
} else {
prompt = `请获取论文 ${paperId} 的引用和参考文献列表。`;
}
const result = await this.agent.invoke({
messages: [new HumanMessage(prompt)],
});
return result.messages;
}
private parseSearchResults(content: string): SearchResult[] {
return [];
}
}
export const searchAgent = new SearchAgent();4.3 摘要提取 Agent
typescript
// src/agents/summary-agent.ts
import { ChatOpenAI } from '@langchain/openai';
import { createReactAgent } from '@langchain/langgraph/prebuilt';
import { HumanMessage, SystemMessage } from '@langchain/core/messages';
import { tool } from '@langchain/core/tools';
import { z } from 'zod';
import { mcpManager } from '../mcp/client-manager';
import { documentProcessor } from '../context/document-processor';
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
const PaperAnalysisSchema = z.object({
title: z.string(),
summary: z.string().describe('论文核心内容摘要(200-300字)'),
keyPoints: z.array(z.string()).describe('关键要点(5-8个)'),
methodology: z.string().describe('研究方法概述'),
mainFindings: z.array(z.string()).describe('主要发现(3-5个)'),
limitations: z.array(z.string()).describe('研究局限性'),
futureWork: z.array(z.string()).describe('未来研究方向'),
relevance: z.object({
score: z.number().min(0).max(10),
reason: z.string(),
}).describe('与研究主题的相关性评估'),
});
type PaperAnalysis = z.infer<typeof PaperAnalysisSchema>;
const fetchPdfTool = tool(
async ({ arxivId }) => {
const result = await mcpManager.callTool('arxiv_download_pdf', { arxivId });
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'fetch_pdf',
description: 'Download PDF from arXiv',
schema: z.object({
arxivId: z.string().describe('arXiv paper ID'),
}),
}
);
const parsePdfTool = tool(
async ({ base64Content }) => {
const result = await mcpManager.callTool('pdf_parse_base64', { base64Content });
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'parse_pdf',
description: 'Parse PDF content and extract text',
schema: z.object({
base64Content: z.string().describe('Base64 encoded PDF content'),
}),
}
);
const extractSectionsTool = tool(
async ({ filePath }) => {
const result = await mcpManager.callTool('pdf_extract_sections', { filePath });
const content = result.content?.find((c: any) => c.type === 'text');
return content?.text || JSON.stringify(result);
},
{
name: 'extract_sections',
description: 'Extract academic paper sections',
schema: z.object({
filePath: z.string().describe('Path to PDF file'),
}),
}
);
const saveAnalysisTool = tool(
async ({ paperId, summary, keyPoints, methodology, conclusions }) => {
await prisma.paper.update({
where: { id: paperId },
data: {
isProcessed: true,
summary,
keyPoints: JSON.stringify(keyPoints),
methodology,
conclusions,
},
});
return JSON.stringify({ success: true });
},
{
name: 'save_analysis',
description: 'Save paper analysis to database',
schema: z.object({
paperId: z.number(),
summary: z.string(),
keyPoints: z.array(z.string()),
methodology: z.string(),
conclusions: z.string(),
}),
}
);
export function createSummaryAgent() {
const llm = new ChatOpenAI({
modelName: 'gpt-4o',
temperature: 0,
});
const tools = [
fetchPdfTool,
parsePdfTool,
extractSectionsTool,
saveAnalysisTool,
];
const systemPrompt = `你是一个专业的学术论文分析助手,负责阅读和理解论文内容,提取关键信息。
分析任务:
1. 理解论文的核心贡献
2. 识别研究方法和技术路线
3. 提取主要发现和结论
4. 评估论文的优缺点
5. 判断与研究主题的相关性
分析要求:
- 准确:忠实于原文内容
- 简洁:抓住核心,避免冗余
- 结构化:按照标准格式组织
- 客观:避免主观评价`;
return createReactAgent({
llm,
tools,
messageModifier: new SystemMessage(systemPrompt),
});
}
export class SummaryAgent {
private agent: ReturnType<typeof createSummaryAgent>;
private llm: ChatOpenAI;
constructor() {
this.agent = createSummaryAgent();
this.llm = new ChatOpenAI({
modelName: 'gpt-4o',
temperature: 0,
});
}
async analyzePaper(
paperId: number,
researchTopic: string
): Promise<PaperAnalysis> {
const paper = await prisma.paper.findUnique({
where: { id: paperId },
});
if (!paper) {
throw new Error(`Paper not found: ${paperId}`);
}
const analyzerLLM = this.llm.withStructuredOutput(PaperAnalysisSchema);
const prompt = `请分析以下学术论文,评估其与研究主题「${researchTopic}」的相关性。
论文标题:${paper.title}
作者:${paper.authors}
摘要:${paper.abstract}
${paper.content ? `\n全文内容:\n${paper.content.slice(0, 15000)}` : ''}`;
const analysis = await analyzerLLM.invoke([
new SystemMessage(`你是专业的学术论文分析助手。请按照指定格式分析论文。`),
new HumanMessage(prompt),
]);
await prisma.paper.update({
where: { id: paperId },
data: {
isProcessed: true,
summary: analysis.summary,
keyPoints: JSON.stringify(analysis.keyPoints),
methodology: analysis.methodology,
conclusions: analysis.mainFindings.join('\n'),
},
});
return analysis;
}
async analyzeMultiplePapers(
paperIds: number[],
researchTopic: string
): Promise<PaperAnalysis[]> {
const analyses: PaperAnalysis[] = [];
for (const paperId of paperIds) {
try {
const analysis = await this.analyzePaper(paperId, researchTopic);
analyses.push(analysis);
} catch (error) {
console.error(`Error analyzing paper ${paperId}:`, error);
}
}
return analyses;
}
async extractKeyInsights(
analyses: PaperAnalysis[],
focusAreas: string[]
): Promise<{
insights: Array<{
area: string;
findings: string[];
sources: string[];
}>;
consensus: string[];
controversies: string[];
}> {
const InsightsSchema = z.object({
insights: z.array(z.object({
area: z.string(),
findings: z.array(z.string()),
sources: z.array(z.string()),
})),
consensus: z.array(z.string()),
controversies: z.array(z.string()),
});
const insightsLLM = this.llm.withStructuredOutput(InsightsSchema);
const analysesContext = analyses
.map(a => `论文:${a.title}\n关键发现:${a.mainFindings.join('; ')}`)
.join('\n\n');
const response = await insightsLLM.invoke([
new SystemMessage(`你是研究综合分析助手。根据多篇论文的分析结果,提取综合洞察。
重点关注领域:${focusAreas.join(', ')}
任务:
1. 按领域整理发现
2. 识别学界共识
3. 发现争议观点`),
new HumanMessage(analysesContext),
]);
return response;
}
}
export const summaryAgent = new SummaryAgent();4.4 对比分析 Agent
typescript
// src/agents/comparison-agent.ts
import { ChatOpenAI } from '@langchain/openai';
import { HumanMessage, SystemMessage } from '@langchain/core/messages';
import { z } from 'zod';
interface PaperViewpoint {
paperId: number;
title: string;
viewpoints: Array<{
topic: string;
stance: string;
evidence: string;
}>;
}
const ComparisonResultSchema = z.object({
dimensions: z.array(z.object({
name: z.string().describe('对比维度'),
description: z.string().describe('维度说明'),
papers: z.array(z.object({
title: z.string(),
position: z.string().describe('该论文在此维度上的立场/观点'),
evidence: z.string().describe('支持证据'),
})),
consensus: z.string().optional().describe('共识点'),
divergence: z.string().optional().describe('分歧点'),
})),
overallSummary: z.string().describe('整体对比总结'),
strengthsWeaknesses: z.array(z.object({
paperTitle: z.string(),
strengths: z.array(z.string()),
weaknesses: z.array(z.string()),
})),
recommendations: z.array(z.string()).describe('基于对比的建议'),
});
type ComparisonResult = z.infer<typeof ComparisonResultSchema>;
const RelationshipSchema = z.object({
relationships: z.array(z.object({
paper1: z.string(),
paper2: z.string(),
type: z.enum(['supports', 'contradicts', 'extends', 'applies', 'unrelated']),
description: z.string(),
confidence: z.number().min(0).max(1),
})),
clusters: z.array(z.object({
theme: z.string(),
papers: z.array(z.string()),
summary: z.string(),
})),
evolutionPath: z.array(z.object({
stage: z.string(),
papers: z.array(z.string()),
contribution: z.string(),
})).optional(),
});
type RelationshipAnalysis = z.infer<typeof RelationshipSchema>;
export class ComparisonAgent {
private llm: ChatOpenAI;
constructor() {
this.llm = new ChatOpenAI({
modelName: 'gpt-4o',
temperature: 0.2,
});
}
async compareViewpoints(
papers: PaperViewpoint[],
comparisonDimensions: string[]
): Promise<ComparisonResult> {
const comparisonLLM = this.llm.withStructuredOutput(ComparisonResultSchema);
const papersContext = papers.map(p => {
const viewpointsStr = p.viewpoints
.map(v => `- ${v.topic}: ${v.stance} (证据: ${v.evidence})`)
.join('\n');
return `【${p.title}】\n${viewpointsStr}`;
}).join('\n\n');
const response = await comparisonLLM.invoke([
new SystemMessage(`你是学术论文对比分析专家。请从以下维度对比分析多篇论文:
对比维度:${comparisonDimensions.join(', ')}
分析要求:
1. 在每个维度上比较各论文的立场和方法
2. 识别共识和分歧
3. 评估各论文的优缺点
4. 提供综合建议`),
new HumanMessage(`请对比分析以下论文:\n\n${papersContext}`),
]);
return response;
}
async analyzeRelationships(
papers: Array<{
title: string;
summary: string;
keyPoints: string[];
publishedAt?: Date;
}>
): Promise<RelationshipAnalysis> {
const relationshipLLM = this.llm.withStructuredOutput(RelationshipSchema);
const papersContext = papers.map(p => {
return `【${p.title}】${p.publishedAt ? ` (${p.publishedAt.getFullYear()})` : ''}
摘要:${p.summary}
关键点:${p.keyPoints.join('; ')}`;
}).join('\n\n');
const response = await relationshipLLM.invoke([
new SystemMessage(`你是学术文献关系分析专家。请分析以下论文之间的关系:
关系类型:
- supports: 支持/验证另一论文的观点
- contradicts: 与另一论文观点矛盾
- extends: 扩展/深化另一论文的研究
- applies: 应用另一论文的方法/理论
- unrelated: 无直接关系
任务:
1. 分析论文两两之间的关系
2. 识别主题聚类
3. 如果可能,描述研究演进路径`),
new HumanMessage(`请分析以下论文的关系:\n\n${papersContext}`),
]);
return response;
}
async generateComparisonTable(
papers: Array<{
title: string;
methodology: string;
mainFindings: string[];
limitations: string[];
}>,
criteria: string[]
): Promise<{
headers: string[];
rows: Array<{
paper: string;
values: Record<string, string>;
}>;
notes: string[];
}> {
const TableSchema = z.object({
headers: z.array(z.string()),
rows: z.array(z.object({
paper: z.string(),
values: z.record(z.string()),
})),
notes: z.array(z.string()),
});
const tableLLM = this.llm.withStructuredOutput(TableSchema);
const papersContext = papers.map(p => {
return `【${p.title}】
方法:${p.methodology}
发现:${p.mainFindings.join('; ')}
局限:${p.limitations.join('; ')}`;
}).join('\n\n');
const response = await tableLLM.invoke([
new SystemMessage(`请生成论文对比表格。
对比标准:${criteria.join(', ')}
要求:
1. 每个论文一行
2. 每个标准一列
3. 简洁填写每个单元格
4. 添加必要的注释`),
new HumanMessage(papersContext),
]);
return response;
}
async identifyResearchGaps(
papers: Array<{
title: string;
mainFindings: string[];
futureWork: string[];
limitations: string[];
}>
): Promise<{
gaps: Array<{
area: string;
description: string;
mentionedBy: string[];
priority: 'high' | 'medium' | 'low';
}>;
opportunities: string[];
}> {
const GapsSchema = z.object({
gaps: z.array(z.object({
area: z.string(),
description: z.string(),
mentionedBy: z.array(z.string()),
priority: z.enum(['high', 'medium', 'low']),
})),
opportunities: z.array(z.string()),
});
const gapsLLM = this.llm.withStructuredOutput(GapsSchema);
const papersContext = papers.map(p => {
return `【${p.title}】
发现:${p.mainFindings.join('; ')}
局限:${p.limitations.join('; ')}
未来方向:${p.futureWork.join('; ')}`;
}).join('\n\n');
const response = await gapsLLM.invoke([
new SystemMessage(`分析以下论文,识别研究领域的空白和机会:
任务:
1. 识别多篇论文共同指出的研究空白
2. 评估各空白的研究价值和优先级
3. 提出潜在的研究机会`),
new HumanMessage(papersContext),
]);
return response;
}
}
export const comparisonAgent = new ComparisonAgent();4.5 报告撰写 Agent
typescript
// src/agents/report-agent.ts
import { ChatOpenAI } from '@langchain/openai';
import { HumanMessage, SystemMessage } from '@langchain/core/messages';
import { z } from 'zod';
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
interface ReportSection {
title: string;
content: string;
references: string[];
}
interface ResearchData {
topic: string;
papers: Array<{
id: number;
title: string;
authors: string;
summary: string;
keyPoints: string[];
year?: number;
}>;
insights: Array<{
area: string;
findings: string[];
}>;
comparisons: any;
gaps: Array<{
area: string;
description: string;
}>;
}
const ReportOutlineSchema = z.object({
title: z.string(),
sections: z.array(z.object({
id: z.string(),
title: z.string(),
description: z.string(),
subsections: z.array(z.object({
id: z.string(),
title: z.string(),
})).optional(),
})),
estimatedLength: z.number().describe('预计字数'),
});
type ReportOutline = z.infer<typeof ReportOutlineSchema>;
const SectionContentSchema = z.object({
content: z.string().describe('章节内容(Markdown 格式)'),
citations: z.array(z.object({
paperId: z.number(),
context: z.string(),
})).describe('引用的论文'),
keyTakeaways: z.array(z.string()).describe('关键结论'),
});
export class ReportAgent {
private llm: ChatOpenAI;
constructor() {
this.llm = new ChatOpenAI({
modelName: 'gpt-4o',
temperature: 0.3,
});
}
async generateOutline(
researchData: ResearchData,
reportType: 'literature_review' | 'research_summary' | 'technical_report' = 'literature_review'
): Promise<ReportOutline> {
const outlineLLM = this.llm.withStructuredOutput(ReportOutlineSchema);
const templates: Record<string, string> = {
literature_review: `文献综述报告结构:
1. 引言(研究背景、目的、范围)
2. 研究方法(检索策略、筛选标准)
3. 文献分析(按主题/时间/方法分类)
4. 讨论(主要发现、趋势、争议)
5. 结论(总结、建议、未来方向)`,
research_summary: `研究摘要报告结构:
1. 执行摘要
2. 背景介绍
3. 主要发现
4. 方法对比
5. 结论和建议`,
technical_report: `技术报告结构:
1. 概述
2. 技术背景
3. 方法分析
4. 实验结果对比
5. 最佳实践建议
6. 总结`,
};
const dataContext = `研究主题:${researchData.topic}
收集论文数:${researchData.papers.length}
主要研究领域:${researchData.insights.map(i => i.area).join(', ')}
识别的研究空白:${researchData.gaps.map(g => g.area).join(', ')}`;
const response = await outlineLLM.invoke([
new SystemMessage(`你是学术报告撰写专家。请根据研究数据生成报告大纲。
报告类型:${reportType}
参考结构:
${templates[reportType]}`),
new HumanMessage(dataContext),
]);
return response;
}
async writeSection(
sectionId: string,
sectionTitle: string,
researchData: ResearchData,
previousSections: ReportSection[],
guidelines?: string
): Promise<ReportSection> {
const sectionLLM = this.llm.withStructuredOutput(SectionContentSchema);
const relevantPapers = researchData.papers.slice(0, 10);
const papersContext = relevantPapers.map(p =>
`[${p.id}] ${p.title} (${p.year || '年份未知'})
作者:${p.authors}
摘要:${p.summary}
关键点:${p.keyPoints.join('; ')}`
).join('\n\n');
const previousContext = previousSections.length > 0
? `已完成章节:\n${previousSections.map(s => `- ${s.title}`).join('\n')}`
: '';
const response = await sectionLLM.invoke([
new SystemMessage(`你是学术报告撰写专家。请撰写报告的「${sectionTitle}」章节。
要求:
1. 使用 Markdown 格式
2. 引用相关论文(使用 [论文ID] 格式)
3. 保持学术性和客观性
4. 逻辑清晰,过渡自然
${guidelines ? `\n特殊要求:${guidelines}` : ''}`),
new HumanMessage(`研究主题:${researchData.topic}
${previousContext}
可用文献:
${papersContext}
研究洞察:
${researchData.insights.map(i => `- ${i.area}: ${i.findings.slice(0, 3).join('; ')}`).join('\n')}
请撰写「${sectionTitle}」章节。`),
]);
const references = response.citations.map(c => {
const paper = researchData.papers.find(p => p.id === c.paperId);
return paper ? `[${c.paperId}] ${paper.title}` : '';
}).filter(Boolean);
return {
title: sectionTitle,
content: response.content,
references,
};
}
async generateFullReport(
researchData: ResearchData,
outline: ReportOutline
): Promise<{
title: string;
content: string;
references: Array<{
id: number;
citation: string;
}>;
metadata: {
generatedAt: Date;
wordCount: number;
paperCount: number;
};
}> {
const sections: ReportSection[] = [];
for (const section of outline.sections) {
const sectionContent = await this.writeSection(
section.id,
section.title,
researchData,
sections
);
sections.push(sectionContent);
if (section.subsections) {
for (const subsection of section.subsections) {
const subContent = await this.writeSection(
subsection.id,
subsection.title,
researchData,
sections,
`这是「${section.title}」的子章节`
);
sections.push(subContent);
}
}
}
const fullContent = this.assembleReport(outline.title, sections);
const allReferences = new Set<string>();
sections.forEach(s => s.references.forEach(r => allReferences.add(r)));
const references = researchData.papers
.filter(p => Array.from(allReferences).some(r => r.includes(`[${p.id}]`)))
.map(p => ({
id: p.id,
citation: `${JSON.parse(p.authors || '[]').join(', ')}. "${p.title}". ${p.year || ''}`,
}));
return {
title: outline.title,
content: fullContent,
references,
metadata: {
generatedAt: new Date(),
wordCount: fullContent.length,
paperCount: researchData.papers.length,
},
};
}
private assembleReport(title: string, sections: ReportSection[]): string {
let content = `# ${title}\n\n`;
content += `*生成时间:${new Date().toLocaleDateString('zh-CN')}*\n\n`;
content += `---\n\n`;
content += `## 目录\n\n`;
sections.forEach((section, index) => {
content += `${index + 1}. [${section.title}](#${this.slugify(section.title)})\n`;
});
content += `\n---\n\n`;
sections.forEach((section, index) => {
content += `## ${index + 1}. ${section.title}\n\n`;
content += `${section.content}\n\n`;
});
const allReferences = new Set<string>();
sections.forEach(s => s.references.forEach(r => allReferences.add(r)));
if (allReferences.size > 0) {
content += `## 参考文献\n\n`;
Array.from(allReferences).forEach(ref => {
content += `${ref}\n\n`;
});
}
return content;
}
private slugify(text: string): string {
return text
.toLowerCase()
.replace(/[^\w\u4e00-\u9fa5]+/g, '-')
.replace(/^-+|-+$/g, '');
}
async saveReport(
projectId: number,
title: string,
content: string,
outline: ReportOutline,
references: Array<{ id: number; citation: string }>
): Promise<number> {
const report = await prisma.researchReport.create({
data: {
projectId,
title,
content,
outline: JSON.stringify(outline),
references: JSON.stringify(references),
status: 'draft',
},
});
return report.id;
}
async updateReport(
reportId: number,
updates: {
content?: string;
status?: string;
version?: number;
}
): Promise<void> {
await prisma.researchReport.update({
where: { id: reportId },
data: updates,
});
}
}
export const reportAgent = new ReportAgent();第五部分:LangGraph 工作流组装
5.1 状态定义
typescript
// src/graph/state.ts
import { Annotation, messagesStateReducer } from '@langchain/langgraph';
import { BaseMessage } from '@langchain/core/messages';
interface Paper {
id: number;
title: string;
authors: string;
abstract: string;
summary?: string;
keyPoints?: string[];
}
interface ResearchPlan {
understanding: string;
searchStrategy: {
primaryKeywords: string[];
alternativeKeywords: string[];
targetSources: string[];
expectedPapers: number;
};
analysisApproach: {
focusAreas: string[];
comparisonDimensions: string[];
};
outputFormat: {
reportStructure: string[];
};
}
interface GapAnalysis {
hasGaps: boolean;
gaps: Array<{
description: string;
suggestedAction: string;
priority: string;
}>;
completeness: number;
recommendation: string;
}
export const ResearchAssistantState = Annotation.Root({
messages: Annotation<BaseMessage[]>({
reducer: messagesStateReducer,
default: () => [],
}),
projectId: Annotation<number>({
reducer: (_, y) => y,
default: () => 0,
}),
userId: Annotation<number>({
reducer: (_, y) => y,
default: () => 0,
}),
topic: Annotation<string>({
reducer: (_, y) => y,
default: () => '',
}),
currentPhase: Annotation<'planning' | 'searching' | 'analyzing' | 'comparing' | 'writing' | 'complete'>({
reducer: (_, y) => y,
default: () => 'planning',
}),
researchPlan: Annotation<ResearchPlan | null>({
reducer: (_, y) => y,
default: () => null,
}),
collectedPapers: Annotation<Paper[]>({
reducer: (existing, newPapers) => {
const existingIds = new Set(existing.map(p => p.id));
const uniqueNew = newPapers.filter(p => !existingIds.has(p.id));
return [...existing, ...uniqueNew];
},
default: () => [],
}),
analyzedPapers: Annotation<number[]>({
reducer: (existing, newIds) => [...new Set([...existing, ...newIds])],
default: () => [],
}),
extractedInsights: Annotation<Array<{
area: string;
findings: string[];
sources: string[];
}>>({
reducer: (existing, newInsights) => [...existing, ...newInsights],
default: () => [],
}),
comparisonResults: Annotation<any>({
reducer: (_, y) => y,
default: () => null,
}),
gapAnalysis: Annotation<GapAnalysis | null>({
reducer: (_, y) => y,
default: () => null,
}),
reportOutline: Annotation<any>({
reducer: (_, y) => y,
default: () => null,
}),
reportContent: Annotation<string>({
reducer: (_, y) => y,
default: () => '',
}),
searchHistory: Annotation<string[]>({
reducer: (existing, newSearches) => [...existing, ...newSearches],
default: () => [],
}),
iterationCount: Annotation<number>({
reducer: (_, y) => y,
default: () => 0,
}),
maxIterations: Annotation<number>({
reducer: (_, y) => y,
default: () => 5,
}),
error: Annotation<string | null>({
reducer: (_, y) => y,
default: () => null,
}),
});
export type ResearchAssistantStateType = typeof ResearchAssistantState.State;5.2 工作流节点实现
typescript
// src/graph/nodes.ts
import { ResearchAssistantStateType } from './state';
import { researchPlanner } from '../agents/research-planner';
import { searchAgent } from '../agents/search-agent';
import { summaryAgent } from '../agents/summary-agent';
import { comparisonAgent } from '../agents/comparison-agent';
import { reportAgent } from '../agents/report-agent';
import { contextManager } from '../context/context-manager';
import { AIMessage } from '@langchain/core/messages';
export async function planningNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.log('[Planning] Creating research plan...');
try {
const plan = await researchPlanner.createResearchPlan(
state.topic,
undefined,
{
maxPapers: 20,
}
);
contextManager.updateResearchState(state.projectId, {
topic: state.topic,
keywords: plan.searchStrategy.primaryKeywords,
currentPhase: 'search',
});
return {
researchPlan: plan,
currentPhase: 'searching',
messages: [
new AIMessage({
content: `研究计划制定完成!\n\n**主题理解**:${plan.understanding}\n\n**检索策略**:\n- 主要关键词:${plan.searchStrategy.primaryKeywords.join(', ')}\n- 目标数据源:${plan.searchStrategy.targetSources.join(', ')}\n- 预计论文数:${plan.searchStrategy.expectedPapers}`,
}),
],
};
} catch (error) {
return {
error: `Planning failed: ${error instanceof Error ? error.message : 'Unknown error'}`,
};
}
}
export async function searchingNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.log('[Searching] Executing search strategy...');
if (!state.researchPlan) {
return { error: 'No research plan available' };
}
try {
const keywords = state.researchPlan.searchStrategy.primaryKeywords;
const sources = state.researchPlan.searchStrategy.targetSources;
const searchPromises = keywords.slice(0, 3).map(async (keyword) => {
return searchAgent.search(keyword, {
userId: state.userId,
projectId: state.projectId,
maxPapers: 5,
sources,
});
});
await Promise.all(searchPromises);
const papers = await fetchProjectPapers(state.projectId);
return {
collectedPapers: papers,
searchHistory: keywords,
currentPhase: 'analyzing',
messages: [
new AIMessage({
content: `文献检索完成!共找到 ${papers.length} 篇相关论文。\n\n正在进行论文分析...`,
}),
],
};
} catch (error) {
return {
error: `Search failed: ${error instanceof Error ? error.message : 'Unknown error'}`,
};
}
}
export async function analyzingNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.log('[Analyzing] Analyzing collected papers...');
try {
const unanalyzedPapers = state.collectedPapers.filter(
p => !state.analyzedPapers.includes(p.id)
);
if (unanalyzedPapers.length === 0) {
return { currentPhase: 'comparing' };
}
const papersToAnalyze = unanalyzedPapers.slice(0, 5);
const analyses = await summaryAgent.analyzeMultiplePapers(
papersToAnalyze.map(p => p.id),
state.topic
);
const focusAreas = state.researchPlan?.analysisApproach.focusAreas || [];
const insights = await summaryAgent.extractKeyInsights(analyses, focusAreas);
const analyzedIds = papersToAnalyze.map(p => p.id);
contextManager.updateResearchState(state.projectId, {
currentPhase: 'analyze',
});
analyzedIds.forEach(id => {
contextManager.addProcessedPaper(state.projectId, id);
});
return {
analyzedPapers: analyzedIds,
extractedInsights: [
{
area: 'general',
findings: insights.consensus,
sources: papersToAnalyze.map(p => p.title),
},
...insights.insights,
],
currentPhase: 'comparing',
messages: [
new AIMessage({
content: `论文分析完成!已分析 ${analyzedIds.length} 篇论文。\n\n**主要共识**:\n${insights.consensus.map(c => `- ${c}`).join('\n')}\n\n正在进行观点对比...`,
}),
],
};
} catch (error) {
return {
error: `Analysis failed: ${error instanceof Error ? error.message : 'Unknown error'}`,
};
}
}
export async function comparingNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.log('[Comparing] Comparing viewpoints...');
try {
const dimensions = state.researchPlan?.analysisApproach.comparisonDimensions || [
'methodology',
'findings',
'limitations',
];
const paperViewpoints = state.collectedPapers
.filter(p => state.analyzedPapers.includes(p.id))
.map(p => ({
paperId: p.id,
title: p.title,
viewpoints: (p.keyPoints || []).map(kp => ({
topic: 'general',
stance: kp,
evidence: p.abstract?.slice(0, 200) || '',
})),
}));
const comparison = await comparisonAgent.compareViewpoints(
paperViewpoints,
dimensions
);
const relationships = await comparisonAgent.analyzeRelationships(
state.collectedPapers
.filter(p => state.analyzedPapers.includes(p.id))
.map(p => ({
title: p.title,
summary: p.summary || p.abstract || '',
keyPoints: p.keyPoints || [],
}))
);
contextManager.updateResearchState(state.projectId, {
currentPhase: 'compare',
});
return {
comparisonResults: {
comparison,
relationships,
},
currentPhase: 'writing',
messages: [
new AIMessage({
content: `观点对比完成!\n\n**主要发现**:\n${comparison.overallSummary}\n\n正在生成研究报告...`,
}),
],
};
} catch (error) {
return {
error: `Comparison failed: ${error instanceof Error ? error.message : 'Unknown error'}`,
};
}
}
export async function gapCheckNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.log('[Gap Check] Checking information completeness...');
if (!state.researchPlan) {
return { currentPhase: 'writing' };
}
try {
const gapAnalysis = await researchPlanner.analyzeInformationGaps(
state.researchPlan,
state.collectedPapers.map(p => ({
title: p.title,
abstract: p.abstract || '',
summary: p.summary,
})),
state.extractedInsights.flatMap(i => i.findings)
);
if (gapAnalysis.hasGaps &&
gapAnalysis.completeness < 70 &&
state.iterationCount < state.maxIterations) {
const supplementarySearches = await researchPlanner.generateSupplementarySearches(
gapAnalysis.gaps,
state.searchHistory
);
return {
gapAnalysis,
iterationCount: state.iterationCount + 1,
searchHistory: [
...state.searchHistory,
...supplementarySearches.map(s => s.query),
],
currentPhase: 'searching',
messages: [
new AIMessage({
content: `信息完整度:${gapAnalysis.completeness}%\n\n发现信息缺口,正在补充检索...\n\n**需要补充的领域**:\n${gapAnalysis.gaps.map(g => `- ${g.description}`).join('\n')}`,
}),
],
};
}
return {
gapAnalysis,
currentPhase: 'writing',
};
} catch (error) {
return { currentPhase: 'writing' };
}
}
export async function writingNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.log('[Writing] Generating research report...');
try {
const researchData = {
topic: state.topic,
papers: state.collectedPapers
.filter(p => state.analyzedPapers.includes(p.id))
.map(p => ({
id: p.id,
title: p.title,
authors: p.authors,
summary: p.summary || p.abstract || '',
keyPoints: p.keyPoints || [],
})),
insights: state.extractedInsights,
comparisons: state.comparisonResults,
gaps: state.gapAnalysis?.gaps.map(g => ({
area: g.suggestedAction,
description: g.description,
})) || [],
};
const outline = await reportAgent.generateOutline(researchData, 'literature_review');
const report = await reportAgent.generateFullReport(researchData, outline);
await reportAgent.saveReport(
state.projectId,
report.title,
report.content,
outline,
report.references
);
contextManager.updateResearchState(state.projectId, {
currentPhase: 'write',
reportDraft: report.content,
});
return {
reportOutline: outline,
reportContent: report.content,
currentPhase: 'complete',
messages: [
new AIMessage({
content: `研究报告生成完成!\n\n**报告标题**:${report.title}\n**字数**:${report.metadata.wordCount}\n**引用论文**:${report.metadata.paperCount} 篇\n\n报告已保存,您可以在文献管理中查看和导出。`,
}),
],
};
} catch (error) {
return {
error: `Report generation failed: ${error instanceof Error ? error.message : 'Unknown error'}`,
};
}
}
async function fetchProjectPapers(projectId: number): Promise<any[]> {
const { PrismaClient } = await import('@prisma/client');
const prisma = new PrismaClient();
const projectPapers = await prisma.projectPaper.findMany({
where: { projectId },
include: { paper: true },
orderBy: { relevance: 'desc' },
});
return projectPapers.map(pp => ({
id: pp.paper.id,
title: pp.paper.title,
authors: pp.paper.authors,
abstract: pp.paper.abstract,
summary: pp.paper.summary,
keyPoints: pp.paper.keyPoints ? JSON.parse(pp.paper.keyPoints) : [],
}));
}5.3 完整工作流组装
typescript
// src/graph/research-assistant-graph.ts
import { StateGraph, END } from '@langchain/langgraph';
import { ResearchAssistantState, ResearchAssistantStateType } from './state';
import {
planningNode,
searchingNode,
analyzingNode,
comparingNode,
gapCheckNode,
writingNode,
} from './nodes';
function routeAfterPlanning(state: ResearchAssistantStateType): string {
if (state.error) return 'error';
return 'searching';
}
function routeAfterSearching(state: ResearchAssistantStateType): string {
if (state.error) return 'error';
if (state.collectedPapers.length === 0) return 'error';
return 'analyzing';
}
function routeAfterAnalyzing(state: ResearchAssistantStateType): string {
if (state.error) return 'error';
return 'comparing';
}
function routeAfterComparing(state: ResearchAssistantStateType): string {
if (state.error) return 'error';
return 'gap_check';
}
function routeAfterGapCheck(state: ResearchAssistantStateType): string {
if (state.error) return 'error';
if (state.currentPhase === 'searching') {
return 'searching';
}
return 'writing';
}
function routeAfterWriting(state: ResearchAssistantStateType): string {
if (state.error) return 'error';
return END;
}
async function errorNode(
state: ResearchAssistantStateType
): Promise<Partial<ResearchAssistantStateType>> {
console.error('[Error]', state.error);
return {
messages: [
{
_getType: () => 'ai',
content: `研究过程中发生错误:${state.error}\n\n请检查配置或重试。`,
} as any,
],
};
}
export function createResearchAssistantGraph() {
const workflow = new StateGraph(ResearchAssistantState)
.addNode('planning', planningNode)
.addNode('searching', searchingNode)
.addNode('analyzing', analyzingNode)
.addNode('comparing', comparingNode)
.addNode('gap_check', gapCheckNode)
.addNode('writing', writingNode)
.addNode('error', errorNode)
.addEdge('__start__', 'planning')
.addConditionalEdges('planning', routeAfterPlanning, {
searching: 'searching',
error: 'error',
})
.addConditionalEdges('searching', routeAfterSearching, {
analyzing: 'analyzing',
error: 'error',
})
.addConditionalEdges('analyzing', routeAfterAnalyzing, {
comparing: 'comparing',
error: 'error',
})
.addConditionalEdges('comparing', routeAfterComparing, {
gap_check: 'gap_check',
error: 'error',
})
.addConditionalEdges('gap_check', routeAfterGapCheck, {
searching: 'searching',
writing: 'writing',
error: 'error',
})
.addConditionalEdges('writing', routeAfterWriting, {
[END]: END,
error: 'error',
})
.addEdge('error', END);
return workflow.compile();
}
export async function runResearchAssistant(
topic: string,
userId: number,
projectId: number
) {
const graph = createResearchAssistantGraph();
const initialState = {
topic,
userId,
projectId,
maxIterations: 3,
};
console.log(`\n${'='.repeat(60)}`);
console.log(`Starting research on: ${topic}`);
console.log(`${'='.repeat(60)}\n`);
const stream = await graph.stream(initialState, {
recursionLimit: 50,
});
let finalState: ResearchAssistantStateType | null = null;
for await (const event of stream) {
const nodeName = Object.keys(event)[0];
const nodeState = event[nodeName];
console.log(`\n[${nodeName.toUpperCase()}] Phase completed`);
if (nodeState.messages && nodeState.messages.length > 0) {
const lastMessage = nodeState.messages[nodeState.messages.length - 1];
console.log(`Message: ${lastMessage.content?.slice(0, 200)}...`);
}
finalState = nodeState;
}
console.log(`\n${'='.repeat(60)}`);
console.log('Research completed!');
console.log(`${'='.repeat(60)}\n`);
return finalState;
}第六部分:API 接口与前端集成
6.1 Express 路由
typescript
// src/routes/research.ts
import { Router, Request, Response } from 'express';
import { PrismaClient } from '@prisma/client';
import { createResearchAssistantGraph, runResearchAssistant } from '../graph/research-assistant-graph';
import { contextManager } from '../context/context-manager';
import { mcpManager } from '../mcp/client-manager';
const router = Router();
const prisma = new PrismaClient();
router.post('/projects', async (req: Request, res: Response) => {
try {
const { userId, title, topic, keywords, description } = req.body;
const project = await prisma.researchProject.create({
data: {
userId,
title,
topic,
keywords: JSON.stringify(keywords || []),
description,
},
});
res.json({ success: true, project });
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.get('/projects/:id', async (req: Request, res: Response) => {
try {
const projectId = parseInt(req.params.id);
const project = await prisma.researchProject.findUnique({
where: { id: projectId },
include: {
papers: {
include: { paper: true },
orderBy: { relevance: 'desc' },
},
reports: {
orderBy: { createdAt: 'desc' },
},
sessions: {
orderBy: { createdAt: 'desc' },
take: 1,
},
},
});
if (!project) {
return res.status(404).json({ success: false, error: 'Project not found' });
}
res.json({ success: true, project });
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.post('/projects/:id/start', async (req: Request, res: Response) => {
try {
const projectId = parseInt(req.params.id);
const { userId } = req.body;
const project = await prisma.researchProject.findUnique({
where: { id: projectId },
});
if (!project) {
return res.status(404).json({ success: false, error: 'Project not found' });
}
res.json({ success: true, message: 'Research started' });
runResearchAssistant(project.topic, userId, projectId)
.then((result) => {
console.log('Research completed:', result?.currentPhase);
})
.catch((error) => {
console.error('Research failed:', error);
});
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.get('/projects/:id/stream', async (req: Request, res: Response) => {
const projectId = parseInt(req.params.id);
const userId = parseInt(req.query.userId as string);
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
const project = await prisma.researchProject.findUnique({
where: { id: projectId },
});
if (!project) {
res.write(`data: ${JSON.stringify({ type: 'error', message: 'Project not found' })}\n\n`);
res.end();
return;
}
const graph = createResearchAssistantGraph();
const initialState = {
topic: project.topic,
userId,
projectId,
maxIterations: 3,
};
try {
const stream = await graph.stream(initialState, {
recursionLimit: 50,
});
for await (const event of stream) {
const nodeName = Object.keys(event)[0];
const nodeState = event[nodeName];
const update = {
type: 'progress',
phase: nodeName,
state: {
currentPhase: nodeState.currentPhase,
papersCount: nodeState.collectedPapers?.length || 0,
analyzedCount: nodeState.analyzedPapers?.length || 0,
completeness: nodeState.gapAnalysis?.completeness || 0,
error: nodeState.error,
},
message: nodeState.messages?.[nodeState.messages.length - 1]?.content || null,
};
res.write(`data: ${JSON.stringify(update)}\n\n`);
}
res.write(`data: ${JSON.stringify({ type: 'complete' })}\n\n`);
} catch (error) {
res.write(`data: ${JSON.stringify({
type: 'error',
message: error instanceof Error ? error.message : 'Unknown error',
})}\n\n`);
}
res.end();
});
router.get('/projects/:id/papers', async (req: Request, res: Response) => {
try {
const projectId = parseInt(req.params.id);
const { page = 1, limit = 20 } = req.query;
const papers = await prisma.projectPaper.findMany({
where: { projectId },
include: { paper: true },
orderBy: { relevance: 'desc' },
skip: (Number(page) - 1) * Number(limit),
take: Number(limit),
});
const total = await prisma.projectPaper.count({
where: { projectId },
});
res.json({
success: true,
papers: papers.map(pp => ({
...pp.paper,
relevance: pp.relevance,
notes: pp.notes,
tags: pp.tags ? JSON.parse(pp.tags) : [],
})),
pagination: {
page: Number(page),
limit: Number(limit),
total,
totalPages: Math.ceil(total / Number(limit)),
},
});
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.get('/projects/:id/reports', async (req: Request, res: Response) => {
try {
const projectId = parseInt(req.params.id);
const reports = await prisma.researchReport.findMany({
where: { projectId },
orderBy: { createdAt: 'desc' },
});
res.json({ success: true, reports });
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.get('/reports/:id', async (req: Request, res: Response) => {
try {
const reportId = parseInt(req.params.id);
const report = await prisma.researchReport.findUnique({
where: { id: reportId },
});
if (!report) {
return res.status(404).json({ success: false, error: 'Report not found' });
}
res.json({ success: true, report });
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.get('/reports/:id/export', async (req: Request, res: Response) => {
try {
const reportId = parseInt(req.params.id);
const format = req.query.format as string || 'markdown';
const report = await prisma.researchReport.findUnique({
where: { id: reportId },
});
if (!report) {
return res.status(404).json({ success: false, error: 'Report not found' });
}
if (format === 'markdown') {
res.setHeader('Content-Type', 'text/markdown');
res.setHeader('Content-Disposition', `attachment; filename="${report.title}.md"`);
res.send(report.content);
} else if (format === 'html') {
const { marked } = await import('marked');
const html = `
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>${report.title}</title>
<style>
body { max-width: 800px; margin: 0 auto; padding: 20px; font-family: system-ui; }
h1 { color: #333; }
h2 { color: #555; border-bottom: 1px solid #eee; padding-bottom: 10px; }
code { background: #f5f5f5; padding: 2px 6px; border-radius: 4px; }
pre { background: #f5f5f5; padding: 15px; border-radius: 8px; overflow-x: auto; }
</style>
</head>
<body>
${marked(report.content)}
</body>
</html>`;
res.setHeader('Content-Type', 'text/html');
res.setHeader('Content-Disposition', `attachment; filename="${report.title}.html"`);
res.send(html);
} else {
res.status(400).json({ success: false, error: 'Unsupported format' });
}
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
router.post('/chat', async (req: Request, res: Response) => {
try {
const { projectId, userId, message } = req.body;
let session = await prisma.researchSession.findFirst({
where: { projectId },
orderBy: { createdAt: 'desc' },
});
if (!session) {
session = await prisma.researchSession.create({
data: { projectId },
});
}
await prisma.message.create({
data: {
sessionId: session.id,
role: 'user',
content: message,
},
});
const context = await contextManager.buildContext(projectId, message, session.id);
res.json({
success: true,
sessionId: session.id,
context: {
tokenCount: context.tokenCount,
relevantPapersCount: context.relevantPapers.length,
},
});
} catch (error) {
res.status(500).json({
success: false,
error: error instanceof Error ? error.message : 'Unknown error',
});
}
});
export default router;6.2 应用入口
typescript
// src/index.ts
import express from 'express';
import cors from 'cors';
import { config } from 'dotenv';
import researchRoutes from './routes/research';
import { mcpManager } from './mcp/client-manager';
import { contextManager } from './context/context-manager';
config();
const app = express();
const PORT = process.env.PORT || 3000;
app.use(cors());
app.use(express.json());
app.use('/api/research', researchRoutes);
app.get('/health', (req, res) => {
res.json({ status: 'ok', timestamp: new Date().toISOString() });
});
async function startServer() {
try {
console.log('Initializing MCP connections...');
await mcpManager.connectAll();
console.log('MCP servers connected:', mcpManager.listConnectedServers());
console.log('Initializing context manager...');
await contextManager.initialize();
app.listen(PORT, () => {
console.log(`Server running on http://localhost:${PORT}`);
});
} catch (error) {
console.error('Failed to start server:', error);
process.exit(1);
}
}
process.on('SIGTERM', async () => {
console.log('Shutting down...');
await mcpManager.disconnectAll();
process.exit(0);
});
startServer();第七部分:项目结构
research-assistant/
├── src/
│ ├── index.ts # 应用入口
│ ├── agents/
│ │ ├── research-planner.ts # 研究规划器
│ │ ├── search-agent.ts # 文献检索 Agent
│ │ ├── summary-agent.ts # 摘要提取 Agent
│ │ ├── comparison-agent.ts # 对比分析 Agent
│ │ └── report-agent.ts # 报告撰写 Agent
│ ├── context/
│ │ ├── context-manager.ts # 上下文管理器
│ │ └── document-processor.ts # 长文档处理
│ ├── graph/
│ │ ├── state.ts # 状态定义
│ │ ├── nodes.ts # 工作流节点
│ │ └── research-assistant-graph.ts # 工作流组装
│ ├── mcp/
│ │ ├── client-manager.ts # MCP 客户端管理
│ │ └── servers/
│ │ ├── arxiv-server.ts # arXiv MCP Server
│ │ ├── semantic-scholar-server.ts # Semantic Scholar Server
│ │ ├── pdf-server.ts # PDF 处理 Server
│ │ └── web-search-server.ts # 网络搜索 Server
│ ├── routes/
│ │ └── research.ts # API 路由
│ └── utils/
│ └── helpers.ts # 工具函数
├── prisma/
│ └── schema.prisma # 数据库模型
├── tests/
│ ├── agents/
│ ├── graph/
│ └── mcp/
├── package.json
├── tsconfig.json
└── .env.example第八部分:核心概念总结
8.1 Agentic RAG 的核心价值
┌─────────────────────────────────────────────────────────────┐
│ Agentic RAG 核心价值 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 1. 主动性 (Proactivity) │
│ • 主动规划检索策略 │
│ • 主动发现信息缺口 │
│ • 主动补充和验证信息 │
│ │
│ 2. 迭代性 (Iteration) │
│ • 多轮检索,逐步深入 │
│ • 根据反馈调整策略 │
│ • 直到信息充足才停止 │
│ │
│ 3. 智能性 (Intelligence) │
│ • 理解研究问题的本质 │
│ • 评估信息质量和相关性 │
│ • 整合多源信息形成洞察 │
│ │
│ 4. 结构化 (Structured) │
│ • 有计划、有步骤地执行 │
│ • 输出结构化的研究成果 │
│ • 可追溯的推理过程 │
│ │
└─────────────────────────────────────────────────────────────┘8.2 上下文管理策略
┌─────────────────────────────────────────────────────────────┐
│ 上下文管理策略 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 挑战:LLM 上下文窗口有限,但研究需要处理大量信息 │
│ │
│ 解决方案: │
│ │
│ 1. 分层存储 │
│ ┌──────────────┐ │
│ │ 短期记忆 │ ← 当前会话、工作状态 │
│ ├──────────────┤ │
│ │ 长期记忆 │ ← 已处理论文、提取摘要 │
│ ├──────────────┤ │
│ │ 向量存储 │ ← 语义检索、快速召回 │
│ └──────────────┘ │
│ │
│ 2. 智能选择 │
│ • 根据当前问题选择相关内容 │
│ • 使用向量相似度排序 │
│ • 只加载必要的信息 │
│ │
│ 3. 动态压缩 │
│ • 历史对话自动摘要 │
│ • 长文档分段处理 │
│ • Token 超限时智能裁剪 │
│ │
└─────────────────────────────────────────────────────────────┘8.3 MCP 集成模式
┌─────────────────────────────────────────────────────────────┐
│ MCP 集成最佳实践 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 1. Server 设计原则 │
│ • 单一职责:每个 Server 专注一类功能 │
│ • 标准接口:遵循 MCP 协议规范 │
│ • 错误处理:优雅处理各种异常 │
│ │
│ 2. Client 管理 │
│ • 连接池:复用连接,减少开销 │
│ • 工具路由:根据工具名自动路由到对应 Server │
│ • 生命周期:正确管理连接的创建和销毁 │
│ │
│ 3. 与 LangChain 集成 │
│ • 工具适配:将 MCP 工具转换为 LangChain Tool │
│ • 类型安全:使用 Zod Schema 验证输入输出 │
│ • 错误传递:正确处理和传递工具调用错误 │
│ │
└─────────────────────────────────────────────────────────────┘总结
本项目实现了一个完整的 AI 研究助手,核心特点:
Agentic RAG 架构
- 主动规划检索策略
- 多轮迭代检索
- 自动发现和填补信息缺口
- 智能整合多源信息
多 Agent 协作
- 研究规划器:统筹协调
- 文献检索 Agent:多源搜索
- 摘要提取 Agent:信息提取
- 对比分析 Agent:观点对比
- 报告撰写 Agent:报告生成
MCP 工具集成
- arXiv 学术搜索
- Semantic Scholar 文献检索
- PDF 文档处理
- 标准化工具接口
上下文管理
- 分层存储策略
- 智能内容选择
- 动态压缩机制
- 长文档分段处理
LangGraph 工作流
- 状态驱动流程
- 条件路由控制
- 迭代循环支持
- 错误处理机制
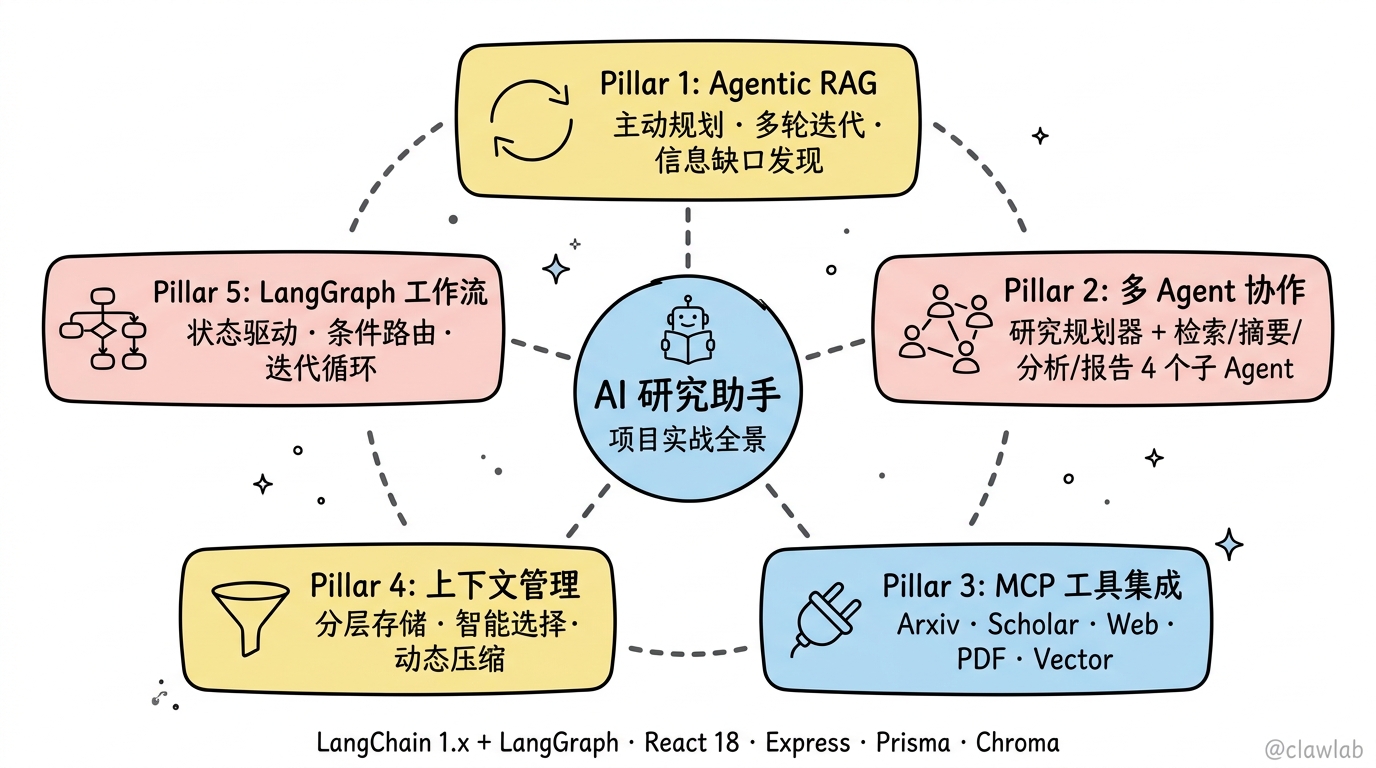
这个项目展示了如何构建一个复杂的、生产级别的 AI 研究助手系统。