
主题
23. 项目实战:文档摘要工作流
项目简介
本项目将从零构建一个智能文档摘要系统,实现:
- 📄 分块处理:将长文档拆分为可处理的片段
- ⚡ 并行摘要:使用 Send API 并行处理多个片段
- 📊 层级汇总:将片段摘要合并为最终摘要
- 🔄 质量评估:评估摘要质量并循环优化
难度等级: ⭐⭐⭐⭐
涉及知识点: 编排者-工作者模式 + 评估者-优化者模式 + 子图 + Send API
🎯 学习目标
完成本项目后,你将掌握:
- 如何使用编排者-工作者模式分解复杂任务
- 如何使用评估者-优化者模式迭代改进结果
- 如何使用 Send API 动态生成并行工作节点
- 如何实现质量评估和反馈循环
- 如何处理长文档的分块策略
项目架构
长文档 → 编排者节点
│
├→ 文档分块
│
├→ [Send API 动态生成] 摘要工作节点
│ ├→ Worker 1: 摘要 Chunk 1
│ ├→ Worker 2: 摘要 Chunk 2
│ └→ Worker N: 摘要 Chunk N
│
├→ 汇总节点(合并摘要)
│
└→ 评估节点
├→ 质量通过 → 输出最终摘要
└→ 质量不足 → 反馈优化(循环)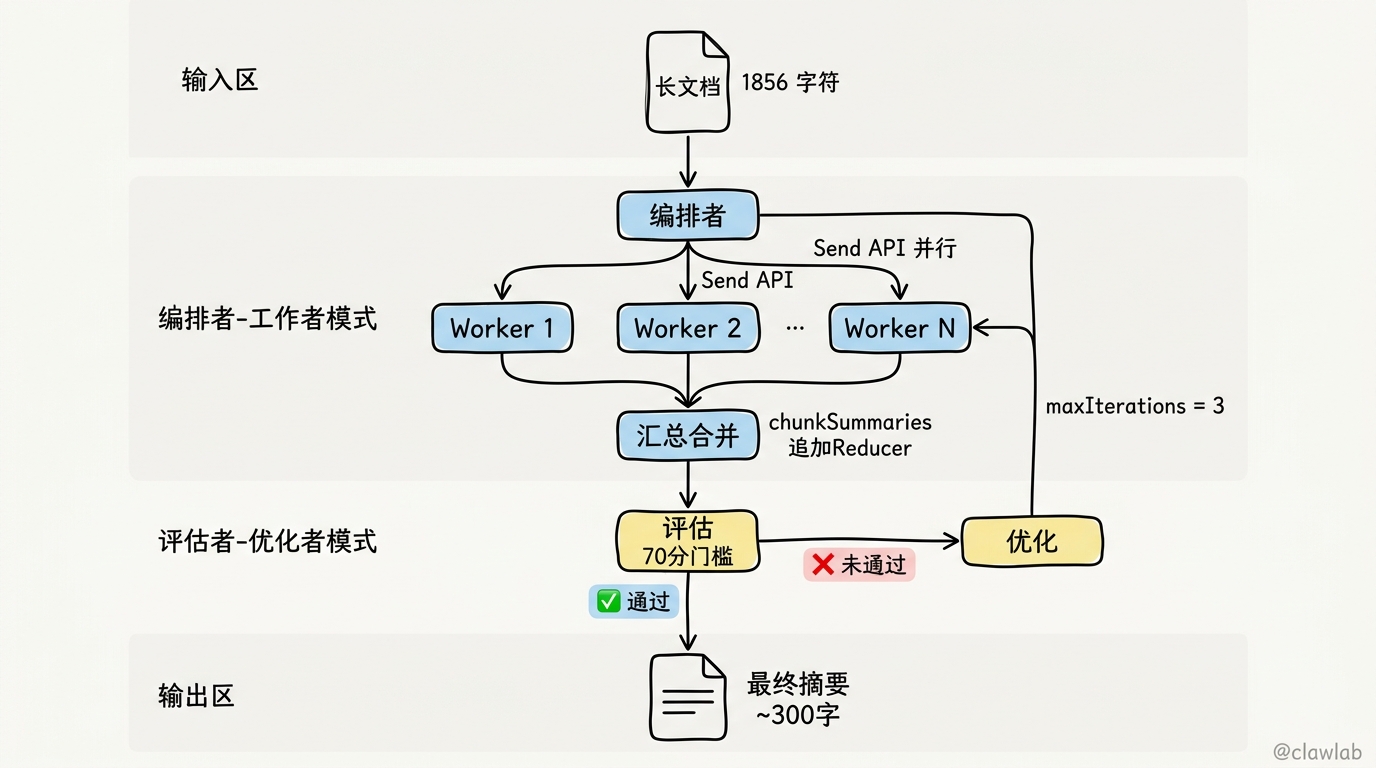
项目结构
plaintext
doc-summarizer/
├── src/
│ ├── state.ts # 状态定义
│ ├── chunker.ts # 文档分块工具
│ ├── nodes.ts # 节点函数
│ ├── graph.ts # 图构建
│ └── index.ts # 入口文件
├── package.json
├── tsconfig.json
└── .env第一步:项目初始化
package.json
json
{
"name": "doc-summarizer",
"version": "1.0.0",
"type": "module",
"scripts": {
"build": "tsc",
"start": "node dist/index.js",
"dev": "tsx src/index.ts"
},
"dependencies": {
"@langchain/langgraph": "^0.2.0",
"@langchain/openai": "^0.3.0",
"@langchain/core": "^0.3.0"
},
"devDependencies": {
"typescript": "^5.0.0",
"@types/node": "^20.0.0",
"tsx": "^4.0.0"
}
}.env
bash
OPENAI_API_KEY=sk-xxx...第二步:状态定义
src/state.ts
typescript
import { Annotation } from "@langchain/langgraph";
export interface DocumentChunk {
id: number;
content: string;
startIndex: number;
endIndex: number;
}
export interface ChunkSummary {
chunkId: number;
summary: string;
keyPoints: string[];
wordCount: number;
}
export interface QualityEvaluation {
score: number;
passed: boolean;
feedback: string;
suggestions: string[];
}
export const SummarizerState = Annotation.Root({
document: Annotation<string>({
reducer: (_, update) => update,
default: () => "",
}),
chunks: Annotation<DocumentChunk[]>({
reducer: (_, update) => update,
default: () => [],
}),
chunkSummaries: Annotation<ChunkSummary[]>({
reducer: (curr, update) => [...curr, ...update],
default: () => [],
}),
mergedSummary: Annotation<string>({
reducer: (_, update) => update,
default: () => "",
}),
evaluation: Annotation<QualityEvaluation | null>({
reducer: (_, update) => update,
default: () => null,
}),
finalSummary: Annotation<string>({
reducer: (_, update) => update,
default: () => "",
}),
iterationCount: Annotation<number>({
reducer: (_, update) => update,
default: () => 0,
}),
maxIterations: Annotation<number>({
reducer: (_, update) => update,
default: () => 3,
}),
currentChunk: Annotation<DocumentChunk | null>({
reducer: (_, update) => update,
default: () => null,
}),
targetLength: Annotation<number>({
reducer: (_, update) => update,
default: () => 500,
}),
});
export type SummarizerStateType = typeof SummarizerState.State;💡 人话解读:
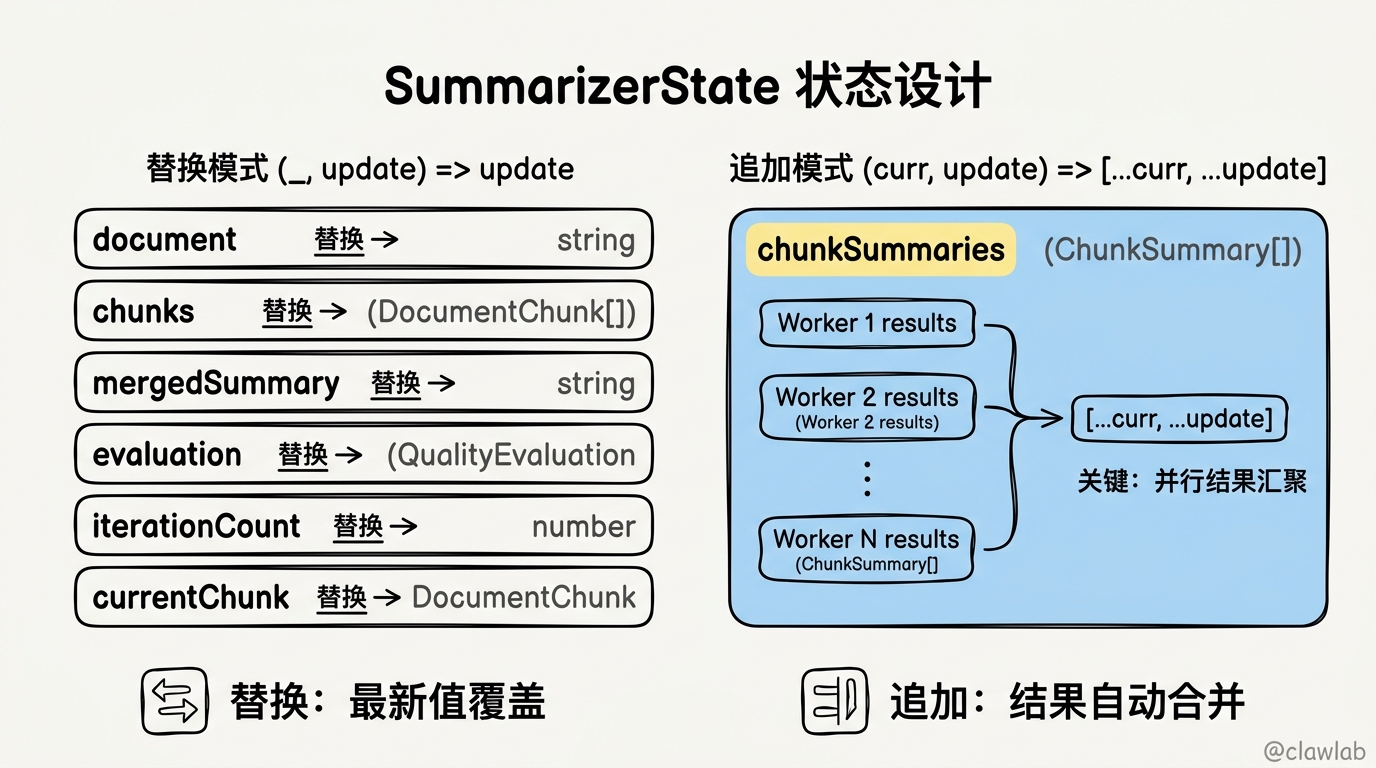
| 状态字段 | 作用 | Reducer 策略 |
|---|---|---|
document | 原始文档内容 | 替换模式 |
chunks | 文档分块列表 | 替换模式 |
chunkSummaries | 每个分块的摘要(并行产出) | 追加模式 |
mergedSummary | 合并后的摘要 | 替换模式 |
evaluation | 质量评估结果 | 替换模式 |
finalSummary | 最终输出的摘要 | 替换模式 |
iterationCount | 当前迭代次数 | 替换模式 |
currentChunk | 当前处理的分块(用于并行) | 替换模式 |
第三步:文档分块工具
src/chunker.ts
typescript
import { DocumentChunk } from "./state.js";
export interface ChunkOptions {
chunkSize: number;
overlap: number;
}
export function chunkDocument(
document: string,
options: ChunkOptions = { chunkSize: 2000, overlap: 200 }
): DocumentChunk[] {
const { chunkSize, overlap } = options;
const chunks: DocumentChunk[] = [];
const paragraphs = document.split(/\n\n+/);
let currentChunk = "";
let chunkStart = 0;
let charIndex = 0;
for (const paragraph of paragraphs) {
if (currentChunk.length + paragraph.length > chunkSize && currentChunk.length > 0) {
chunks.push({
id: chunks.length,
content: currentChunk.trim(),
startIndex: chunkStart,
endIndex: charIndex,
});
const overlapText = currentChunk.slice(-overlap);
currentChunk = overlapText + "\n\n" + paragraph;
chunkStart = charIndex - overlap;
} else {
if (currentChunk.length > 0) {
currentChunk += "\n\n";
}
currentChunk += paragraph;
}
charIndex += paragraph.length + 2;
}
if (currentChunk.trim().length > 0) {
chunks.push({
id: chunks.length,
content: currentChunk.trim(),
startIndex: chunkStart,
endIndex: charIndex,
});
}
return chunks;
}
export function estimateTokens(text: string): number {
return Math.ceil(text.length / 4);
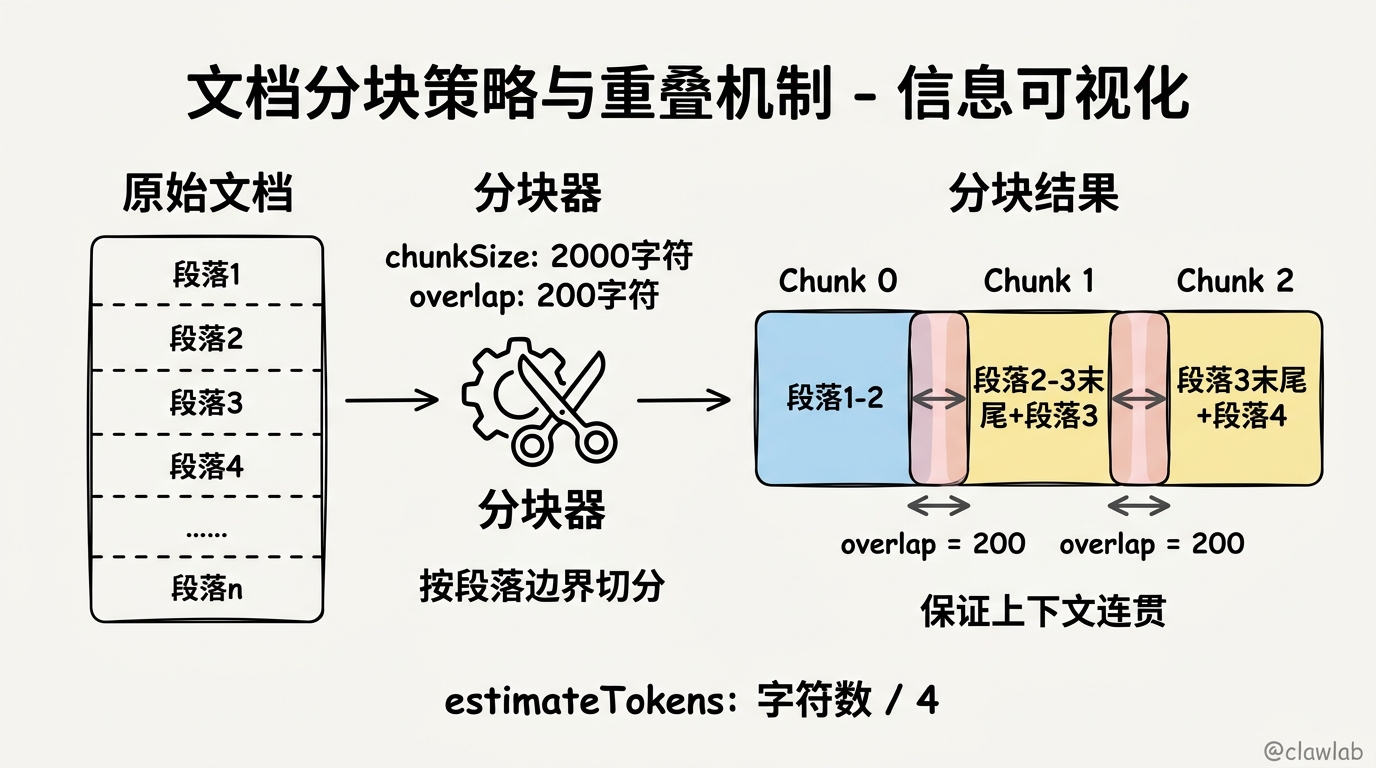
}💡 分块策略说明:
原文档: "段落1...\n\n段落2...\n\n段落3...\n\n段落4..."
│
▼
┌─────────┐
│ 分块器 │ ← chunkSize: 2000, overlap: 200
└────┬────┘
│
┌────┴────┬────────────┐
▼ ▼ ▼
┌───────┐ ┌───────┐ ┌───────┐
│Chunk 0│ │Chunk 1│ │Chunk N│
│段落1-2│ │段落2-3│ │段落N │
└───────┘ └───────┘ └───────┘
└─overlap─┘| 参数 | 默认值 | 说明 |
|---|---|---|
| chunkSize | 2000字符 | 每个分块的最大长度 |
| overlap | 200字符 | 相邻分块的重叠部分,保证上下文连贯 |
第四步:节点函数
src/nodes.ts
typescript
import { Send } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
import { HumanMessage, SystemMessage } from "@langchain/core/messages";
import { SummarizerStateType, ChunkSummary, QualityEvaluation } from "./state.js";
import { chunkDocument } from "./chunker.js";
const llm = new ChatOpenAI({ model: "gpt-4o-mini", temperature: 0.3 });
const evaluatorLlm = new ChatOpenAI({ model: "gpt-4o-mini", temperature: 0 });
export async function orchestratorNode(state: SummarizerStateType) {
console.log("\n🎯 编排者节点: 分析文档并分块");
const chunks = chunkDocument(state.document, {
chunkSize: 2000,
overlap: 200,
});
console.log(` 📄 文档长度: ${state.document.length} 字符`);
console.log(` 📦 分块数量: ${chunks.length}`);
return {
chunks,
iterationCount: state.iterationCount + 1,
};
}
export function fanOutSummaryNode(state: SummarizerStateType): Send[] {
console.log(`\n📤 分发 ${state.chunks.length} 个摘要任务`);
return state.chunks.map(chunk => {
console.log(` → Chunk ${chunk.id} (${chunk.content.length} 字符)`);
return new Send("summarizeChunk", { currentChunk: chunk });
});
}
export async function summarizeChunkNode(state: SummarizerStateType): Promise<{
chunkSummaries: ChunkSummary[];
}> {
const chunk = state.currentChunk;
if (!chunk) {
return { chunkSummaries: [] };
}
console.log(` 🔄 [Chunk ${chunk.id}] 生成摘要...`);
const systemPrompt = `你是一个专业的文档摘要专家。请对以下文档片段生成简洁的摘要。
要求:
1. 保留关键信息和核心观点
2. 摘要长度控制在原文的 20% 以内
3. 提取 3-5 个关键要点
4. 使用客观、专业的语言
输出格式(JSON):
{
"summary": "摘要内容",
"keyPoints": ["要点1", "要点2", "要点3"]
}`;
try {
const response = await llm.invoke([
new SystemMessage(systemPrompt),
new HumanMessage(`请摘要以下内容:\n\n${chunk.content}`),
]);
const content = response.content as string;
const jsonMatch = content.match(/\{[\s\S]*\}/);
if (jsonMatch) {
const parsed = JSON.parse(jsonMatch[0]);
console.log(` ✅ [Chunk ${chunk.id}] 完成`);
return {
chunkSummaries: [{
chunkId: chunk.id,
summary: parsed.summary,
keyPoints: parsed.keyPoints || [],
wordCount: parsed.summary.length,
}],
};
}
} catch (error) {
console.log(` ⚠️ [Chunk ${chunk.id}] 解析失败,使用原始响应`);
}
const fallbackResponse = await llm.invoke([
new SystemMessage("请用 100 字以内总结以下内容的核心要点:"),
new HumanMessage(chunk.content),
]);
return {
chunkSummaries: [{
chunkId: chunk.id,
summary: fallbackResponse.content as string,
keyPoints: [],
wordCount: (fallbackResponse.content as string).length,
}],
};
}
export async function mergeNode(state: SummarizerStateType) {
console.log("\n📥 合并节点: 汇总所有片段摘要");
const sortedSummaries = [...state.chunkSummaries].sort((a, b) => a.chunkId - b.chunkId);
const allSummaries = sortedSummaries.map(s => s.summary).join("\n\n");
const allKeyPoints = sortedSummaries.flatMap(s => s.keyPoints);
const systemPrompt = `你是一个专业的文档摘要专家。请将以下多个片段摘要合并为一个连贯、完整的最终摘要。
要求:
1. 整合所有片段的核心内容
2. 去除重复信息
3. 保持逻辑连贯性
4. 最终摘要长度约 ${state.targetLength} 字
5. 确保摘要完整覆盖原文主要内容
片段摘要:
${allSummaries}
关键要点汇总:
${allKeyPoints.map((p, i) => `${i + 1}. ${p}`).join("\n")}`;
const response = await llm.invoke([
new SystemMessage(systemPrompt),
new HumanMessage("请生成最终合并摘要:"),
]);
console.log(` 📝 生成合并摘要 (${(response.content as string).length} 字符)`);
return {
mergedSummary: response.content as string,
};
}
export async function evaluatorNode(state: SummarizerStateType): Promise<{
evaluation: QualityEvaluation;
}> {
console.log("\n🔍 评估节点: 评估摘要质量");
const systemPrompt = `你是一个摘要质量评估专家。请评估以下摘要的质量。
评估标准:
1. 完整性(0-25分):是否覆盖原文主要内容
2. 准确性(0-25分):信息是否准确无误
3. 连贯性(0-25分):逻辑是否清晰连贯
4. 简洁性(0-25分):是否简洁不冗余
总分 70 分以上为通过。
请以 JSON 格式输出:
{
"score": 总分数,
"passed": true/false,
"feedback": "整体评价",
"suggestions": ["改进建议1", "改进建议2"]
}`;
const response = await evaluatorLlm.invoke([
new SystemMessage(systemPrompt),
new HumanMessage(`原文片段数: ${state.chunks.length}
目标长度: ${state.targetLength} 字
当前摘要长度: ${state.mergedSummary.length} 字
当前迭代: ${state.iterationCount}/${state.maxIterations}
摘要内容:
${state.mergedSummary}`),
]);
try {
const content = response.content as string;
const jsonMatch = content.match(/\{[\s\S]*\}/);
if (jsonMatch) {
const evaluation = JSON.parse(jsonMatch[0]) as QualityEvaluation;
console.log(` 📊 评分: ${evaluation.score}/100`);
console.log(` ${evaluation.passed ? "✅ 通过" : "❌ 未通过"}: ${evaluation.feedback}`);
return { evaluation };
}
} catch (error) {
console.log(" ⚠️ 评估解析失败,默认通过");
}
return {
evaluation: {
score: 75,
passed: true,
feedback: "默认通过",
suggestions: [],
},
};
}
export async function optimizerNode(state: SummarizerStateType) {
console.log("\n🔧 优化节点: 根据反馈改进摘要");
const suggestions = state.evaluation?.suggestions || [];
const systemPrompt = `你是一个摘要优化专家。请根据以下反馈改进摘要。
当前摘要:
${state.mergedSummary}
评估反馈:${state.evaluation?.feedback}
改进建议:
${suggestions.map((s, i) => `${i + 1}. ${s}`).join("\n")}
目标长度: ${state.targetLength} 字
请输出改进后的摘要:`;
const response = await llm.invoke([
new SystemMessage(systemPrompt),
new HumanMessage("请生成改进后的摘要:"),
]);
console.log(` 📝 优化后摘要 (${(response.content as string).length} 字符)`);
return {
mergedSummary: response.content as string,
chunkSummaries: [],
};
}
export function finalizeNode(state: SummarizerStateType) {
console.log("\n✅ 完成节点: 输出最终摘要");
return {
finalSummary: state.mergedSummary,
};
}
export function routeAfterEvaluation(state: SummarizerStateType): string {
if (state.evaluation?.passed) {
console.log(" → 质量通过,输出最终结果");
return "finalize";
}
if (state.iterationCount >= state.maxIterations) {
console.log(" → 达到最大迭代次数,强制输出");
return "finalize";
}
console.log(` → 质量未达标,进入第 ${state.iterationCount + 1} 次优化`);
return "optimize";
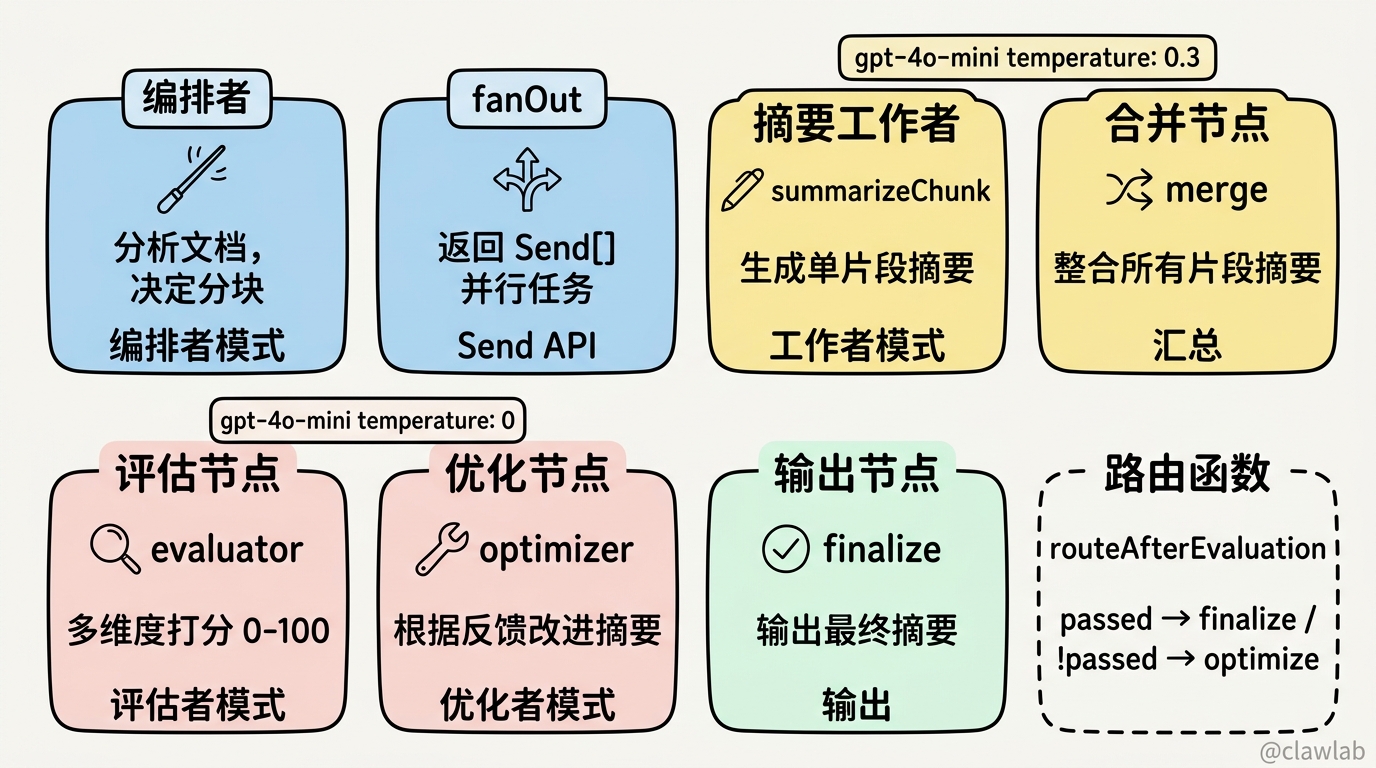
}💡 人话解读:
| 节点 | 模式 | 作用 |
|---|---|---|
orchestratorNode | 编排者 | 分析文档,决定如何分块 |
fanOutSummaryNode | Send API | 创建并行摘要任务 |
summarizeChunkNode | 工作者 | 生成单个片段的摘要 |
mergeNode | 汇总 | 合并所有片段摘要 |
evaluatorNode | 评估者 | 评估摘要质量 |
optimizerNode | 优化者 | 根据反馈改进摘要 |
finalizeNode | 输出 | 输出最终结果 |
第五步:构建图
src/graph.ts
typescript
import { StateGraph, START, END, MemorySaver } from "@langchain/langgraph";
import { SummarizerState } from "./state.js";
import {
orchestratorNode,
fanOutSummaryNode,
summarizeChunkNode,
mergeNode,
evaluatorNode,
optimizerNode,
finalizeNode,
routeAfterEvaluation,
} from "./nodes.js";
const graph = new StateGraph(SummarizerState)
.addNode("orchestrator", orchestratorNode)
.addNode("fanOutSummary", fanOutSummaryNode)
.addNode("summarizeChunk", summarizeChunkNode)
.addNode("merge", mergeNode)
.addNode("evaluator", evaluatorNode)
.addNode("optimizer", optimizerNode)
.addNode("finalize", finalizeNode)
.addEdge(START, "orchestrator")
.addEdge("orchestrator", "fanOutSummary")
.addEdge("summarizeChunk", "merge")
.addEdge("merge", "evaluator")
.addConditionalEdges("evaluator", routeAfterEvaluation, {
optimize: "optimizer",
finalize: "finalize",
})
.addEdge("optimizer", "fanOutSummary")
.addEdge("finalize", END);
const checkpointer = new MemorySaver();
export const docSummarizer = graph.compile({ checkpointer });💡 流程图:
START
│
▼
┌─────────────┐
│ orchestrator│ ← 分析文档,创建分块
└──────┬──────┘
│
▼
┌──────────────┐
│ fanOutSummary│ ← 返回 Send[]
└──────┬───────┘
│
┌──┴──┬──────┬──────┐
▼ ▼ ▼ ▼
┌──────┐┌──────┐┌──────┐┌──────┐
│Chunk0││Chunk1││Chunk2││ChunkN│ ← 并行摘要
└──┬───┘└──┬───┘└──┬───┘└──┬───┘
│ │ │ │
└───────┴───────┴───────┘
│
▼
┌───────────┐
│ merge │ ← 合并摘要
└─────┬─────┘
│
▼
┌───────────┐
│ evaluator │ ← 质量评估
└─────┬─────┘
│
┌───────┴───────┐
│ │
passed=true passed=false
│ │
▼ ▼
┌──────────┐ ┌───────────┐
│ finalize │ │ optimizer │ ← 优化改进
└────┬─────┘ └─────┬─────┘
│ │
▼ └──→ fanOutSummary(循环)
END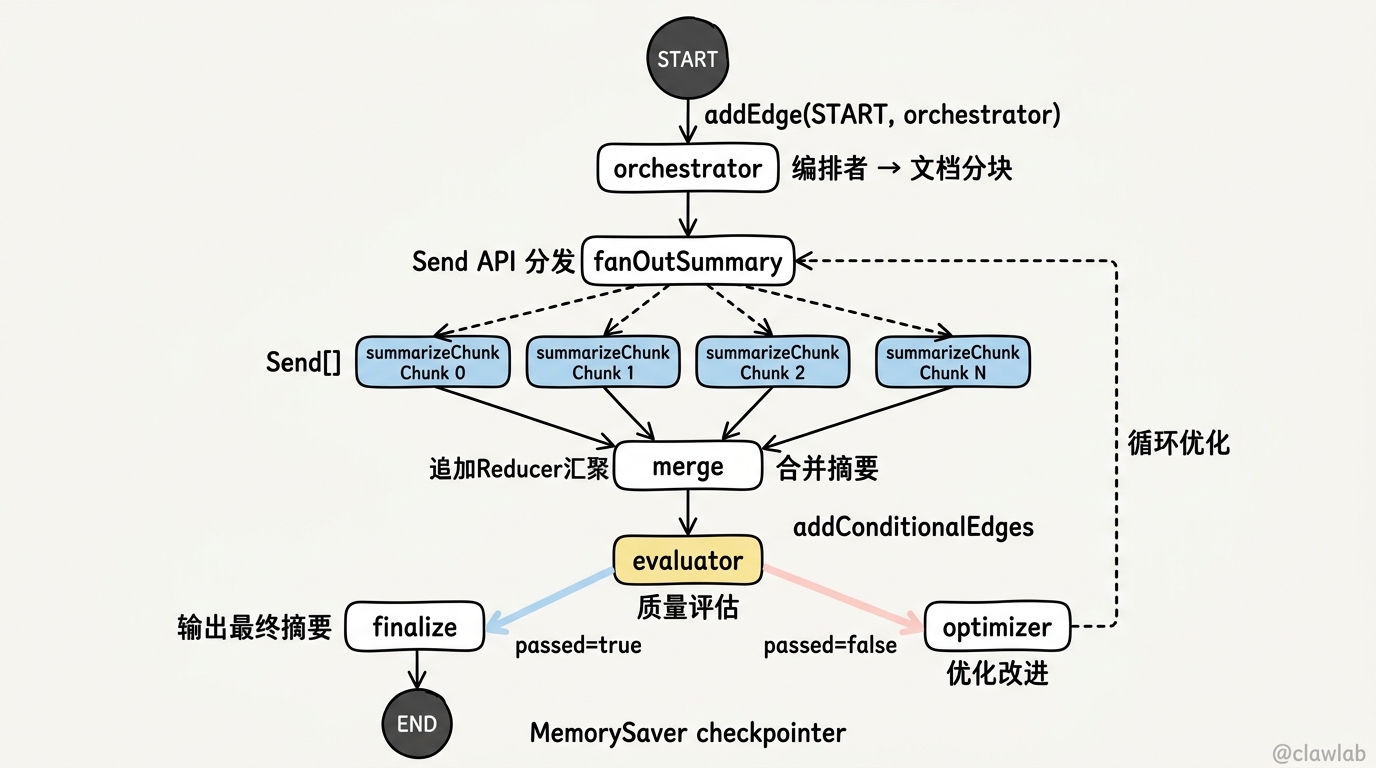
第六步:入口文件
src/index.ts
typescript
import { docSummarizer } from "./graph.js";
const sampleDocument = `
人工智能的发展历程
人工智能(Artificial Intelligence,简称AI)是计算机科学的一个分支,它致力于研究和开发能够模拟人类智能行为的系统。从1956年达特茅斯会议正式提出"人工智能"这一概念以来,这一领域经历了数次起伏。
早期发展(1956-1974)
这一时期被称为AI的"黄金时代"。研究者们充满乐观,认为完全模拟人类智能的机器很快就会实现。主要成就包括:通用问题求解器(GPS)的开发、LISP编程语言的创建,以及早期专家系统的尝试。然而,由于计算能力的限制和对问题复杂性的低估,这一时期的许多预言都未能实现。
第一次AI寒冬(1974-1980)
由于早期承诺未能兑现,AI研究经费大幅削减。批评者指出,AI系统只能处理"玩具问题",无法应对现实世界的复杂性。这一时期的困境推动了对知识表示和专家系统的深入研究。
专家系统时代(1980-1987)
专家系统的成功为AI带来了新的投资热潮。MYCIN、DENDRAL等系统在医学诊断和化学分析领域取得了令人瞩目的成果。日本提出的第五代计算机计划更是将这股热潮推向顶峰。
第二次AI寒冬(1987-1993)
专家系统的局限性逐渐暴露。它们难以维护、成本高昂,且只能处理狭窄领域的问题。随着个人电脑的普及和专用AI硬件市场的崩溃,AI再次进入低谷。
现代AI复兴(1993至今)
互联网的兴起带来了海量数据,计算能力的提升使深度学习成为可能。2012年,深度学习在ImageNet竞赛中大放异彩,标志着AI新时代的到来。此后,AI在图像识别、自然语言处理、游戏、自动驾驶等领域取得了突破性进展。
当前发展与挑战
今天的AI技术已经深入日常生活。智能手机中的语音助手、推荐系统、人脸识别等都是AI的应用。然而,我们也面临着重要的挑战:AI的可解释性、公平性、隐私保护,以及对就业市场的影响等问题都需要认真对待。
大型语言模型(如GPT系列)的出现更是将AI推向了新的高度。这些模型展示了令人惊叹的自然语言理解和生成能力,但同时也引发了关于AI安全、虚假信息和知识产权等方面的讨论。
未来展望
人工智能的未来充满可能性。从通用人工智能(AGI)的探索,到AI与其他技术(如量子计算、脑机接口)的融合,再到AI在气候变化、医疗健康、科学发现等领域的应用,AI正在重塑我们的世界。
然而,技术的发展必须与伦理考量相平衡。确保AI的发展造福全人类,避免其被滥用,是我们这一代人的重要责任。
`;
async function runDocSummarizer() {
console.log("═".repeat(60));
console.log("📄 文档摘要工作流");
console.log("═".repeat(60));
const config = {
configurable: {
thread_id: `summary-${Date.now()}`,
},
};
console.log(`\n📋 输入文档: ${sampleDocument.length} 字符`);
const startTime = Date.now();
const result = await docSummarizer.invoke(
{
document: sampleDocument,
targetLength: 300,
maxIterations: 3,
},
config
);
const totalTime = Date.now() - startTime;
console.log("\n" + "═".repeat(60));
console.log("📊 处理结果");
console.log("═".repeat(60));
console.log(`\n📈 统计信息:`);
console.log(` 原文长度: ${sampleDocument.length} 字符`);
console.log(` 摘要长度: ${result.finalSummary?.length || 0} 字符`);
console.log(` 压缩比: ${((result.finalSummary?.length || 0) / sampleDocument.length * 100).toFixed(1)}%`);
console.log(` 分块数量: ${result.chunks?.length || 0}`);
console.log(` 迭代次数: ${result.iterationCount}`);
console.log(` 处理耗时: ${totalTime}ms`);
if (result.evaluation) {
console.log(`\n📊 质量评估:`);
console.log(` 评分: ${result.evaluation.score}/100`);
console.log(` 状态: ${result.evaluation.passed ? "✅ 通过" : "❌ 未通过"}`);
console.log(` 反馈: ${result.evaluation.feedback}`);
}
console.log("\n" + "─".repeat(60));
console.log("📝 最终摘要:");
console.log("─".repeat(60));
console.log(result.finalSummary);
console.log("─".repeat(60));
if (result.chunkSummaries && result.chunkSummaries.length > 0) {
console.log("\n📦 片段摘要详情:");
result.chunkSummaries.forEach((cs: any) => {
console.log(`\n [Chunk ${cs.chunkId}] (${cs.wordCount} 字)`);
console.log(` ${cs.summary.slice(0, 100)}...`);
if (cs.keyPoints?.length > 0) {
console.log(` 要点: ${cs.keyPoints.slice(0, 3).join("; ")}`);
}
});
}
console.log("\n" + "═".repeat(60));
return result;
}
runDocSummarizer().catch(console.error);第七步:运行测试
bash
npm install
npm run dev预期输出
════════════════════════════════════════════════════════════
📄 文档摘要工作流
════════════════════════════════════════════════════════════
📋 输入文档: 1856 字符
🎯 编排者节点: 分析文档并分块
📄 文档长度: 1856 字符
📦 分块数量: 2
📤 分发 2 个摘要任务
→ Chunk 0 (1024 字符)
→ Chunk 1 (832 字符)
🔄 [Chunk 0] 生成摘要...
🔄 [Chunk 1] 生成摘要...
✅ [Chunk 0] 完成
✅ [Chunk 1] 完成
📥 合并节点: 汇总所有片段摘要
📝 生成合并摘要 (312 字符)
🔍 评估节点: 评估摘要质量
📊 评分: 82/100
✅ 通过: 摘要完整覆盖了文档主要内容,逻辑清晰
→ 质量通过,输出最终结果
✅ 完成节点: 输出最终摘要
════════════════════════════════════════════════════════════
📊 处理结果
════════════════════════════════════════════════════════════
📈 统计信息:
原文长度: 1856 字符
摘要长度: 312 字符
压缩比: 16.8%
分块数量: 2
迭代次数: 1
处理耗时: 4523ms
📊 质量评估:
评分: 82/100
状态: ✅ 通过
反馈: 摘要完整覆盖了文档主要内容,逻辑清晰
────────────────────────────────────────────────────────────
📝 最终摘要:
────────────────────────────────────────────────────────────
人工智能自1956年提出以来经历了多次起伏:早期黄金时代(1956-1974)取得GPS和LISP等成就,
随后经历两次寒冬。专家系统时代(1980-1987)带来短暂繁荣。现代AI复兴始于2012年深度学习
突破,如今广泛应用于语音助手、图像识别等领域。大型语言模型的出现将AI推向新高度,同时
也带来安全、伦理等挑战。未来AI将继续发展,但需平衡技术进步与伦理考量。
────────────────────────────────────────────────────────────
📦 片段摘要详情:
[Chunk 0] (156 字)
人工智能自1956年达特茅斯会议提出以来,经历了黄金时代、两次寒冬、专家系统时代等阶段...
要点: AI经历多次起伏; 早期因计算能力限制受阻; 专家系统时代带来短暂繁荣
[Chunk 1] (148 字)
现代AI复兴始于深度学习突破,在图像识别、自然语言处理等领域取得重大进展...
要点: 深度学习推动AI复兴; 大型语言模型展示强大能力; 技术发展需与伦理平衡
════════════════════════════════════════════════════════════进阶功能:流式输出进度
修改 src/index.ts(流式版本)
typescript
async function runWithStreaming() {
console.log("═".repeat(60));
console.log("📄 文档摘要工作流(流式输出)");
console.log("═".repeat(60));
const config = {
configurable: {
thread_id: `summary-${Date.now()}`,
},
};
const stream = await docSummarizer.stream(
{
document: sampleDocument,
targetLength: 300,
maxIterations: 3,
},
{ ...config, streamMode: "updates" }
);
console.log("\n📡 实时进度:\n");
for await (const update of stream) {
const [nodeName, nodeOutput] = Object.entries(update)[0];
switch (nodeName) {
case "orchestrator":
console.log(`🎯 分块完成: ${nodeOutput.chunks?.length} 个片段`);
break;
case "summarizeChunk":
const cs = nodeOutput.chunkSummaries?.[0];
if (cs) {
console.log(`✅ Chunk ${cs.chunkId} 摘要完成 (${cs.wordCount} 字)`);
}
break;
case "merge":
console.log(`📥 合并完成: ${nodeOutput.mergedSummary?.length} 字符`);
break;
case "evaluator":
const ev = nodeOutput.evaluation;
console.log(`🔍 评估完成: ${ev?.score}/100 ${ev?.passed ? "✅" : "❌"}`);
break;
case "optimizer":
console.log(`🔧 优化完成: ${nodeOutput.mergedSummary?.length} 字符`);
break;
case "finalize":
console.log(`\n✅ 最终摘要:\n${nodeOutput.finalSummary}`);
break;
}
}
}编排者-工作者模式详解
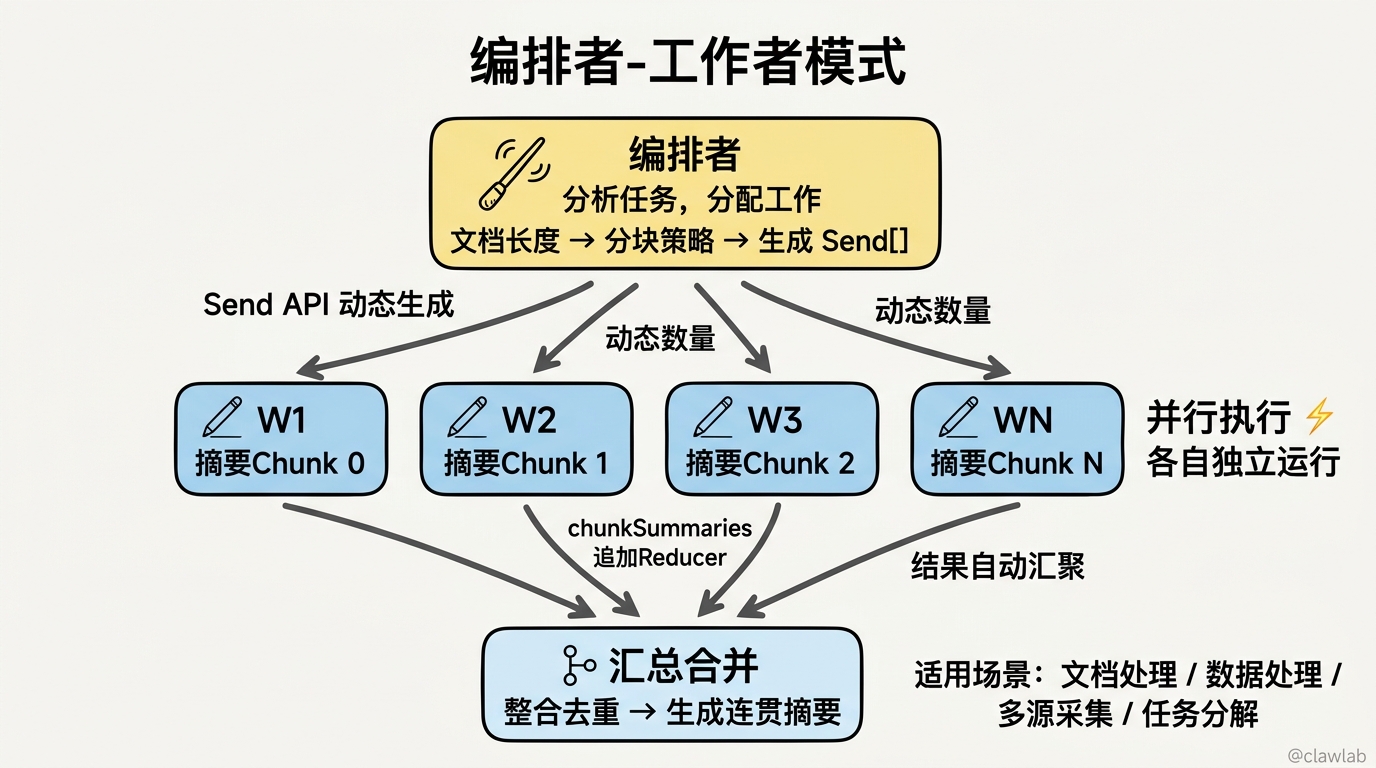
模式对比
┌─────────────────────────────────────────────────────────────┐
│ 编排者-工作者模式 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────┐ │
│ │ 编排者 │ ← 分析任务,分配工作 │
│ └─────┬──────┘ │
│ │ │
│ ┌──────┼──────┬──────┐ │
│ ▼ ▼ ▼ ▼ │
│ ┌────┐┌────┐┌────┐┌────┐ │
│ │W1 ││W2 ││W3 ││WN │ ← 工作者(并行执行) │
│ └──┬─┘└──┬─┘└──┬─┘└──┬─┘ │
│ │ │ │ │ │
│ └─────┴─────┴─────┘ │
│ │ │
│ ▼ │
│ ┌────────────┐ │
│ │ 汇总节点 │ ← 合并所有结果 │
│ └────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘适用场景
| 场景 | 说明 |
|---|---|
| 文档处理 | 将长文档分块并行处理 |
| 数据处理 | 批量数据的并行转换 |
| 多源采集 | 从多个来源并行获取数据 |
| 任务分解 | 将复杂任务拆分为独立子任务 |
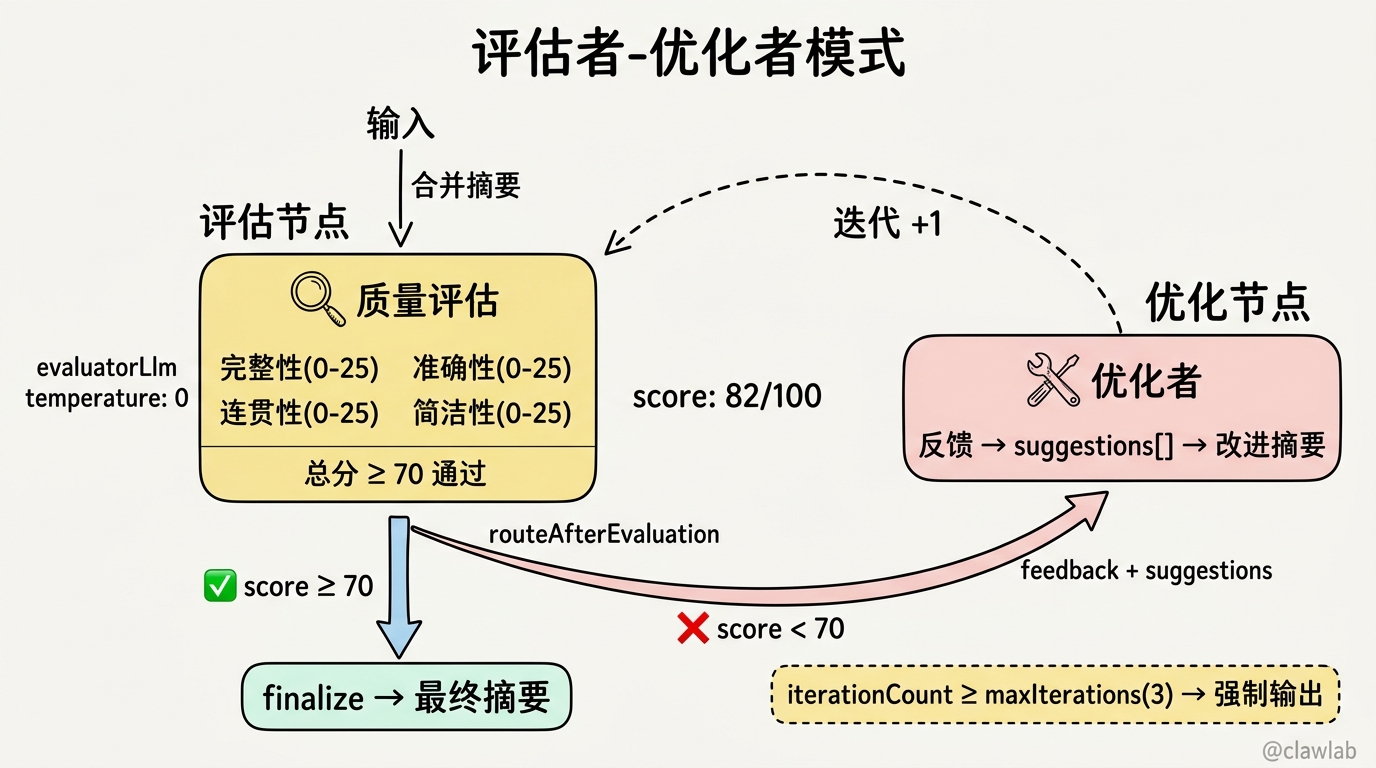
评估者-优化者模式详解
模式对比
┌─────────────────────────────────────────────────────────────┐
│ 评估者-优化者模式 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────┐ │
│ │ 生成结果 │ │
│ └─────┬──────┘ │
│ │ │
│ ▼ │
│ ┌────────────┐ │
│ │ 评估节点 │ ← 评估结果质量 │
│ └─────┬──────┘ │
│ │ │
│ ┌─────┴─────┐ │
│ │ │ │
│ 通过 ✅ 未通过 ❌ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────┐ ┌──────────┐ │
│ │ 输出 │ │ 优化节点 │ ← 根据反馈改进 │
│ └──────┘ └────┬─────┘ │
│ │ │
│ └──────→ 评估节点(循环直到通过) │
│ │
└─────────────────────────────────────────────────────────────┘关键代码
typescript
function routeAfterEvaluation(state: SummarizerStateType): string {
if (state.evaluation?.passed) {
return "finalize";
}
if (state.iterationCount >= state.maxIterations) {
return "finalize";
}
return "optimize";
}
项目总结
核心实现
| 功能 | 实现方式 |
|---|---|
| 文档分块 | 按字符数 + 重叠切分 |
| 并行摘要 | Send API + 追加 Reducer |
| 摘要合并 | LLM 整合多片段摘要 |
| 质量评估 | LLM 多维度打分 |
| 迭代优化 | 条件路由 + 循环 |
两种模式组合
编排者-工作者模式 评估者-优化者模式
│ │
│ │
▼ ▼
┌───────────────────────────────────────────────┐
│ │
│ 编排 → 并行处理 → 合并 → 评估 → 优化 → ... │
│ │
└───────────────────────────────────────────────┘流程控制关键点
| 控制点 | 实现方式 |
|---|---|
| 并行分发 | fanOutNode 返回 Send[] |
| 结果汇聚 | Reducer 追加模式 |
| 质量门槛 | evaluator 评分 + 条件路由 |
| 迭代限制 | maxIterations 防止无限循环 |
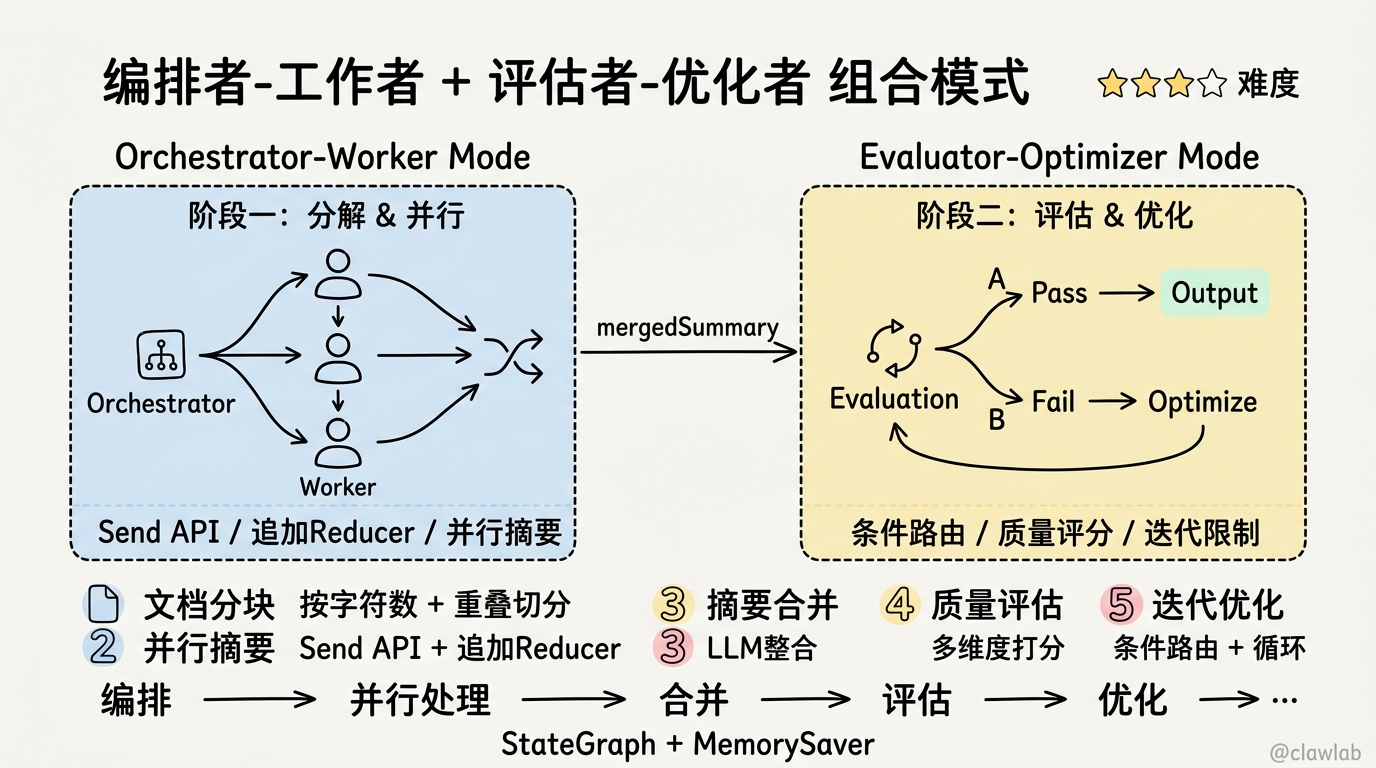
核心要点回顾
- 编排者-工作者模式 —— 编排者分析任务,工作者并行执行
- 评估者-优化者模式 —— 评估质量,不达标则循环优化
- Send API 动态并行 —— 根据分块数量动态创建并行任务
- 追加 Reducer 汇聚结果 —— 多个并行任务的结果自动合并
- 迭代限制防止死循环 ——
maxIterations是安全保障
下一步
继续学习下一个项目:自主研究 Agent,学习 Agent 模式和工具调用循环的实战应用。