
主题
LangChain 教程 09|长期记忆:跨会话持久化存储
📖 本篇导读:这是 LangChain 系列教程的第 9 篇。本篇将深入讲解长期记忆与短期记忆的区别、Store 的使用方法、命名空间组织和内容搜索。读完预计需要 8 分钟。
简单来说
长期记忆是 LangChain 中让 AI 代理能够在不同会话之间保持信息的系统,就像人类的长期记忆一样,它能够记住用户的偏好、历史交互和重要信息,即使在关闭应用后重新打开,这些信息依然存在。长期记忆通过 Store(存储)来实现,支持命名空间组织、内容过滤和向量相似度搜索。
本节目标
- 理解长期记忆与短期记忆的区别和关系
- 掌握 Store 的基本概念和使用方法
- 学会在工具中读取和写入长期记忆
- 了解命名空间组织和内容搜索
- 掌握长期记忆的最佳实践
什么是长期记忆?
问题驱动
在构建 AI 应用时,我们经常遇到以下需求:
- 用户希望 AI 记住他们的偏好设置,下次登录时自动应用
- 客服系统需要记住用户的历史问题和解决方案
- 个性化推荐系统需要持久化用户的兴趣标签
- 知识库系统需要存储和检索大量的文档和信息
短期记忆只能在单个会话中保持上下文,一旦会话结束,信息就会丢失。长期记忆正是为了解决这些跨会话持久化需求而设计的。
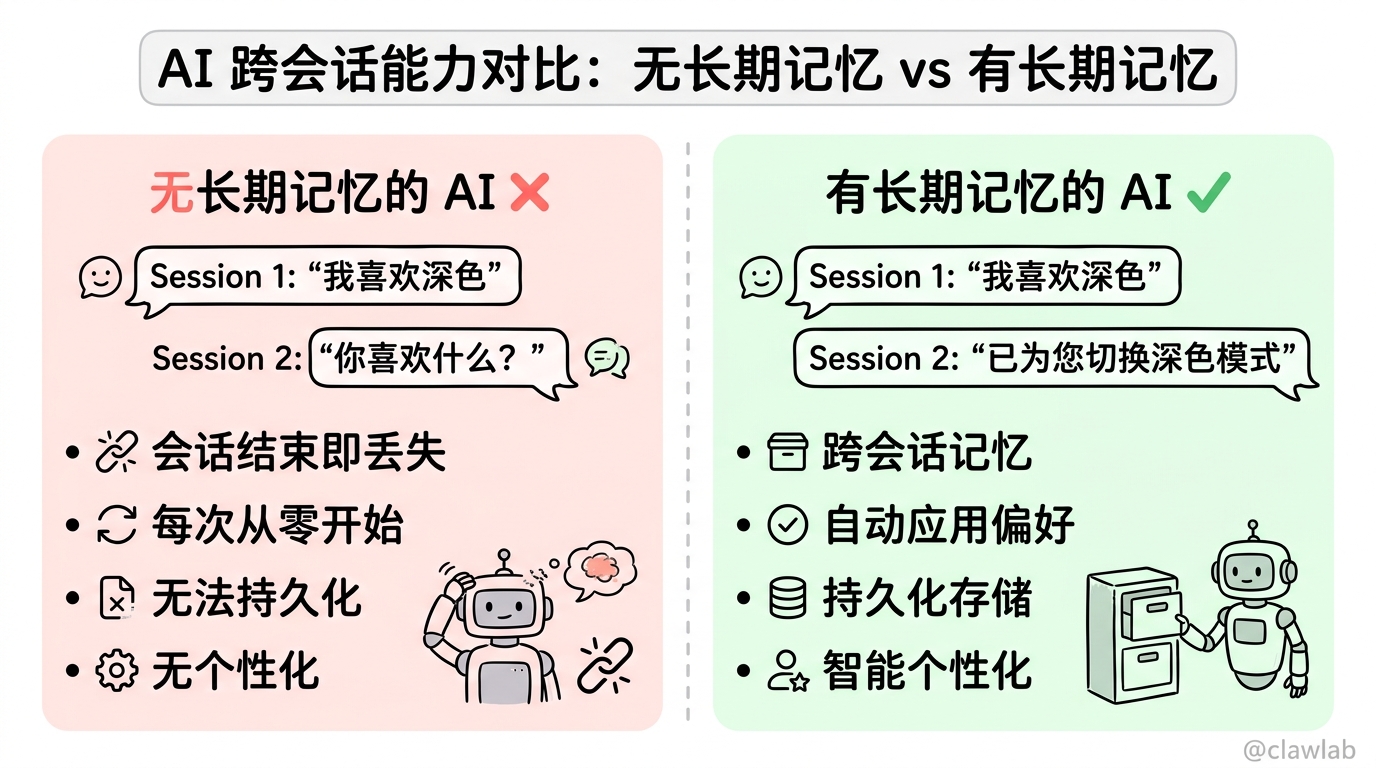
核心概念
长期记忆使用 LangGraph 的持久化机制,将记忆存储为 JSON 文档。每条记忆通过命名空间(namespace)和键(key)进行组织,类似于文件系统中的文件夹和文件名。
类比教学
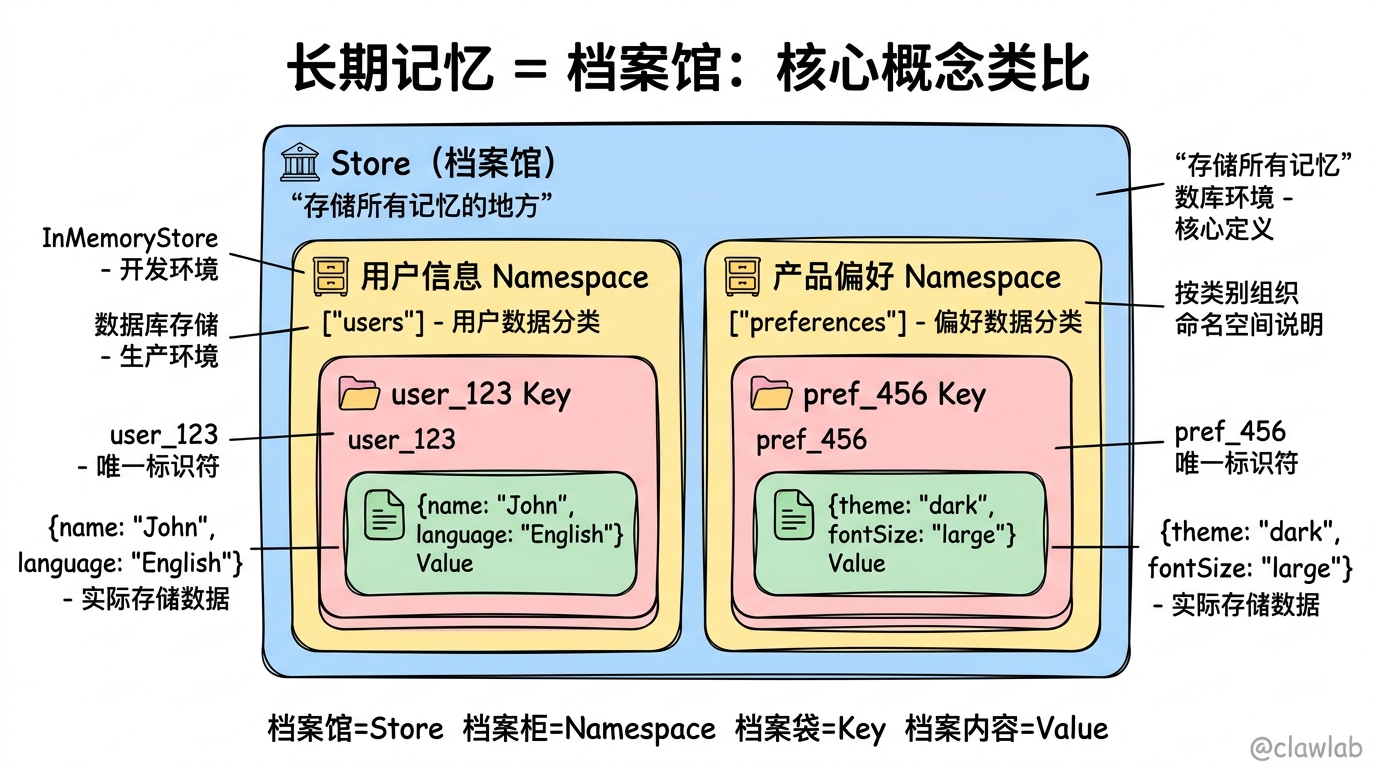
想象一下长期记忆就像一个档案馆:
- 档案馆(Store):存储所有记忆的地方
- 档案柜(Namespace):按类别组织的分类系统,如"用户信息"、"产品偏好"
- 档案袋(Key):每个具体记录的唯一标识符
- 档案内容(Value):实际存储的数据,如用户名、偏好设置
与短期记忆(会议记录本)不同,长期记忆(档案馆)中的信息可以在任何时候被检索和更新,不会因为"会议结束"而丢失。
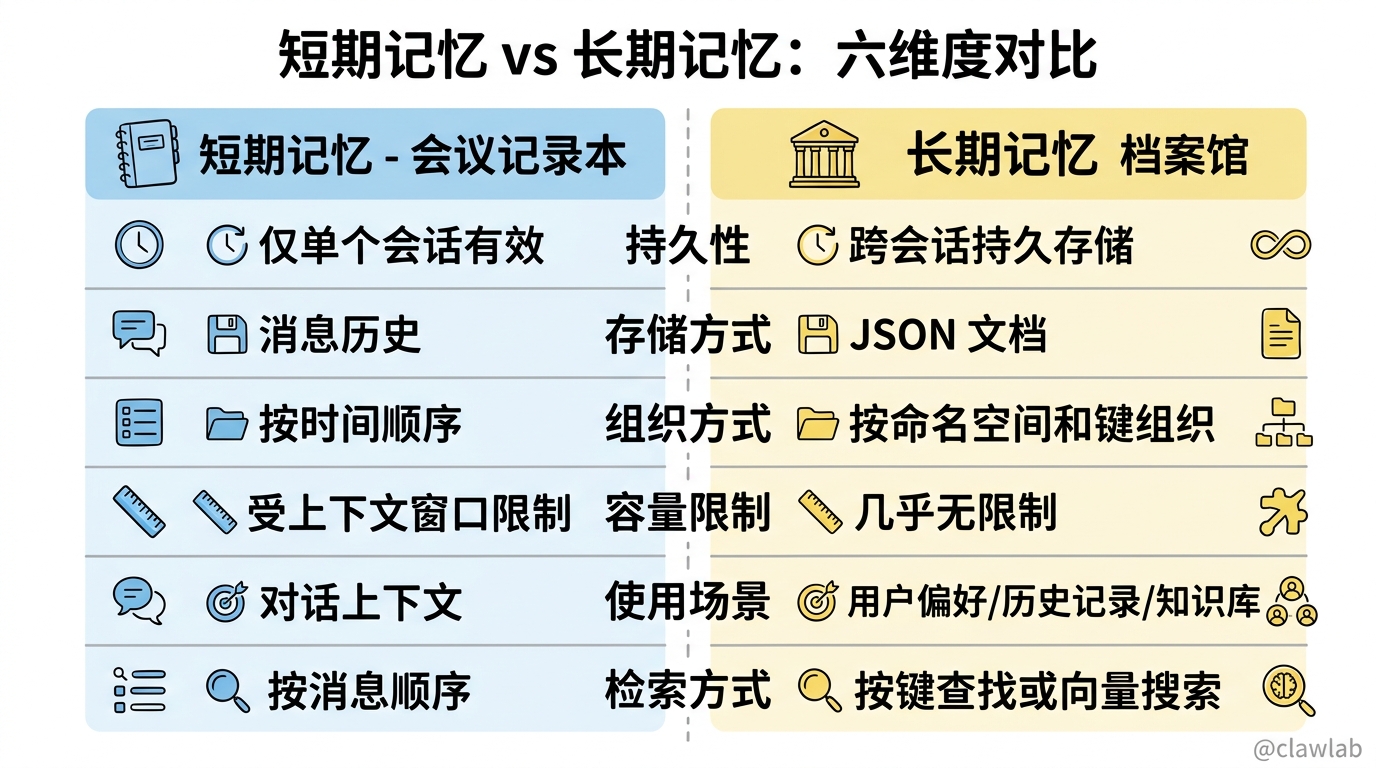
长期记忆 vs 短期记忆
| 特性 | 短期记忆 | 长期记忆 |
|---|---|---|
| 持久性 | 仅在单个会话中有效 | 跨会话持久存储 |
| 存储方式 | 消息历史 | JSON 文档 |
| 组织方式 | 按时间顺序 | 按命名空间和键组织 |
| 容量限制 | 受上下文窗口限制 | 几乎无限制 |
| 使用场景 | 对话上下文 | 用户偏好、历史记录、知识库 |
| 检索方式 | 按消息顺序 | 按键查找或向量搜索 |
基本使用
创建 Store
Store 是存储长期记忆的容器,开发时可以使用 InMemoryStore,生产环境中应该使用数据库支持的存储。
typescript
import { InMemoryStore } from "@langchain/langgraph";
import { OpenAIEmbeddings } from "@langchain/openai";
// 方式一:创建基础存储(不带向量搜索,仅支持精确匹配查询)
const basicStore = new InMemoryStore();
// 方式二:创建带向量搜索能力的存储(推荐,支持语义搜索)
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
});
const store = new InMemoryStore({
index: {
embeddings,
dims: 1536,
},
});
// 存入两条记忆
await store.put(["user_123", "memories"], "1", { text: "I love pizza" });
await store.put(["user_123", "memories"], "2", { text: "I am a plumber" });
// 语义搜索:输入"I'm hungry",会匹配到"I love pizza"(语义相关)
const results = await store.search(["user_123", "memories"], {
query: "I'm hungry",
limit: 1,
});
console.log(results[0].value); // { text: "I love pizza" }💡 两种 Store 的区别:
- 基础 Store(不传
index):只能通过get(namespace, key)精确查找,或通过search的filter做字段精确匹配- 带向量索引的 Store(传
index):支持query语义搜索——输入一句自然语言,Store 会自动计算文本嵌入(embedding),然后按向量相似度排序返回最相关的记忆
text-embedding-3-small是 OpenAI 的嵌入模型,输出 1536 维向量,所以dims: 1536。如果换成其他嵌入模型,dims也需要对应调整。
⚠️ 数据存在哪里?
上面两种方式用的都是
InMemoryStore——数据存储在 Node.js 进程的内存(RAM) 中,本质上就是一个 JavaScript 的Map对象。这意味着:
- ✅ 读写极快:没有网络 IO,直接操作内存
- ✅ 零配置:不需要安装数据库,开箱即用
- ❌ 进程重启即丢失:关掉程序、服务重启、部署更新,数据全没了
- ❌ 不能跨实例共享:如果你有多台服务器,每台的内存是独立的
所以
InMemoryStore只适合开发和测试。生产环境应该换成数据库持久化存储:typescript// 生产环境:使用 PostgreSQL 持久化存储 import { PostgresStore } from "@langchain/langgraph-checkpoint-postgres/store"; import { OpenAIEmbeddings } from "@langchain/openai"; const store = PostgresStore.fromConnString( "postgresql://user:pass@localhost:5432/mydb", { index: { embeddings: new OpenAIEmbeddings({ model: "text-embedding-3-small" }), dims: 1536, }, } ); await store.setup();
存储方式 数据存在哪 持久化 适用场景 InMemoryStoreNode.js 进程内存 ❌ 进程结束即丢失 开发、测试、快速原型 PostgresStorePostgreSQL 数据库 ✅ 磁盘持久化 生产环境 API 完全一致——
put、get、search用法不变,只是换一下初始化方式。
❓ 短期记忆也能存数据库,那和长期记忆有什么区别?
确实,短期记忆(Checkpointer)和长期记忆(Store)都可以存到 PostgreSQL 等数据库里。它们的区别不在于"存在哪",而在于"存什么"和"怎么用":
短期记忆(Checkpointer) 长期记忆(Store) 存什么 整个图的状态快照(包含完整对话消息列表、所有 state 字段) 自定义的 JSON 文档(如用户偏好、个人资料、学习到的规则) 作用域 绑定到 thread_id——不同对话线程之间隔离按自定义 namespace组织——可以跨线程共享生命周期 跟着对话走,对话结束可以清理 长期留存,除非主动删除 写入方式 自动——Agent 每走一步,Checkpointer 自动保存 手动——需要代码显式调用 store.put()典型数据 [用户消息1, AI回复1, 用户消息2, AI回复2, ...]{ name: "Alice", language: "zh", likes: ["pizza"] }类比 聊天窗口的消息记录 用户个人档案 / 偏好设置 用一个场景来理解:
用户 Alice 跟 Agent 聊了 3 次(3 个 thread): Thread 1: "我叫 Alice,我喜欢吃披萨" Thread 2: "帮我推荐今晚吃什么" Thread 3: "上次推荐的那家店怎么样?" ┌─────────────────────────────────────────────┐ │ 短期记忆(Checkpointer) │ │ │ │ thread_1 的消息: [我叫Alice..., 你好Alice...] │ ← 每个 thread 独立 │ thread_2 的消息: [帮我推荐..., 推荐XX...] │ ← 互不可见 │ thread_3 的消息: [上次推荐的..., ...] │ └─────────────────────────────────────────────┘ ┌─────────────────────────────────────────────┐ │ 长期记忆(Store) │ │ │ │ ["alice", "profile"]: │ │ { name: "Alice", food: "pizza" } │ ← 所有 thread 都能读到 │ ["alice", "recommendations"]: │ │ { last: "XX餐厅" } │ ← 跨对话共享 └─────────────────────────────────────────────┘所以:
- 短期记忆存数据库是为了"对话不丢"——服务重启后同一个
thread_id还能继续聊- 长期记忆存数据库是为了"跨对话记住用户"——不管开几个新对话,Agent 都知道你是谁、喜欢什么
两者配合使用,才构成完整的 Agent 记忆体系。
📋 LangGraph 支持的全部存储后端一览
LangGraph 的持久化分为两大类:Checkpointer(短期记忆/状态快照)和 Store(长期记忆/键值存储)。它们支持的后端各有不同:
Checkpointer 后端(用于短期记忆 / 状态持久化):
后端 安装包 说明 内存 @langchain/langgraph(内置)MemorySaver,开发测试用SQLite @langchain/langgraph-checkpoint-sqlite本地文件数据库,单机部署、不想装数据库时的好选择 PostgreSQL @langchain/langgraph-checkpoint-postgres最常用的生产方案 Redis @langchain/langgraph-checkpoint-redis高性能,支持 TTL 自动过期 MongoDB @langchain/langgraph-checkpoint-mongodb文档型数据库方案 AWS DynamoDB langgraph-checkpoint-aws(Python)AWS 生态,支持压缩 + S3 大对象分流 CockroachDB langchain-cockroachdb(Python)分布式 SQL 数据库 Aerospike langgraph-checkpoint-aerospike(Python)超高吞吐的 NoSQL ✅ 所以答案是:支持文件存储! 使用 SQLite Checkpointer 就可以把短期记忆存到本地文件中。SQLite 是一个零配置的嵌入式数据库,数据就存在一个
.sqlite文件里,不需要安装任何数据库服务:typescriptimport { SqliteSaver } from "@langchain/langgraph-checkpoint-sqlite"; const checkpointer = SqliteSaver.fromConnString("./my_checkpoints.sqlite"); const graph = workflow.compile({ checkpointer });适合以下场景:
- 单机部署的 CLI 工具或桌面应用
- 不想安装 PostgreSQL / Redis 等外部数据库
- 需要持久化但对性能要求不高
- 数据量不大、不需要多实例共享
❓ 除了 SQLite,能不能用 JSON 文件存储?
官方没有提供 JSON 文件格式的 Checkpointer。SQLite 已经是最轻量的文件存储方案了——它本身就是单文件、零配置、嵌入式数据库,和"存一个 JSON 文件"的使用体验几乎一样简单,但在并发安全、事务性、查询能力上远优于裸 JSON 文件。
如果你确实想用 JSON 文件(比如需要人工可读的状态快照),可以通过继承
BaseCheckpointSaver自己实现一个:typescriptimport { BaseCheckpointSaver } from "@langchain/langgraph-checkpoint"; import fs from "fs/promises"; import path from "path"; class JsonFileCheckpointer extends BaseCheckpointSaver { private dir: string; constructor(dir: string) { super(); this.dir = dir; } private filePath(threadId: string): string { return path.join(this.dir, `${threadId}.json`); } async getTuple(config) { const threadId = config.configurable?.thread_id; try { const data = await fs.readFile(this.filePath(threadId), "utf-8"); return JSON.parse(data); } catch { return undefined; } } async put(config, checkpoint, metadata) { const threadId = config.configurable?.thread_id; await fs.mkdir(this.dir, { recursive: true }); await fs.writeFile( this.filePath(threadId), JSON.stringify({ config, checkpoint, metadata }, null, 2) ); return config; } // ... 还需要实现 list、putWrites 等方法 }⚠️ 但不推荐在生产中使用——JSON 文件没有事务保护,并发写入会丢数据。SQLite 只需一行代码就解决了这些问题,没有理由退回到裸文件。
方案 文件格式 人工可读 并发安全 事务性 推荐度 SQLite Checkpointer .sqlite二进制❌ 需要工具打开 ✅ 内置锁 ✅ ACID ⭐⭐⭐⭐⭐ 自定义 JSON Checkpointer .json文本✅ 直接查看 ❌ 需自行处理 ❌ 无 ⭐⭐ 💡 人话总结:想用文件存 Checkpointer?直接用 SQLite,别折腾 JSON。
Store 后端(用于长期记忆 / 键值存储):
后端 安装包 说明 内存 @langchain/langgraph(内置)InMemoryStore,开发测试用PostgreSQL @langchain/langgraph-checkpoint-postgresPostgresStore,生产首选,支持向量搜索Redis @langchain/langgraph-checkpoint-redis高性能键值存储 Cassandra @langchain/community分布式 NoSQL Upstash Redis @langchain/communityServerless Redis,适合边缘计算 Vercel KV @langchain/communityVercel 平台原生 KV 存储 本地文件 @langchain/langgraph(内置)LocalFileStore,文件系统存储✅ Store 后端支持文件存储!
LocalFileStore是 LangChain 内置的文件系统存储后端,每个 key-value 对存为磁盘上的一个文件:typescriptimport { LocalFileStore } from "@langchain/langgraph"; const store = new LocalFileStore({ rootPath: "./my_store_data", }); await store.mset([ ["user_123_prefs", Buffer.from(JSON.stringify({ theme: "dark", lang: "zh" }))], ["user_123_name", Buffer.from("Alice")], ]); const values = await store.mget(["user_123_prefs"]); console.log(JSON.parse(values[0].toString())); // { theme: "dark", lang: "zh" }
LocalFileStore的特点:
- 每个 key 对应磁盘上的一个文件(文件名 = key)
- 值以
Buffer(字节)形式存储,JSON 需要自己序列化/反序列化- 适合开发调试、本地 CLI 工具
- ⚠️ 注意:
LocalFileStore实现的是底层的BaseStore(key-value 字节存储),和InMemoryStore/PostgresStore的高级 API(put/get/search+ 命名空间 + 向量搜索)不在同一个抽象层级。它更适合作为缓存或简单 KV 存储使用,不直接支持命名空间和语义搜索
Store 类型 命名空间 向量搜索 持久化 适用场景 InMemoryStore✅ ✅ ❌ 开发测试 PostgresStore✅ ✅ ✅ 生产环境 LocalFileStore❌ ❌ ✅ 本地缓存、简单 KV 💡 人话总结:
- Checkpointer 文件存储 → 用 SQLite(官方方案,功能完整)
- Store 文件存储 → 用 LocalFileStore(内置,但功能较基础)
- 想要命名空间 + 向量搜索 + 文件持久化?→ 目前没有开箱即用的方案,建议用 PostgreSQL(Docker 一行命令就能跑),或者继承
BaseStore自己实现💡 如何选择?
- 刚开始开发 →
InMemoryStore+MemorySaver(零配置)- 生产环境(通用) →
PostgresStore+PostgresSaver(功能最完整,支持向量搜索)- 需要高性能/TTL → Redis 系列
- AWS 技术栈 → DynamoDB
- Serverless/边缘部署 → Upstash Redis 或 Vercel KV
命名空间组织
命名空间用于将相关数据组织在一起,类似于文件系统中的文件夹结构。
typescript
const userId = "my-user";
const applicationContext = "chitchat";
const namespace = [userId, applicationContext];
// 存储数据
await store.put(
namespace,
"a-memory",
{
rules: [
"User likes short, direct language",
"User only speaks English & TypeScript",
],
"my-key": "my-value",
}
);
// 通过 ID 获取记忆
const item = await store.get(namespace, "a-memory");
// 在命名空间内搜索记忆,支持内容过滤和向量相似度排序
const items = await store.search(
namespace,
{
filter: { "my-key": "my-value" },
query: "language preferences"
}
);在工具中读取长期记忆
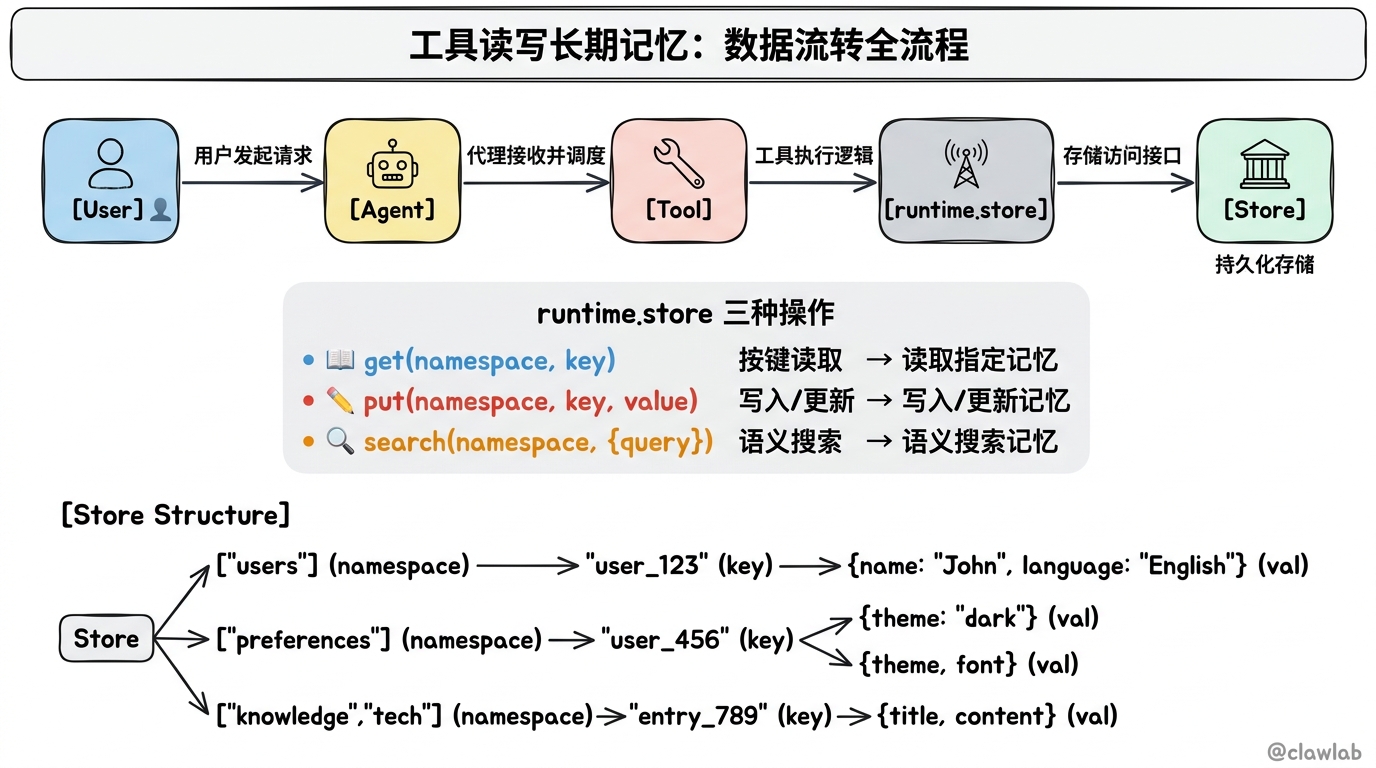
工具可以通过 runtime.store 访问长期记忆,读取存储在 Store 中的数据。
typescript
import * as z from "zod";
import { createAgent, tool, type ToolRuntime } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
// 创建存储
const store = new InMemoryStore();
// 定义上下文模式
const contextSchema = z.object({
userId: z.string(),
});
// 预先写入一些示例数据
await store.put(
["users"], // 命名空间:用户数据
"user_123", // 键:用户 ID
{
name: "John Smith",
language: "English",
}
);
// 创建读取用户信息的工具
const getUserInfo = tool(
async (_, runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>) => {
// 从上下文获取用户 ID
const userId = runtime.context.userId;
if (!userId) {
throw new Error("userId is required");
}
// 从存储中检索数据
const userInfo = await runtime.store.get(["users"], userId);
return userInfo?.value ? JSON.stringify(userInfo.value) : "Unknown user";
},
{
name: "getUserInfo",
description: "Look up user info by userId from the store.",
schema: z.object({}),
}
);
// 创建代理
const agent = createAgent({
model: "gpt-4.1-mini",
tools: [getUserInfo],
contextSchema,
store, // 将存储传递给代理
});
// 运行代理
const result = await agent.invoke(
{ messages: [{ role: "user", content: "look up user information" }] },
{ context: { userId: "user_123" } }
);
console.log(result.messages.at(-1)?.content);
// 输出:
// User Information:
// - Name: John Smith
// - Language: English在工具中写入长期记忆
工具也可以将数据写入长期记忆,用于更新用户信息或保存新的数据。
typescript
import * as z from "zod";
import { tool, createAgent, type ToolRuntime } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
// 创建存储
const store = new InMemoryStore();
// 定义上下文模式
const contextSchema = z.object({
userId: z.string(),
});
// 定义用户信息模式
const UserInfo = z.object({
name: z.string(),
});
// 创建保存用户信息的工具
const saveUserInfo = tool(
async (
userInfo: z.infer<typeof UserInfo>,
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
// 从上下文获取用户 ID
const userId = runtime.context.userId;
if (!userId) {
throw new Error("userId is required");
}
// 将数据存储到存储中(命名空间, 键, 数据)
await runtime.store.put(["users"], userId, userInfo);
return "Successfully saved user info.";
},
{
name: "save_user_info",
description: "Save user info",
schema: UserInfo,
}
);
// 创建代理
const agent = createAgent({
model: "gpt-4.1-mini",
tools: [saveUserInfo],
contextSchema,
store,
});
// 运行代理
await agent.invoke(
{ messages: [{ role: "user", content: "My name is John Smith" }] },
{ context: { userId: "user_123" } }
);
// 直接访问存储获取值
const result = await store.get(["users"], "user_123");
console.log(result?.value); // 输出: { name: "John Smith" }业务场景
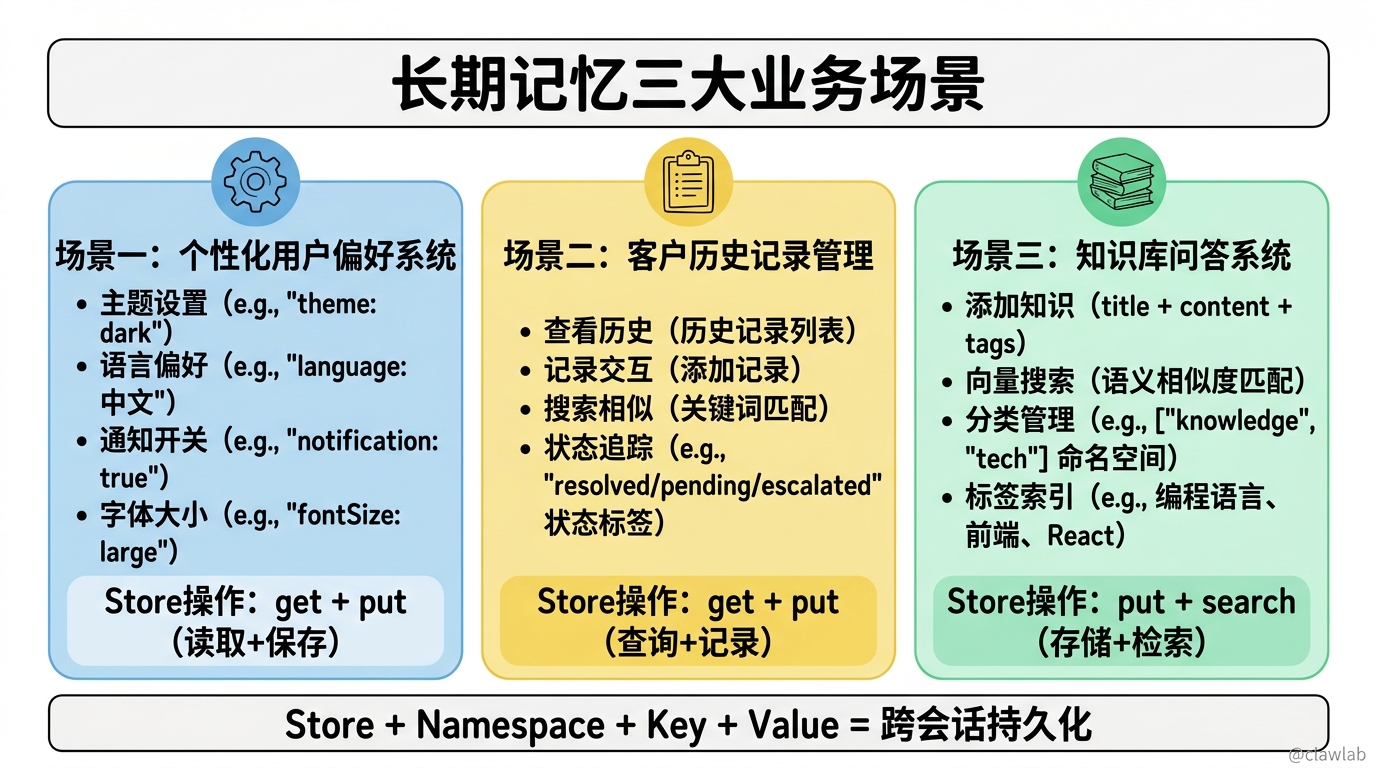
场景一:个性化用户偏好系统
问题:如何构建一个能够记住用户偏好并在下次会话中自动应用的 AI 助手?
解决方案:使用长期记忆存储用户偏好
typescript
import * as z from "zod";
import { tool, createAgent, type ToolRuntime } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
// 创建存储
const store = new InMemoryStore();
// 定义上下文模式
const contextSchema = z.object({
userId: z.string(),
});
// 定义用户偏好模式
const UserPreferences = z.object({
theme: z.enum(["light", "dark"]).optional(),
language: z.string().optional(),
notificationEnabled: z.boolean().optional(),
fontSize: z.enum(["small", "medium", "large"]).optional(),
});
// 获取用户偏好工具
const getPreferences = tool(
async (_, runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>) => {
const userId = runtime.context.userId;
if (!userId) {
throw new Error("userId is required");
}
const preferences = await runtime.store.get(["preferences"], userId);
if (!preferences?.value) {
return "用户暂无保存的偏好设置。";
}
const prefs = preferences.value;
return `用户偏好设置:
- 主题:${prefs.theme || "未设置"}
- 语言:${prefs.language || "未设置"}
- 通知:${prefs.notificationEnabled !== undefined ? (prefs.notificationEnabled ? "开启" : "关闭") : "未设置"}
- 字体大小:${prefs.fontSize || "未设置"}`;
},
{
name: "get_preferences",
description: "获取用户的偏好设置",
schema: z.object({}),
}
);
// 保存用户偏好工具
const savePreferences = tool(
async (
newPrefs: z.infer<typeof UserPreferences>,
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
const userId = runtime.context.userId;
if (!userId) {
throw new Error("userId is required");
}
// 获取现有偏好
const existing = await runtime.store.get(["preferences"], userId);
const existingPrefs = existing?.value || {};
// 合并新旧偏好
const mergedPrefs = { ...existingPrefs, ...newPrefs };
// 保存更新后的偏好
await runtime.store.put(["preferences"], userId, mergedPrefs);
return "偏好设置已保存。";
},
{
name: "save_preferences",
description: "保存用户的偏好设置",
schema: UserPreferences,
}
);
// 创建个性化助手
const preferenceAgent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [getPreferences, savePreferences],
contextSchema,
store,
systemPrompt: `你是一个个性化设置助手,能够帮助用户管理他们的偏好设置。
你可以查看用户的当前设置,也可以根据用户的要求更新设置。
请用友好的语气与用户交流。`,
});
// 测试场景
async function testPreferenceSystem() {
const config = { context: { userId: "user_456" } };
// 第一次会话:用户设置偏好
console.log("=== 第一次会话 ===");
const response1 = await preferenceAgent.invoke(
{ messages: [{ role: "user", content: "我想把主题设置为深色模式,语言设置为中文。" }] },
config
);
console.log(response1.messages.at(-1)?.content);
// 第二次会话:用户查看偏好
console.log("\n=== 第二次会话 ===");
const response2 = await preferenceAgent.invoke(
{ messages: [{ role: "user", content: "我的偏好设置是什么?" }] },
config
);
console.log(response2.messages.at(-1)?.content);
// 第三次会话:用户更新部分偏好
console.log("\n=== 第三次会话 ===");
const response3 = await preferenceAgent.invoke(
{ messages: [{ role: "user", content: "把字体大小改成大号,开启通知。" }] },
config
);
console.log(response3.messages.at(-1)?.content);
}
testPreferenceSystem();场景二:客户历史记录管理
问题:如何构建一个能够记住客户历史交互和问题的客服系统?
解决方案:使用长期记忆存储客户交互历史
typescript
import * as z from "zod";
import { tool, createAgent, type ToolRuntime } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
// 创建存储
const store = new InMemoryStore();
// 定义上下文模式
const contextSchema = z.object({
customerId: z.string(),
});
// 定义交互记录模式
const InteractionRecord = z.object({
date: z.string(),
issue: z.string(),
resolution: z.string(),
status: z.enum(["resolved", "pending", "escalated"]),
});
// 获取客户历史工具
const getCustomerHistory = tool(
async (_, runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>) => {
const customerId = runtime.context.customerId;
if (!customerId) {
throw new Error("customerId is required");
}
const history = await runtime.store.get(["customer_history"], customerId);
if (!history?.value || (history.value as any[]).length === 0) {
return "该客户暂无历史记录。";
}
const records = history.value as z.infer<typeof InteractionRecord>[];
return `客户历史记录(共 ${records.length} 条):\n` +
records.map((r, i) =>
`${i + 1}. [${r.date}] ${r.issue}\n 解决方案:${r.resolution}\n 状态:${r.status}`
).join("\n\n");
},
{
name: "get_customer_history",
description: "获取客户的历史交互记录",
schema: z.object({}),
}
);
// 添加交互记录工具
const addInteraction = tool(
async (
record: z.infer<typeof InteractionRecord>,
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
const customerId = runtime.context.customerId;
if (!customerId) {
throw new Error("customerId is required");
}
// 获取现有历史
const existing = await runtime.store.get(["customer_history"], customerId);
const existingRecords = (existing?.value as z.infer<typeof InteractionRecord>[] | undefined) || [];
// 添加新记录
const updatedRecords = [...existingRecords, record];
// 保存更新后的历史
await runtime.store.put(["customer_history"], customerId, updatedRecords);
return "交互记录已添加。";
},
{
name: "add_interaction",
description: "添加新的客户交互记录",
schema: InteractionRecord,
}
);
// 搜索相似问题工具
const searchSimilarIssues = tool(
async (
{ query }: { query: string },
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
const customerId = runtime.context.customerId;
if (!customerId) {
throw new Error("customerId is required");
}
const history = await runtime.store.get(["customer_history"], customerId);
if (!history?.value || (history.value as any[]).length === 0) {
return "未找到相似问题。";
}
const records = history.value as z.infer<typeof InteractionRecord>[];
// 简单的关键词匹配(实际应用中可以使用向量搜索)
const similarIssues = records.filter(r =>
r.issue.toLowerCase().includes(query.toLowerCase()) ||
r.resolution.toLowerCase().includes(query.toLowerCase())
);
if (similarIssues.length === 0) {
return "未找到相似问题。";
}
return `找到 ${similarIssues.length} 个相似问题:\n` +
similarIssues.map((r, i) =>
`${i + 1}. ${r.issue}\n 解决方案:${r.resolution}`
).join("\n\n");
},
{
name: "search_similar_issues",
description: "搜索客户历史中的相似问题",
schema: z.object({
query: z.string().describe("搜索关键词"),
}),
}
);
// 创建客服助手
const supportAgent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [getCustomerHistory, addInteraction, searchSimilarIssues],
contextSchema,
store,
systemPrompt: `你是一个专业的客服助手,能够查看和管理客户的历史交互记录。
你可以:
1. 查看客户的历史问题和解决方案
2. 记录新的交互内容
3. 搜索相似的历史问题
请根据客户的历史记录提供更加个性化的服务。`,
});
// 测试场景
async function testSupportSystem() {
const config = { context: { customerId: "cust_789" } };
// 预先添加一些历史记录
await store.put(["customer_history"], "cust_789", [
{
date: "2024-01-15",
issue: "无法登录账户",
resolution: "重置密码后解决",
status: "resolved"
},
{
date: "2024-02-10",
issue: "订单支付失败",
resolution: "更换支付方式后成功",
status: "resolved"
},
{
date: "2024-03-05",
issue: "收到损坏商品",
resolution: "安排退换货处理",
status: "resolved"
}
]);
// 客服查看历史
console.log("=== 查看客户历史 ===");
const response1 = await supportAgent.invoke(
{ messages: [{ role: "user", content: "请查看这位客户的历史记录。" }] },
config
);
console.log(response1.messages.at(-1)?.content);
// 客服搜索相似问题
console.log("\n=== 搜索相似问题 ===");
const response2 = await supportAgent.invoke(
{ messages: [{ role: "user", content: "客户说登录有问题,有没有类似的历史记录?" }] },
config
);
console.log(response2.messages.at(-1)?.content);
// 客服添加新记录
console.log("\n=== 添加新记录 ===");
const response3 = await supportAgent.invoke(
{ messages: [{ role: "user", content: "客户今天反映优惠券无法使用,我已经帮他手动调整了价格。请记录一下。" }] },
config
);
console.log(response3.messages.at(-1)?.content);
}
testSupportSystem();场景三:知识库问答系统
问题:如何构建一个能够存储和检索知识的问答系统?
解决方案:使用带向量搜索的长期记忆存储知识条目
typescript
import * as z from "zod";
import { tool, createAgent, type ToolRuntime } from "langchain";
import { InMemoryStore } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
// 模拟嵌入函数(实际应用中使用真正的嵌入模型)
const embed = (texts: string[]): number[][] => {
// 简化的嵌入函数,实际应用中使用 OpenAI embeddings 等
return texts.map(text => {
// 基于文本长度和字符的简单哈希
const hash = text.split('').reduce((acc, char) => acc + char.charCodeAt(0), 0);
return [hash % 100, (hash * 2) % 100];
});
};
// 创建带向量搜索能力的存储
const store = new InMemoryStore({
index: { embed, dims: 2 }
});
// 定义上下文模式
const contextSchema = z.object({
category: z.string().optional(),
});
// 定义知识条目模式
const KnowledgeEntry = z.object({
title: z.string(),
content: z.string(),
tags: z.array(z.string()),
});
// 添加知识条目工具
const addKnowledge = tool(
async (
entry: z.infer<typeof KnowledgeEntry>,
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
const category = runtime.context.category || "general";
const entryId = `entry_${Date.now()}`;
await runtime.store.put(
["knowledge", category],
entryId,
{
...entry,
createdAt: new Date().toISOString(),
}
);
return `知识条目 "${entry.title}" 已添加到 ${category} 类别。`;
},
{
name: "add_knowledge",
description: "添加新的知识条目到知识库",
schema: KnowledgeEntry,
}
);
// 搜索知识工具
const searchKnowledge = tool(
async (
{ query, category }: { query: string; category?: string },
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
const searchCategory = category || runtime.context.category || "general";
try {
const results = await runtime.store.search(
["knowledge", searchCategory],
{ query }
);
if (!results || results.length === 0) {
return `在 ${searchCategory} 类别中未找到与 "${query}" 相关的知识。`;
}
return `找到 ${results.length} 条相关知识:\n\n` +
results.map((r, i) => {
const entry = r.value as z.infer<typeof KnowledgeEntry> & { createdAt: string };
return `${i + 1}. **${entry.title}**\n ${entry.content}\n 标签:${entry.tags.join(", ")}`;
}).join("\n\n");
} catch (error) {
return `搜索过程中出现错误:${error}`;
}
},
{
name: "search_knowledge",
description: "在知识库中搜索相关知识",
schema: z.object({
query: z.string().describe("搜索关键词"),
category: z.string().optional().describe("知识类别"),
}),
}
);
// 获取所有知识工具
const listKnowledge = tool(
async (
{ category }: { category?: string },
runtime: ToolRuntime<unknown, z.infer<typeof contextSchema>>
) => {
const listCategory = category || runtime.context.category || "general";
try {
const results = await runtime.store.search(
["knowledge", listCategory],
{ query: "" } // 空查询获取所有
);
if (!results || results.length === 0) {
return `${listCategory} 类别中暂无知识条目。`;
}
return `${listCategory} 类别共有 ${results.length} 条知识:\n\n` +
results.map((r, i) => {
const entry = r.value as z.infer<typeof KnowledgeEntry>;
return `${i + 1}. ${entry.title}`;
}).join("\n");
} catch (error) {
return `获取知识列表时出现错误:${error}`;
}
},
{
name: "list_knowledge",
description: "列出知识库中的所有知识条目",
schema: z.object({
category: z.string().optional().describe("知识类别"),
}),
}
);
// 创建知识库助手
const knowledgeAgent = createAgent({
model: new ChatOpenAI({ model: "gpt-4.1" }),
tools: [addKnowledge, searchKnowledge, listKnowledge],
contextSchema,
store,
systemPrompt: `你是一个知识库管理助手,能够帮助用户:
1. 添加新的知识条目
2. 搜索相关知识
3. 列出知识库中的内容
请根据用户的需求提供准确、有帮助的回答。`,
});
// 测试场景
async function testKnowledgeSystem() {
const config = { context: { category: "tech" } };
// 添加知识条目
console.log("=== 添加知识 ===");
const response1 = await knowledgeAgent.invoke(
{ messages: [{ role: "user", content: "添加一条关于 TypeScript 的知识:标题是 'TypeScript 简介',内容是 'TypeScript 是 JavaScript 的超集,添加了静态类型系统',标签是 ['编程语言', 'JavaScript', 'TypeScript']" }] },
config
);
console.log(response1.messages.at(-1)?.content);
// 添加另一条知识
console.log("\n=== 添加更多知识 ===");
const response2 = await knowledgeAgent.invoke(
{ messages: [{ role: "user", content: "再添加一条:标题 'React 框架',内容 'React 是一个用于构建用户界面的 JavaScript 库',标签 ['前端', 'React', 'UI']" }] },
config
);
console.log(response2.messages.at(-1)?.content);
// 搜索知识
console.log("\n=== 搜索知识 ===");
const response3 = await knowledgeAgent.invoke(
{ messages: [{ role: "user", content: "搜索关于 JavaScript 的知识" }] },
config
);
console.log(response3.messages.at(-1)?.content);
// 列出所有知识
console.log("\n=== 列出知识 ===");
const response4 = await knowledgeAgent.invoke(
{ messages: [{ role: "user", content: "列出所有知识" }] },
config
);
console.log(response4.messages.at(-1)?.content);
}
testKnowledgeSystem();技术要点
1. Store 选择
- 开发环境:使用
InMemoryStore,数据存储在内存中 - 生产环境:使用数据库支持的存储,如 PostgreSQL、Redis 等
- 向量搜索:如果需要语义搜索,配置嵌入函数
2. 命名空间设计
- 层级结构:使用数组形式的命名空间,支持多层级组织
- 常见模式:
[userId, category]、[orgId, userId, type] - 可搜索性:设计合理的命名空间结构,便于跨命名空间搜索
3. 数据模式
- 类型安全:使用 Zod 定义数据模式,确保数据结构一致
- 版本管理:考虑数据结构的演进和向后兼容
- 索引字段:为常用查询字段添加索引
4. 安全性考虑
- 访问控制:确保用户只能访问自己的数据
- 敏感数据:避免存储敏感信息或进行适当加密
- 数据验证:在存储前验证数据的合法性
5. 性能优化
- 批量操作:尽量使用批量读写减少 I/O 次数
- 缓存策略:对频繁访问的数据实施缓存
- 分页查询:对大量数据实施分页查询
总结
长期记忆是 LangChain 中实现跨会话持久化的关键组件,它让 AI 代理能够像真正的"助手"一样记住用户的偏好、历史和重要信息。通过合理设计命名空间结构和数据模式,开发者可以构建出更加智能、个性化的 AI 应用。
核心优势
- 跨会话持久:信息不会因会话结束而丢失
- 灵活组织:通过命名空间实现层级化数据组织
- 强大搜索:支持内容过滤和向量相似度搜索
- 无缝集成:通过工具轻松读写长期记忆
应用前景
长期记忆的应用前景非常广阔,从个性化推荐、客户关系管理到知识库系统,几乎所有需要持久化用户数据的 AI 应用都可以受益于长期记忆。随着存储技术和向量搜索能力的不断提升,长期记忆将成为构建真正智能 AI 助手的核心基础设施。
通过掌握长期记忆的使用技巧,开发者可以构建出更加智能、个性化、有"记忆"的 AI 应用,为用户提供更加贴心和高效的服务体验。